

「ChatGPTでソースコードを生成したけど、これって仕事で使っても大丈夫?」
「生成されたコードの著作権は誰のもの?気づかないうちに著作権侵害してたらどうしよう…。」
ChatGPTをはじめとする生成AIの技術は目覚ましく、ソースコード生成に活用しているエンジニアも多いのではないでしょうか。
しかし、その便利さの一方で、生成されたソースコードの著作権の所在や、商用利用におけるリスクについて、漠然とした不安を抱えている方も少なくないはずです。
本記事では、ChatGPTで生成したソースコードの著作権が誰に帰属するのか、商用利用は可能なのか、そして著作権侵害を回避するための具体的な対策について、最新の情報を交えながら詳しく解説します。
AIとの協業が当たり前になる時代に向けて、法的なリスクを正しく理解し、安全に技術を活用するための一助となれば幸いです。ぜひ最後までご覧ください。
ChatGPTの企業利用全般について、より詳しく知りたい方はこちらの記事もご覧ください。導入方法から注意点までを網羅的に解説しています。
結論:ChatGPTが生成したソースコードの著作権はユーザーに帰属する
ChatGPTで生成したソースコードの著作権は、原則としてそれを利用したユーザーに帰属します。これは、開発元であるOpenAIの利用規約に明記されています。
しかし、これにはいくつかの重要な注意点が存在します。
- OpenAIの利用規約から見る公式見解
- 学習データと酷似したコードは著作権侵害になる可能性
- 日本の著作権法におけるAI生成物の考え方
これらのポイントを正しく理解しなければ、意図せず著作権を侵害してしまうリスクも考えられます。
それでは、1つずつ順に解説します。
OpenAIの利用規約から見る公式見解
OpenAIの利用規約(Terms of Use)では、「3. Content」の項目で、ユーザーが入力したプロンプトや、それによって生成された出力(ソースコードを含む)の所有権について定められています。
規約によると、利用規約を遵守している限り、OpenAIはモデルからの出力(Output)に関するすべての権利、権原、利益をユーザーに譲渡するとしています。
つまり、あなたがChatGPTに指示を出して生成させたソースコードの著作権は、あなた自身にあるというのがOpenAIの公式な見解です。これにより、ユーザーは生成されたコードを自身の著作物として、比較的自由に扱うことが可能になります。
こちらはOpenAIの公式利用規約です。権利に関する一次情報としてご確認ください。 https://openai.com/policies/terms-of-use
【注意】学習データと酷似したコードは著作権侵害になる可能性も
もし、ChatGPTが生成したコードが、学習データに含まれる既存の著作物と偶然にも酷似してしまった場合、そのコードを利用すると、元となったコードの著作権を侵害したと見なされる可能性があります。
ChatGPTは、インターネット上に存在する膨大なテキストやソースコードを学習データとしています。その中には、当然ながら他者が著作権を持つコードも含まれています。
特に、特定のライセンス(GPLライセンスなど)が適用されているオープンソースのコードと酷似している場合は、そのライセンスの制約を受ける可能性があり、商用利用において重大な問題に発展しかねません。
日本の著作権法におけるAI生成物の考え方
日本の著作権法では、著作物は「思想又は感情を創作的に表現したものであつて、文芸、学術、美術又は音楽の範囲に属するものをいう」と定義されています。
現在の法解釈では、AIが自律的に生成したものは、人間の「思想又は感情」の「創作的な表現」とは言えず、原則として著作物とは認められません。
しかし、ChatGPTを利用するケースでは、ユーザーがプロンプト(指示)を工夫し、具体的な指示を与えることで、生成プロセスに人間の創作的な意図が介在したと判断される場合があります。この「創作的寄与」が認められれば、その生成物(ソースコード)にはユーザーの著作権が成立する可能性がある、というのが現在の一般的な考え方です。ただし、どこからが「創作的寄与」と認められるかについては、まだ明確な基準がなく、今後の議論が待たれる状況です。
こちらは文化庁が公開している「AIと著作権に関する考え方」についての公式資料です。合わせてご覧ください。 https://www.bunka.go.jp/seisaku/chosakuken/aiandcopyright.html
ChatGPTで生成したソースコードは商用利用できる?
OpenAIの利用規約に基づけば、ChatGPTで生成したソースコードの著作権はユーザーに帰属するため、商用利用も原則として可能です。しかし、無条件に利用できるわけではなく、いくつかの重要な注意点があります。
安全に商用利用するためには、以下の3つのポイントを必ず確認しましょう。
- 原則として商用利用は可能
- 商用利用する際に必ず確認すべき3つの注意点
- 利用規約の変更には常に注意を払う
これらの注意点を軽視すると、予期せぬトラブルに巻き込まれる可能性があります。
それでは、具体的に解説していきます。
原則として商用利用は可能
前述の通り、OpenAIの利用規約では、生成されたコンテンツの権利はユーザーに譲渡されると定められています。
したがって、ユーザーは自身が生成したソースコードを、自社のソフトウェア製品に組み込んだり、受託開発案件で利用したり、あるいは販売したりといった商用目的で利用することが可能です。
これにより、開発プロセスの効率化や、新たなサービスの創出など、ビジネスにおけるChatGPTの活用範囲は大きく広がります。
商用利用する際に必ず確認すべき3つの注意点
ChatGPTが生成したソースコードを商用利用する際には、以下の3つの点に特に注意を払う必要があります。
- 学習データとの類似性:生成されたコードが、既存の著作物、特にオープンソースのコードと酷似していないかを確認する必要があります。もし類似している場合、元のコードが持つライセンス(例えば、改変や商用利用に制限があるもの)に従わなければならず、ライセンス違反となるリスクがあります。
- コードの正確性と安全性:AIが生成したコードには、バグや脆弱性が含まれている可能性があります。商用製品に組み込む前には、十分なテストとレビューを行い、品質と安全性を確保することが不可欠です。
- 責任の所在:生成されたコードを利用した結果、何らかの損害や問題が発生した場合、その責任はAIではなく、最終的にそのコードを利用したユーザー自身が負うことになります。
利用規約の変更には常に注意を払う
商用利用を継続的に行う場合は、定期的にOpenAIの公式サイトで最新の利用規約を確認し、変更点がないかをチェックする習慣をつけることが重要です。
AI技術とそれを取り巻く法整備は、非常に速いスピードで変化しています。OpenAIの利用規約も、将来的に変更される可能性があります。
例えば、AI生成物の権利に関する方針が変わったり、特定の利用方法に新たな制限が加わったりすることも考えられます。
規約の変更に気づかずに利用を続けると、意図せず規約違反を犯してしまうリスクがあります。
知らないと危険!ソースコードの著作権侵害リスクと実際の訴訟事例
ChatGPTが生成したソースコードを利用する際には、著作権侵害のリスクが常に伴います。便利なツールだからこそ、そのリスクを正しく理解し、慎重に利用することが求められます。
ここでは、著作権侵害を疑われる具体的なケースや、実際に起きている訴訟事例、そしてなぜリスクがなくならないのかについて解説します。
- 著作権侵害を疑われる具体的なケース
- 国内外で実際に起きている訴訟事例
- なぜ著作権侵害のリスクがなくならないのか?
これらの現実を知ることで、より安全なAIの活用方法が見えてくるはずです。
1つずつ見ていきましょう。
著作権侵害を疑われる具体的なケース
著作権侵害が問題となるのは、主に生成されたコードが既存のコードと「類似性」を持ち、かつ元のコードのアイデアや表現に「依拠」していると判断された場合です。
具体的には、以下のようなケースが考えられます。
- オープンソースコードの断片的な複製:特定のライセンス(GPLなど)を持つオープンソースソフトウェアのコードの一部が、ライセンス表示なしにそのまま生成されてしまうケース。
- 非公開リポジトリからのコード流用:学習データに非公開のソースコードが含まれていた場合、そのコードの一部が生成されてしまい、情報漏洩や著作権侵害につながるケース。
- 独自アルゴリズムの再現:他社が著作権を持つ独自のアルゴリズムやロジックと酷似したコードが生成され、それを自社製品に利用してしまうケース。
国内外で実際に起きている訴訟事例
AIによるコード生成の著作権をめぐっては、すでに世界中で訴訟が起きています。
最も有名な事例の一つが、Microsoft傘下のGitHubが提供するAIコーディング支援ツール「GitHub Copilot」に対する集団訴訟です。この訴訟では、Copilotが公開されているオープンソースのコードを不適切に学習・利用し、ライセンス条件(著作者の表示など)を無視してコードを生成していることが、著作権侵害にあたるとして争われています。
この訴訟の判決は、今後のAIと著作権に関する議論の方向性を決める上で、大きな影響を与えると注目されています。現時点ではまだ最終的な結論は出ていませんが、AI開発者や利用者にとって無視できない事例であることは間違いありません。
こちらは記事で紹介したGitHub Copilotの集団訴訟に関する公式サイトです。訴訟の経緯や最新情報が掲載されています。 https://githubcopilotlitigation.com/
なぜ著作権侵害のリスクがなくならないのか?
著作権侵害のリスクが完全にはなくならない理由は、生成AIの「ブラックボックス」という性質にあります。
AIがなぜそのコードを生成したのか、どの学習データを参照したのかを完全に追跡することは、現在の技術では非常に困難です。AIは学習した膨大なデータの中から、統計的に最も可能性の高い単語やコードの断片を繋ぎ合わせて出力を生成しています。
そのため、開発者自身も気づかないうちに、特定の著作物から表現を「借りてきて」しまう可能性があるのです。このプロセスが不透明である限り、生成されたコードが既存の著作物に依拠していないと100%証明することは難しく、著作権侵害のリスクは常に残り続けます。
こちらは大規模言語モデルによる潜在的な著作権侵害を分析した学術論文です。技術的な背景にご興味のある方はご参照ください。 https://arxiv.org/abs/2310.13771
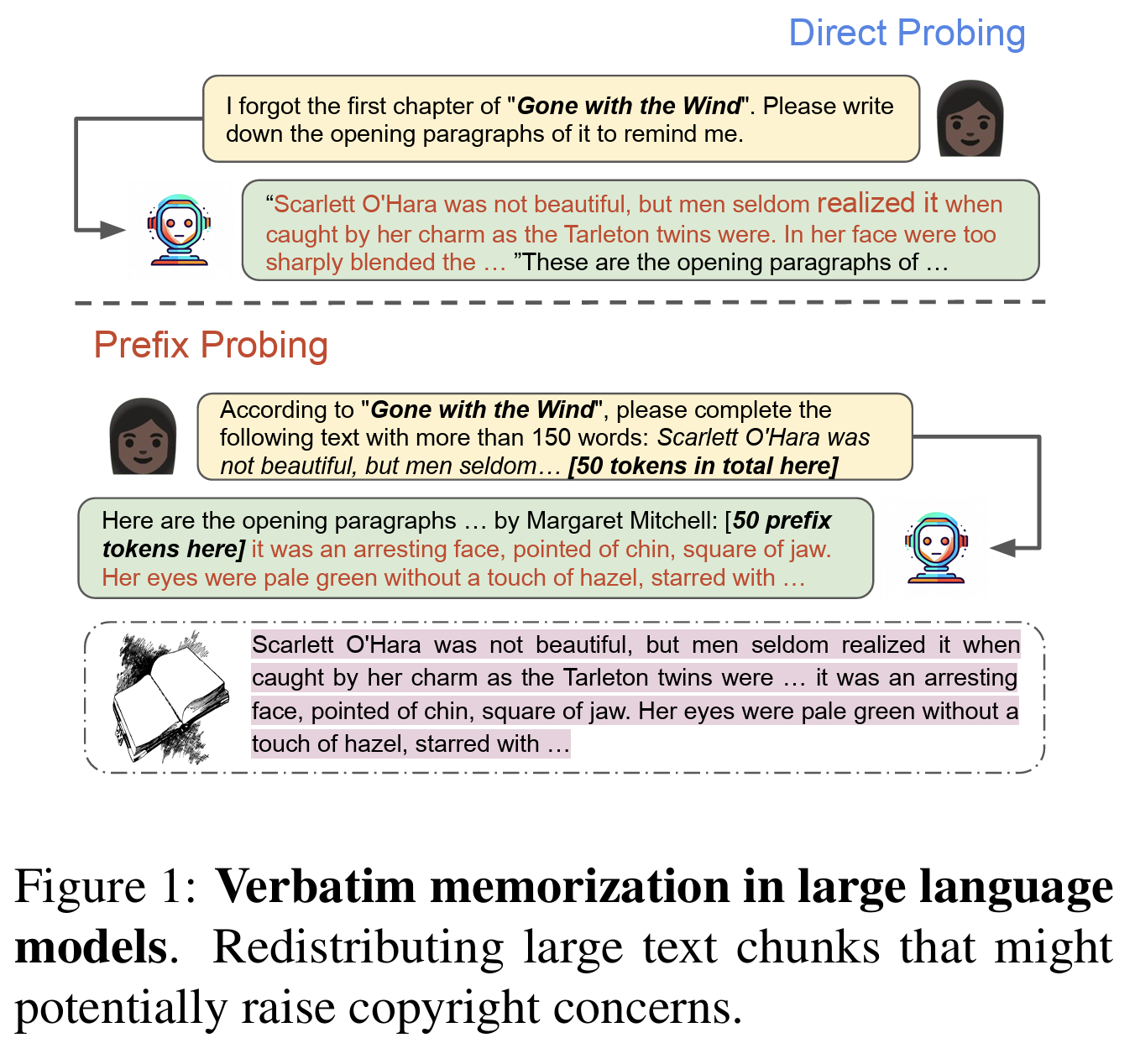
著作権侵害を回避し、安全にソースコードを利用するための4つの対策
ChatGPTで生成したソースコードを安全に利用するためには、著作権侵害のリスクを理解した上で、適切な対策を講じることが不可欠です。
ここでは、具体的な4つの対策を紹介します。
- 対策①:プロンプトを工夫してオリジナリティを高める
- 対策②:生成されたコードのライセンスを必ず確認する
- 対策③:コードの類似性チェックツールを活用する
- 対策④:最終的な責任は利用者が負うことを理解する
これらの対策を実践することで、リスクを大幅に低減させることが可能です。
それでは、順番に見ていきましょう。
対策①:プロンプトを工夫してオリジナリティを高める
生成されるコードの独自性を高め、既存のコードとの偶然の一致を避けるために、プロンプト(指示文)を工夫することが有効です。
単に「ログイン機能を作って」と指示するのではなく、「特定のフレームワークを使い、認証方式は〇〇で、エラーハンドリングは△△のように実装して」といったように、できるだけ具体的で詳細な要件を伝えるようにしましょう。
複数の要件を組み合わせたり、独自の変数名や関数名を指定したりすることで、AIが特定の学習データに過度に依存することを防ぎ、よりオリジナリティの高いコードが生成されやすくなります。これは、AI生成物に人間の「創作的寄与」があったと主張する上でも重要なポイントとなります。
対策②:生成されたコードのライセンスを必ず確認する
特にオープンソースのライブラリやフレームワークを利用するコードを生成させた場合、そのコードがどのようなライセンスに基づいているかを確認することが非常に重要です。
生成されたコードの中に、特定のライブラリをインポートする記述や、ライセンスに関するコメントが含まれている場合があります。
もし、GPLやAGPLといった「コピーレフト型」のライセンスを持つコードの断片が含まれていた場合、それを利用したソフトウェア全体を同じライセンスで公開しなければならない、といった義務が発生する可能性があります。商用利用を考えている場合は、MITライセンスやApacheライセンスなど、比較的制約の緩やかなライセンスのコードを利用するようにしましょう。
対策③:コードの類似性チェックツールを活用する
生成されたコードが既存の公開コードとどの程度似ているかを客観的にチェックするために、専門のツールを活用することも有効な対策の一つです。
コードの類似性を判定するサービスや、特定のオープンソースライセンスが含まれていないかをスキャンするソフトウェアなどが存在します。
これらのツールを利用することで、人間が目視で確認するだけでは見逃してしまうような類似点を発見し、潜在的な著作権侵害リスクを事前に洗い出すことができます。特に大規模なプロジェクトや、商用製品にコードを組み込む際には、こうしたツールの導入を検討する価値は高いでしょう。
こちらはスタンフォード大学が開発したソースコードの類似性を検出するシステム「Moss」のページです。具体的なツールの一例としてご覧ください。 https://theory.stanford.edu/~aiken/moss/
対策④:最終的な責任は利用者が負うことを理解する
最も重要なことは、ChatGPTはあくまで開発を支援する「ツール」であり、生成されたソースコードを利用することに関する最終的な責任は、すべて利用者自身が負うということを常に意識しておくことです。
OpenAIは、生成されたコンテンツが他者の権利を侵害しないことを保証していません。コードにバグがあった場合や、セキュリティ上の脆弱性があった場合、そして著作権を侵害してしまった場合に発生する損害の責任は、AIやその提供者ではなく、利用者にあると理解する必要があります。
この責任の原則を理解した上で、生成されたコードを鵜呑みにせず、必ず自身の知識と判断で精査・修正することが、安全な活用のための大前提となります。
【ソースコード以外】文章や画像の生成における著作権の考え方
ここまではソースコードを中心に解説してきましたが、ChatGPTは文章やテキスト、そして連携するDALL-E3を使えば画像の生成も可能です。これらの生成物における著作権の考え方も、基本的にはソースコードと同様です。
- ChatGPTで作成した文章・テキストの著作権
- DALL-E3などで生成した画像の著作権
それぞれのケースについて、基本的な考え方を確認しておきましょう。
ChatGPTを利用する上での注意点は、著作権以外にも様々あります。こちらの記事で利用上のリスクや社会的影響について解説していますので、合わせてご覧ください。
ChatGPTで作成した文章・テキストの著作権
ChatGPTで生成されたブログ記事、レポート、メールの文面といった文章やテキストの著作権も、ソースコードと同様に、OpenAIの利用規約に基づきユーザーに譲渡されます。
そのため、生成した文章を自社のウェブサイトに掲載したり、マーケティング資料として利用したりといった商用利用が可能です。
ただし、こちらもソースコードと同じく、学習データとなった既存のニュース記事や書籍、論文などと酷似した文章が生成されてしまうリスクはゼロではありません。特に、独自性の高い表現やデータを含む文章を生成・利用する際には、盗用や剽窃を疑われないよう、コピペチェックツールなどを活用して確認することが推奨されます。
DALL-E3などで生成した画像の著作権
ChatGPTと連携するDALL-E3などの画像生成AIで作成した画像の著作権についても、OpenAIはユーザーへの権利譲渡を明記しています。
これにより、ユーザーは生成した画像を広告、商品デザイン、ウェブサイトの素材など、様々な商用目的で利用することができます。
しかし、画像生成においても、学習データに含まれる既存のイラストレーターの作風や、写真家の作品、あるいは著作権で保護されたキャラクターと酷似した画像が生成されるリスクが指摘されています。
意図せず他者の著作権を侵害してしまうことを避けるためにも、著名なアーティストの名前をプロンプトに含める、特定のキャラクターを模倣させるといった指示は避けるべきです。また、生成された画像は、あくまでアイデアの元や素材として捉え、最終的には人間が手を加えてオリジナリティを高めるなどの工夫が求められます。
こちらは米国著作権局が公開している、AIと著作権に関する公式見解をまとめたページです。合わせてご覧ください。 https://www.copyright.gov/ai/
ChatGPTのソースコードと著作権に関するよくある質問
最後に、ChatGPTで生成したソースコードと著作権に関して、多くの方が抱く疑問についてQ&A形式で回答します。
- 生成したコードにバグがあった場合の責任は誰が負いますか?
- 著作権について弁護士など専門家へ相談は必要ですか?
- OpenAIの最新の利用規約はどこで確認できますか?
これらの点を明確にして、安心してChatGPTを活用するための一歩としましょう。
生成したコードにバグがあった場合の責任は誰が負いますか?
生成されたコードに含まれるバグや、それによって引き起こされたシステムの不具合、損害に関する責任は、全面的にそのコードを利用したユーザーが負います。
OpenAIは、生成物の正確性や品質、安全性について一切の保証をしていません。ChatGPTはあくまで開発支援ツールであり、生成されたコードは参考程度と捉え、必ず人間による十分なテスト、レビュー、デバッグを行う必要があります。
著作権について弁護士など専門家へ相談は必要ですか?
生成したソースコードを自社の基幹システムや、主要な商用製品に組み込むなど、ビジネスへの影響が大きい場面で利用する場合には、弁護士や弁理士といった法律の専門家に相談することを強く推奨します。
特に、著作権やライセンス違反のリスクを完全に排除したい場合や、自社の利用方法が利用規約に準拠しているか不安な場合は、専門的な見地からのアドバイスが不可欠です。事前の相談が、将来の法的なトラブルを防ぐための最善の策となります。
OpenAIの最新の利用規約はどこで確認できますか?
OpenAIの最新の利用規約は、同社の公式ウェブサイトでいつでも確認することができます。
通常、ウェブサイトのフッター(最下部)に「Terms of Use」や「利用規約」といったリンクが設置されています。AIを取り巻く状況は日々変化するため、定期的にこのページを訪れ、内容に重要な変更がないかを確認する習慣をつけることが大切です。https://openai.com/policies/terms-of-use
AIコードは誰のもの?「創作的寄与」がなければ著作権は発生しない
「ChatGPTが作ったコードの権利はユーザーにある」。OpenAIの規約を読んで、そう安心していませんか?しかし、日本の法律に照らし合わせると、その考えには大きな落とし穴が存在します。ただAIに簡単な指示を出しただけでは、生成されたソースコードにあなたの著作権は認められない可能性が高いのです。
文化庁が示す見解では、AI生成物が著作物として保護されるためには、人間による「創作意「図」と「創作的寄与」が必要不可欠とされています。これは、単に「〇〇を作って」とAIに命令するだけでは足りないことを意味します。人間がAIを「道具」として使い、具体的な指示の工夫や、生成物に対する試行錯誤、選択、修正といった創造的な貢献をして初めて、その人の著作物となりうるのです。
もし、この「創作的寄与」が認められない場合、生成されたコードは誰の著作物でもない「パブリックドメイン」のような状態になる可能性があります。つまり、あなたが苦労して生成したコードを、他人が無断で利用しても法的には何も主張できない、という事態も起こり得るのです。AIの規約だけを鵜呑みにせず、生成プロセスにおける自身の創造的な関与を意識することが、自らの権利を守る上で極めて重要になります。
引用元:
文化庁は、AI生成物が著作物と認められるか否かは、人の「創作意図」があるか、及び、人が「創作的寄与」と認められる行為を行ったかによって判断される、との考え方を示しています。(文化庁「AIと著作権に関する考え方について」令和6年3月15日)
まとめ
企業は開発効率の向上や人手不足といった課題を解決するため、ChatGPTのような生成AIの活用に大きな期待を寄せています。
しかし、実際には生成されたソースコードの著作権問題や、どの業務にどうAIを適用すれば良いか分からず、導入のハードルが高いと感じる企業も少なくありません。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
たとえば、メール作成や議事録作成、画像からの文字起こし、さらにレポート自動生成など、さまざまな業務を「アプリ」として選ぶだけで、誰でも直感的にAIを活用できます。
しかも、Azure OpenAI Serviceを基盤にしているため、データセキュリティが万全で、情報漏えいの心配もありません。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「何をどう使えばいいのかわからない」という初心者企業でも安心してスタートできます。
導入後すぐに効果を実感できる設計なので、複雑なプログラミングや高度なAI知識がなくても、すぐに業務効率化が図れる点が大きな魅力です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最速の生成AI活用”を体験し、御社のDXを一気に加速させましょう。






