

生成AIの技術が目覚ましい進化を遂げ、ChatGPTをはじめとする大規模言語モデル(LLM)がビジネスの現場でも急速に浸透しつつあります。多くの企業が業務効率化や新たな価値創造を目指し、その活用方法を模索する中で、一つの大きなテーマとして浮上しているのが「自社の社内データを生成AIに活用させること」です。
「社内の規定についてAIに質問できるようにしたい」「過去の膨大な事例から、最適なものをAIに探させたい」「営業提案書の下書きを、過去の資料を参考にAIに作らせたい」
――こうしたニーズは、多くのビジネスパーソンが抱く共通の願いではないでしょうか。
しかし、その具体的な方法論となると、多くの疑問や不安がつきまといます。「社内データをAIに渡して、情報が漏洩しないのか?」「そもそも、どうやってAIに自社の情報を教えればいいのか?」「導入してみたものの、期待したような回答が得られないのではないか?」
私が経営する、株式会社Bocekでは、セキュアな生成AIプラットフォーム「Taskhub」の運営や、法人向けの生成AI導入コンサルティングを手掛けております。日々、多くのお客様から寄せられるご相談の中でも、この「社内データをAIに学習させる方法」は、最も関心が高く、同時に多くの誤解が生まれやすいテーマでもあります。
そこで今回の特集記事、この根源的な問いに真正面から向き合い、生成AIに社内データを活用させるための正しい知識、具体的な手法、そして成功に導くための実践的なノウハウを、網羅的に、そして深く掘り下げて解説していきます。
「AIの学習」は2つの意味で使われる

生成AIの学習に対する大きな誤解に対して説く沖村氏
「社内データをAIに学習させる」という言葉を聞いたとき、多くの方がまず懸念されるのが、「入力した機密情報や個人情報がAIモデルそのものに取り込まれ、他社のユーザーへの回答として使われてしまうのではないか」というセキュリティリスクでしょう。これは、AIの「学習」という言葉が持つ、ある種のイメージからくる非常に重要な懸念点です。
この懸念が指している「学習」は、AIモデルの根幹をなす膨大なデータセットに、入力されたデータを追加してモデル自体を更新する「再学習(トレーニング)」や「ファインチューニング」と呼ばれるプロセスを指します。もしこのような形でデータが利用されれば、確かに情報漏洩のリスクは計り知れません。
それでは、私たちが本記事でテーマとする「社内データを学習させる」とは、一体何を指すのでしょうか。それは、AI業界で 「RAG(ラグ)」 と呼ばれる技術を用いるアプローチのことです。RAGは「Retrieval-Augmented Generation」の略で、日本語では「検索拡張生成」と訳されます。
このRAGという仕組みにおいて、AIは情報を恒久的に「学習」して記憶するわけではありません。より正確に表現するならば、AIは与えられた質問に答えるために、その都度、許可された社内データ群を「参照」しているのです。
この「学習」と「参照」の違いを理解することが、社内データ活用への第一歩です。
RAGにおける「参照」は、皆さんが仕事で何かを調べるときに、社内のファイルサーバーやマニュアルを開いて必要な箇所を確認する行為に似ています。調べた内容が即座に皆さんの記憶と一体化するわけではないように、AIもまた、回答を生成するための一時的な情報源として社内データを利用するだけなのです。データがAIモデル自体に組み込まれることはないため、前述したようなモデルの再学習に伴う情報漏洩のリスクを根本的に回避できます。
企業が「社内AIを構築したい」と考えるとき、その技術的な実態のほとんどは、このRAGを指していると言っていいでしょう。ここからは、このRAGが具体的にどのような仕組みで動いているのかを、さらに詳しく解剖していきます。
RAG(検索拡張生成)の仕組みを徹底解剖
ここでは例として「新しく導入されたリモートワーク規定について、交通費の精算ルールを知りたい」という質問がユーザーから投げかけられたケースを想定してみましょう。
ステップ1:ユーザーからの質問(クエリ)の受付
すべては、ユーザーがチャットインターフェースなどに質問を入力することから始まります。
ユーザー: 「新しいリモートワーク規定について、交通費の精算ルールを教えてください。」
ステップ2:質問の意図解釈と検索クエリの生成
質問を受け取ったシステムは、まずその内容を大規模言語モデル(LLM)に渡し、ユーザーが何を知りたいのか、その意図を解釈させます。同時に、社内ナレッジベース(後述)から関連情報を見つけ出すための、最適な「検索キーワード(検索クエリ)」をLLM自身に考えさせます。
この時、LLMは単に単語を抜き出すだけではありません。「新しいリモートワーク規定」「交通費」「精算ルール」といった要素を組み合わせ、意味的に関連性の高い情報を引き出せるような、複数の検索クエリを内部的に生成します。例えば、「リモートワーク 交通費 精算」「在宅勤務 通勤手当 規定」「出社日 交通費 実費精算」といった具合です。
ステップ3:ベクトル検索による高速な情報検索(Retrieval)
次に、RAGシステムの核ともいえる「検索(Retrieval)」のフェーズに移ります。ここで登場するのが、「ベクトルデータベース」という特殊なデータベースです。
このプロセスを理解するためには、事前の準備について少し説明が必要です。RAGシステムを構築する際、企業はあらかじめ、AIに参照させたい社内ドキュメント(社内規定、マニュアル、過去の議事録、事例集など)をすべてシステムに登録しておきます。
システムは登録されたドキュTキュメントを、意味のあるまとまり(段落など)ごとに細かく「チャンク」と呼ばれる単位に分割します。そして、それぞれのチャンクの内容を、AIが理解できる数値の羅列、すなわち「ベクトル」に変換します。このベクトル化により、単語の文字列としてではなく、「意味」として情報を捉えることが可能になります。
この準備が整ったベクトルデータベースに対して、ステップ2で生成した検索クエリを投げかけます。データベースは、キーワードの一致不一致を見るのではなく、質問クエリの「意味ベクトル」と、保存されている全チャンクの「意味ベクトル」との近さを計算します。これにより、たとえ使われている単語が少し違っていても、意味的に最も関連性の高いドキュメントの断片(チャンク)を、瞬時に、かつ高い精度で複数見つけ出すことができるのです。
今回の例では、「リモートワーク規定.pdf」の中から交通費の精算に関する記述がある部分や、経費精算システムの利用マニュアルの一部などが、関連情報としてピックアップされるでしょう。
ステップ4:文脈に基づいた回答の生成(Generation)
最後のステップは「生成(Generation)」です。システムは、ステップ3で検索・取得した関連性の高いドキュメントの断片(これを「コンテキスト」と呼びます)と、ユーザーからの元の質問を組み合わせ、一つの命令文(プロンプト)として再度LLMに渡します。
そのプロンプトは、内部的に以下のような構造になっています。
# 命令 あなたは〇〇社の優秀なアシスタントです。以下の『参考情報』を基にして、ユーザーからの『質問』に、誠実かつ正確に回答してください。参考情報に記載のないことは、憶測で答えてはいけません。 # 参考情報 {ステップ3でベクトル検索によって取得したドキュメントの断片(チャンク)がここに挿入される} # 質問 {ユーザーが最初に入力した質問がここに挿入される}
このプロンプトを受け取ったLLMは、まるで参考書を片手にテストに臨む学生のように、与えられた「参考情報」の中から答えを探し出し、自然で分かりやすい文章にまとめてユーザーに提示します。
AIの回答: 「新しいリモートワーク規定における交通費の精算ルールですね。社内規定によりますと、原則としてリモートワーク日の通勤交通費は支給されませんが、業務命令による出社や、事前承認を得た上での出社については、実費での精算が可能です。精算の際は、経費精算システム『〇〇』より、訪問先を本社として申請を行ってください。」
このように、RAGは「検索」と「生成」という2つの能力を組み合わせることで、AIが元々持っていなかったはずの、企業固有で最新の情報に基づいた正確な回答を実現しているのです。この一連の流れを視覚的にまとめると、以下のようになります。
| フェーズ | ステップ | 処理内容 | 担当 |
|---|---|---|---|
| 入力 | 1. 質問受付 | ユーザーがインターフェースに質問を入力する。 | ユーザー |
| 検索 (Retrieval) | 2. 意図解釈・クエリ生成 | LLMが質問の意図を理解し、検索用のキーワードを生成する。 | LLM |
| 3. ベクトル検索 | ベクトルデータベースから、クエリと意味的に近い文書チャンクを検索・取得する。 | RAGシステム | |
| 生成 (Generation) | 4. 回答生成 | 元の質問と取得した文書(コンテキスト)を基に、LLMが最終的な回答文を作成する。 | LLM |
社内データ活用(RAG)がもたらす絶大なメリット
RAGの仕組みを理解したところで、次に、この技術を導入することが企業にどのような具体的な利益をもたらすのかを見ていきましょう。そのメリットは、単なる問い合わせ対応の効率化にとどまらず、組織全体の生産性を根底から引き上げるポテンシャルを秘めています。
最大のメリットは業務自動化の範囲を飛躍的に拡大させること
まず最大のメリットは「これまでAIには任せられなかった、より専門的で複雑な業務を自動化の対象にできる」点です。
標準的な生成AIは、インターネット上の一般的な知識しか持っていません。そのため、社内データという文脈(コンテキスト)なしにAIに任せられる業務は、ごく一部の一般的な文章作成やアイデア出しなどに限定されてしまいます。
しかし、実際のビジネスの現場を思い返してみてください。ある調査では、オフィスワーカーの業務時間のうち、実に4割から6割が、何らかの形で社内情報(過去の資料、データ、ノウハウ)を探したり、参照したりする時間に費やされているという結果も出ています。営業担当者が新しい提案書を作る際には、必ず過去の類似案件の提案書や成功事例を参照します。人事担当者が従業員の質問に答える際には、就業規則や内規を確認します。議事録を作成するにしても、会議中の発言だけでなく、参加者の役職や所属部署、過去の経緯といった社内情報が必要になります。
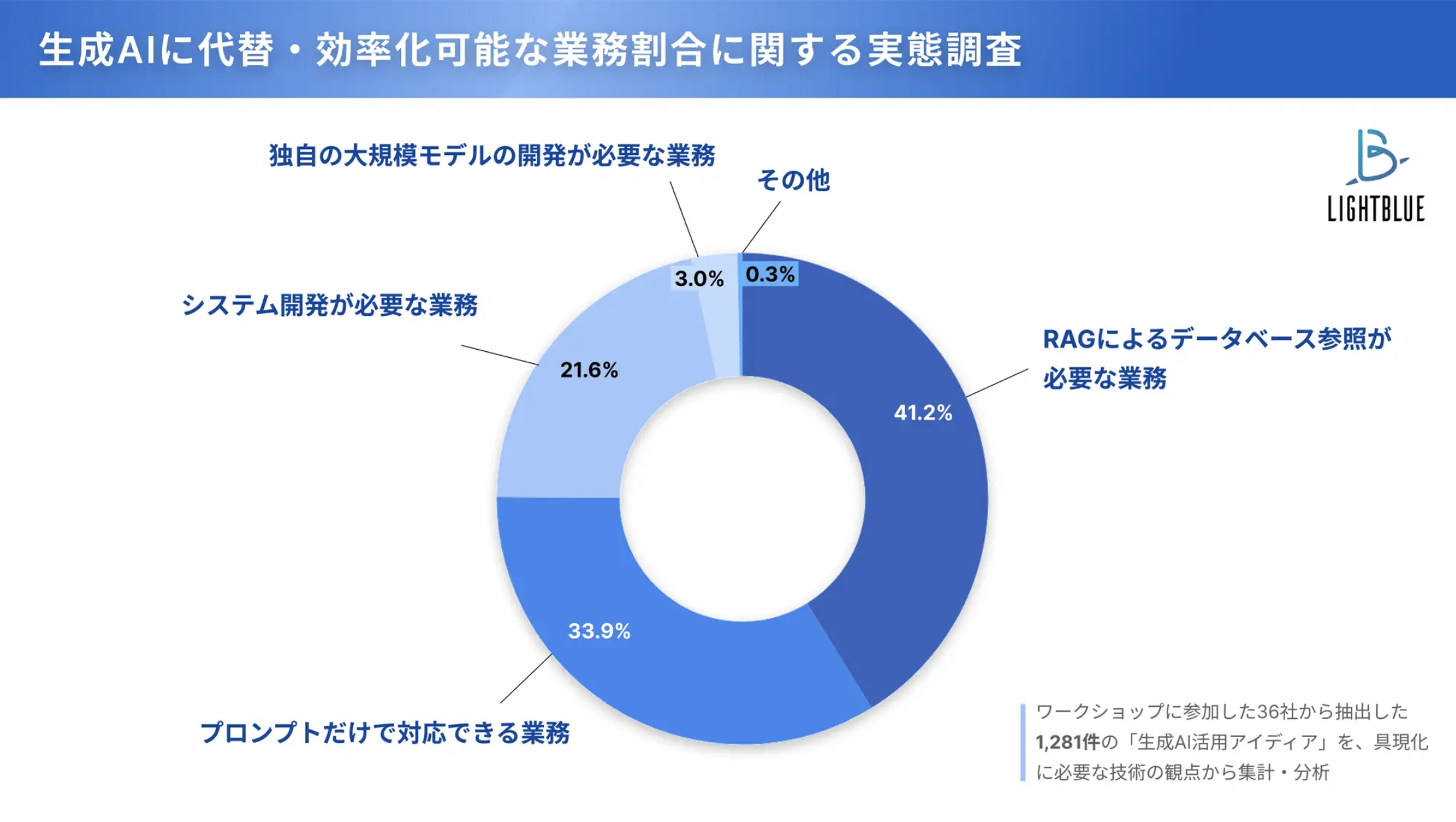
社内業務のうち、4割以上がRAGによるデータベース参照が必要だという調査結果も出ています。ー引用: Lightblue
つまり、私たちの仕事のほとんどは、ゼロベースで完結するのではなく、組織内に蓄積された知識やデータという土台の上になりたっているのです。
RAGは、この土台そのものをAIの能力と直結させる技術です。これにより、AIの活用範囲は劇的に広がります。
- 営業部門: 顧客の業界や課題を入力するだけで、過去の最も関連性の高い成功事例や提案書を基に、質の高い提案書のドラフトを数分で作成する。
- 人事・総務部門: 福利厚生、経費精算、各種申請手続きといった、頻繁だが定型的な問い合わせに24時間365日対応するチャットボットを構築し、担当者の負担を大幅に削減する。
- カスタマーサポート部門: 過去の問い合わせ履歴と回答、製品マニュアルをRAGに連携させることで、新人オペレーターでもベテラン並みの回答精度を実現し、顧客満足度を向上させる。
- 開発・技術部門: 膨大な量の過去の設計書、技術仕様書、バグ報告、社内Wikiを横断的に検索し、技術的な課題に対する解決策や類似コードを迅速に発見する。
このように、RAGを導入することは、AIを「一般的な知識を持つチャットボット」から、「自社のビジネスと業務に精通したアシスタント」に進化させるようなものです。
生成AIの知識の限界を突破させることができる
もう一つの重要なメリットは、標準的な生成AIが持つ根本的な弱点を補完できる点です。その弱点とは、主に「知識のカットオフ」と「情報の一般性」です。
- 知識のカットオフ: GPT-5.1のような最新モデルであっても、その知識はある特定の時点(カットオフデート)で固定されています。そのため、それ以降に発表された新製品の情報や、法改正、社内の組織変更といった最新の出来事については全く知りません。
- 情報の一般性: AIの知識は、インターネット上で公開されている膨大なテキストデータを学習した結果です。当然ながら、企業の内部にしか存在しない非公開情報、独自の業務プロセス、守秘義務のある顧客情報などについては、一切アクセスできません。
RAGは、これらの弱点に対する最も現実的かつ効果的なソリューションです。AIの内部知識に頼るのではなく、外部の、そして常に更新され続ける社内データベースをリアルタイムに参照するためです。
これにより、昨日更新されたばかりの社内規定に関する質問にも正確に答えられますし、競合他社には決して真似のできない、自社独自のノウハウに基づいた分析や提案も可能になります。RAGは、静的な知識しか持たないAIに、動的で生きた企業の知識を吹き込むための、不可欠な架け橋なのです。
導入前に知るべきデメリットとセキュリティリスク
RAGがもたらすメリットは計り知れませんが、その導入は決して簡単な道のりではありません。特に、企業の重要情報を取り扱う以上、事前に理解し、対策を講じておくべきデメリットやリスクが存在します。
セキュリティに関する考慮事項
社内データを活用する上で、セキュリティの確保は最優先課題です。RAGの仕組み自体は、データをAIモデルの再学習に使わないため安全性が高いと述べましたが、RAGシステムを構築・運用する過程で、新たなセキュリティのチェックポイントが生まれます。
特に、外部のクラウドサービス(SaaS)を利用してRAG環境を構築する場合、以下の点に細心の注意を払う必要があります。
- データの転送と保存: RAGを機能させるためには、社内ドキュメントを、利用するAIプラットフォームが稼働する外部のサーバーにアップロードし、保存する必要があります。このデータのアップロード時や、AIとの通信経路がSSL/TLSなどによって暗号化されているかは、最低限確認すべき必須項目です。
- 保存先の環境: データが保存されるクラウドサーバーが、どのようなセキュリティ基準を満たしているかを確認することが重要です。例えば、国際的な情報セキュリティ認証である「ISO 27001」や、クラウドサービスのセキュリティ評価基準である「SOC 2」などを取得しているか、データセンターは物理的にどこにあるのか、といった点です。自社のセキュリティポリシーと照らし合わせ、要求水準を満たすサービスを選定しなければなりません。
- アクセス制御: 最も重要なのが、アクセス権限の管理です。RAGシステムが、役職や所属部署に関係なく、すべての社内データにアクセスできてしまう状態は非常に危険です。例えば、一般社員が役員会議の議事録を閲覧できたり、A事業部の担当者がB事業部の未公開プロジェクト情報を参照できたりしてはなりません。導入するシステムが、既存のID管理システム(Azure ADなど)と連携し、ユーザーごとにアクセス可能な情報の範囲を厳密に制御できる機能を持っているかは、極めて重要な選定基準となります。
これらのリスクに対する解決策として、非常に高いセキュリティ要件を持つ企業向けには、外部のインターネットとは接続しない閉域網内でシステムを構築したり、自社のデータセンター内にすべての環境を構築する「オンプレミス」という選択肢も存在します。
ただし、これらは相応のコストと専門知識を要するため、多くのケースでは中堅〜大手企業の選択肢となります。
データ準備という最大の壁
そして、RAG導入におけるもう一つの、そしておそらく最大の障壁となるのが「データ」そのものの問題です。「参照すべき高品質なデータが、すぐに使える形で存在しなければ、RAGは全く機能しない」――これは、当たり前でありながら、多くの企業が見落としがちな事実です。
AIは、あくまで整理されたデータの中から適切な情報を探し出すのが得意なのであって、散乱した情報から精度の高い情報を引き出してくれるわけではありません。いわゆる「Garbage In, Garbage Out(ゴミを入れれば、ゴミしか出てこない)」の原則は、AIの世界でも健在です。
私たち株式会社Bocekがコンサルティングで支援させていただく中でも、多くの企業がこの「データ準備」のフェーズで壁にぶつかります。
- そもそもAIに参照させたい情報が、個人のPCやローカルサーバーに散在し、一元化されていない。
- データ形式がバラバラ(Word, Excel, PDF, テキスト, 画像…)で、統一的な処理が困難。
- ドキュメントは存在するが、内容が古かったり、誤りが含まれていたりして、品質が低い。
- 最も価値のあるノウハウが、特定の個人の頭の中にしかない「暗黙知」のままで、文書化されていない。
口で「データを学習させよう」と言うのは簡単ですが、その前段階として、この地道で膨大なデータ整備の作業が発生する可能性が高いことを、導入検討の初期段階で認識しておく必要があります。
効果的なデータ準備と管理の実践方法とは
では、この「データ準備」という巨大な壁を乗り越え、RAGを成功に導くためには、具体的に何をすべきなのでしょうか。ここでは、日本企業が直面しがちな課題と、その解決策を、実践的なロードマップとして提示します。
課題1:データの散在(サイロ化)を解消する
多くの企業では、情報が部署ごと、あるいは利用しているツールごとに孤立する「データのサイロ化」が起きています。営業部門の顧客情報はSalesforceに、開発部門の技術文書はConfluenceに、全社的な通達はSharePointに、そして各チームの議事録はGoogle Driveやファイルサーバーに…といった具合です。
この状態のままでは、AIは組織の知識を横断的に参照することができず、その価値は半減してしまいます。
解決策:
まず着手すべきは、AIに参照させたい情報の「棚卸し」です。どの情報が、どこに、どのような形式で保存されているかをリストアップし、全体像を把握します。
その上で、理想的には、これらの情報を一元的なデータリポジトリ(保管場所)に集約することが望ましいですが、現実的には大規模なデータ移行は困難な場合も多いでしょう。そこで有効なのが、Taskhubのように、様々なクラウドストレージ(Google Drive, SharePoint, Boxなど)と直接連携できるAIプラットフォームを選定することです。これにより、既存のデータ保管場所を大きく変更することなく、複数の情報源を仮想的に統合し、AIが横断的に検索できる環境を構築できます。
課題2:データの品質とフォーマットを整える
前述の通り、AIの回答品質は、インプットされるデータの品質に直結します。使えないデータ、質の低いデータをいくら集めても、賢いAIは生まれません。
解決策:
AIにとって「良いデータ」とは何かを理解し、それに合わせて既存のデータをクレンジング(浄化)し、新規作成するドキュメントのルールを定めることが重要です。
| データ種別 | 悪い例(Bad Practice) | 良い例(Good Practice) |
|---|---|---|
| 社内規定・マニュアル | 紙媒体をスキャンしただけの画像PDF(文字が選択できない)。手書きメモの写真。 | テキスト情報が埋め込まれたPDF。Word、PowerPoint、テキストファイル。文字としてコピー&ペーストできる状態が理想。 |
| フォルダ構造 | 「資料」のような曖昧なフォルダに、様々な種類のファイルが混在している。 | 「社内規定」「営業資料」「技術文書」のように目的別に整理されている。支社やグループ会社ごとに規則が異なる場合は、フォルダ階層で明確に分離されている。 |
| ファイル名 | 「20240615_打ち合わせ.docx」のような、作成者しか意味が分からないファイル名。 | 「[プロジェクトA][20240615][定例会議議事録]_[担当者名].docx」のように、命名規則が統一され、内容が推測できる。 |
特に重要なのは、PDFファイルの扱いです。紙をスキャナで取り込んだだけの「画像PDF」は、AIにとっては単なる一枚の絵に過ぎません。これではテキストを読み取ることができないため、OCR(光学的文字認識)という処理を挟む必要がありますが、読み取り精度に限界があり、誤った情報を参照する原因になります。可能な限り、作成元からテキスト情報を持ったPDFとして出力・保存する運用を徹底しましょう。
課題3:暗黙知を形式知に変換する
最も価値のある知識やノウハウは、しばしば文書化されず、ベテラン社員の頭の中に「暗黙知」として眠っています。これをAIが参照できる「形式知」(ドキュメント)に変換するプロセスは、RAG導入の成否を分ける重要な活動です。
解決策:
そのための最も効果的で始めやすい方法が、「Q&Aデータ」の作成です。
人事部や情報システム部など、社内からの問い合わせが多い部署では、日々同じような質問に繰り返し答えているケースが少なくありません。これらの過去の問い合わせと、それに対する正式な回答を一対のペアとしてExcelなどにまとめるのです。
| 質問 (Question) | 回答 (Answer) |
|---|---|
| 育児休業を取得したいのですが、どのような手続きが必要ですか? | 育児休業の取得には、原則として開始予定日の1ヶ月前までに「育児休業申出書」を人事部へ提出する必要があります。書式は社内ポータルの… |
| 新しいPCのセットアップ方法が分かりません。 | 新しいPCの初期セットアップについては、社内Wikiに詳細なマニュアルが掲載されています。こちらのリンクを参照してください:[リンク] |
このQ&A形式のファイルは、AIにとって非常に理解しやすく、価値の高いデータソースとなります。例えば、私たちが提供するTaskhubのチャット機能では、このQ&Aファイルさえあれば、アップロードするだけで即座に高精度な社内問い合わせチャットボットを構築できます。ある企業様での検証では、この手法だけで回答精度95%以上という高い結果を達成することができました。
同様に、営業部門の「事例データ」なども、構造化して蓄積することで絶大な効果を発揮します。「1事例につき1ファイル(またはExcelの1行)」といったルールを定め、[顧客名]、[業界]、[導入前の課題]、[提案内容]、[導入後の結果]といった項目を必ず記述するようにフォーマットを統一します。AIはこれらの構造化された情報から、ユーザーが求める条件に合致する事例を的確に見つけ出してくれます。
回答精度を極限まで高めるための、RAGチャットボットのUX設計
さて、最高のデータを用意したとしても、まだ完璧ではありません。RAGシステムの性能を最大限に引き出すためには、最後のピースとして「ユーザーの聞き方」、すなわちユーザーとAIとの対話の仕方を設計する必要があります。
ユーザーの曖昧な質問という罠
人間同士のコミュニケーションを思い浮かべてください。同僚から「あの件、どうなった?」と突然聞かれても、どの件なのか分からず困ってしまいますよね。「昨日の10時からのA社との打ち合わせの件で、議事録はいつまでに提出すればいいか教えて」と具体的に聞かれて初めて、的確に答えることができます。
これはAIとの対話でも全く同じです。「学校業界の過去の商談事例について教えて」とだけAIに質問しても、AIはどの学校種別(小・中・高・大?)の、どのような課題に関する事例を探せばよいのか判断できません。結果として、毎回同じような当たり障りのない一般的な事例を一つ提示する、といったことになりかねません。
この「ユーザー入力の曖昧さ」こそが、RAGを導入した企業が直面する「期待したほど賢くない」という失望の最大の原因なのです。
解決策1:入力インターフェースの工夫(フォーム化)
この課題に対する最も直接的で効果的な解決策が、入力インターフェースを工夫し、自由な質問文だけでなく、構造化されたフォームを用意することです。これは、私たちが最も推奨する方法でもあります。
曖昧な質問を許容するのではなく、AIが回答を生成するために最低限必要な情報を、ユーザーに体系的に入力させるのです。
フォーム項目例(社内事例検索の場合)
- 対象業界: [プルダウンメニューで選択:製造、金融、教育、医療…]
- 顧客の課題: [チェックボックスで複数選択:コスト削減、業務効率化、データ活用…]
- 顧客の従業員規模: [選択式:100名未満, 100-500名, 500名以上]
- その他キーワード: [自由記述欄]
このようにフォームを設計することで、ユーザーは自然な形で、AIが情報を絞り込むために必要なコンテキスト(文脈)を提供することになります。これにより、検索精度と回答の的確性は劇的に向上します。これは、AIを賢くするというより、「AIが賢く振る舞えるように、人間側がコミュニケーションの方法を最適化する」という発想の転換です。
解決策2:AIによる対話的な深掘り(エージェント的アプローチ)
もう一つの洗練された解決策は、AI自身にユーザーの意図を深掘りさせる、よりエージェント的なアプローチです。ユーザーからの曖昧な初期質問を受け取った際に、即座に答えを返すのではなく、まず確認や絞り込みのための質問をAIから返すように、あらかじめプロンプトを設計しておくのです。
対話フローの例
- ユーザー: 「学校業界の過去の商談事例について教えて。」
- AI (深掘り質問): 「かしこまりました。よりご要望に近い事例をお探しするために、いくつか質問させてください。まず、対象となる学校の種類はどれですか?(選択肢:小学校、中学校、高等学校、大学、専門学校)」
- ユーザー: 「高等学校です。」
- AI (深掘り質問): 「ありがとうございます。次に、どのような課題に関する事例にご興味がありますか?(選択肢:A. 生徒の学習データが分散している課題の解決、B. 校内のICT環境の整備、C. 保護者とのコミュニケーション円滑化)」
- ユーザー: 「B. ICT環境の整備について知りたいです。」
- AI (最終回答): 「承知いたしました。高等学校におけるICT環境の整備に関する過去の商談事例として、〇〇高校様のケースがございます。この事例では、全校生徒分のタブレット端末導入と、校内Wi-Fi網の刷新を支援し、授業でのICT活用率を50%向上させました。詳細な提案資料はこちらです:[リンク]」
この対話的なアプローチによって、ユーザーは自身の漠然としたニーズをAIとの対話を通じて明確化していくことができます。結果として、単に情報を検索するだけでなく、ユーザーの思考整理を助け、真に価値のあるインサイトへと導く、真の「アシスタント」としての役割をAIが果たせるようになるのです。
私たちBocekが開発・提供する「Taskhub」では、まさにこのようなフォームを使った入力支援機能や、AIが対話的に深掘りを行うエージェント機能の構築に力を入れており、お客様のRAGシステムの効果を最大化するための支援を行っています。
成功する社内AI活用の第一歩を踏み出そう
本記事では、「生成AIに社内データを学習させる方法」というテーマについて、その言葉の正しい意味から、中核技術であるRAGの仕組み、導入のメリット・デメリット、そして成功に不可欠なデータ準備や対話設計の具体的な方法論まで、包括的に解説してきました。
最後に、重要なポイントを改めて整理します。
- 「社内データの学習」の正体はRAG: 一般的に言われる「学習」は、AIモデルを再学習させることではなく、AIが必要な情報をその都度「参照」するRAG(検索拡張生成)という技術を指します。これにより、セキュリティを確保しつつ、企業固有の情報を活用できます。
- RAGは業務の可能性を広げる: RAGは、AIの知識の限界(カットオフ、一般性)を補い、業務の4~6割を占めるとされる社内データ活用業務の自動化を可能にする、極めて強力な手法です。
- 成功の鍵は「データ」と「対話」: RAG導入の成否は、技術そのものよりも、①参照させるデータの品質と管理(Garbage In, Garbage Out)、②ユーザーの曖昧な入力を解消する対話設計(フォーム化、深掘り質問)にかかっています。
- 地道な準備が大きな成果を生む: データの棚卸し、サイロ化の解消、フォーマットの統一、暗黙知の形式知化(Q&A作成など)といった地道な努力が、最終的にAIの回答精度とビジネスインパクトを決定づけます。
生成AIと社内データを連携させるプロジェクトは、決して魔法の杖を振るうような簡単なものではありません。しかし、本記事で解説したような正しい知識とアプローチに基づき、一つ一つのステップを丁寧に踏んでいけば、それは必ず組織に革命的な生産性向上と、新たな競争優位性をもたらすはずです。
まずは自社のデータが今どのような状態にあるか、その棚卸しから始めてみてはいかがでしょうか。それが、未来の働き方を創り出す、確かな第一歩となるはずです。






