

「ChatGPTを導入したけれど、一般的な回答しか得られず、業務に活かせない…」
「自社の情報やデータをChatGPTに学習させたいけど、何から始めればいいかわからない…」
こういった悩みを持っている方もいるのではないでしょうか?
本記事では、ChatGPTに社内データを学習させる具体的な方法5選と、それぞれのメリット・デメリット、さらには具体的な活用事例まで詳しく解説します。
自社の状況に合わせて最適な方法を選び、ChatGPTを真の業務効率化ツールとして活用するための知識を網羅的にご紹介します。
きっと役に立つと思いますので、ぜひ最後までご覧ください。
ChatGPTの基礎知識と社内データを学習させる必要性
ChatGPTを企業で最大限に活用するためには、その基本的な仕組みと、なぜ社内データの学習が不可欠なのかを理解することが重要です。
ここでは、ChatGPTが学習しているデータの範囲と限界、そして社内データを活用することの重要性について解説します。
そもそもChatGPTが学習しているデータの範囲と限界
ChatGPTは、インターネット上に公開されている膨大なテキストデータを基に学習しています。
そのため、一般的な知識や情報に関する質問には非常に高い精度で回答することができます。
しかし、その知識は2023年初頭までの情報で止まっており、最新の情報や、インターネット上に存在しない非公開の情報については回答できません。
特に、企業の内部情報、社内規定、独自のマニュアル、顧客データといった、企業の競争力の源泉となる情報には一切アクセスできないのが現状です。
企業でChatGPTの導入が進む背景と社内データ活用の重要性
多くの企業が業務効率化や生産性向上を目的として、ChatGPTの導入を進めています。
単純な情報収集や文章作成だけでなく、より高度な業務への活用が期待されています。
しかし、前述の通り、標準のChatGPTは社内情報にアクセスできません。
そのため、企業の独自の文脈や背景を理解した回答を生成することができず、その活用範囲は限定的になってしまいます。
この課題を解決し、ChatGPTを真に価値あるツールへと進化させる鍵が、社内データの活用なのです。
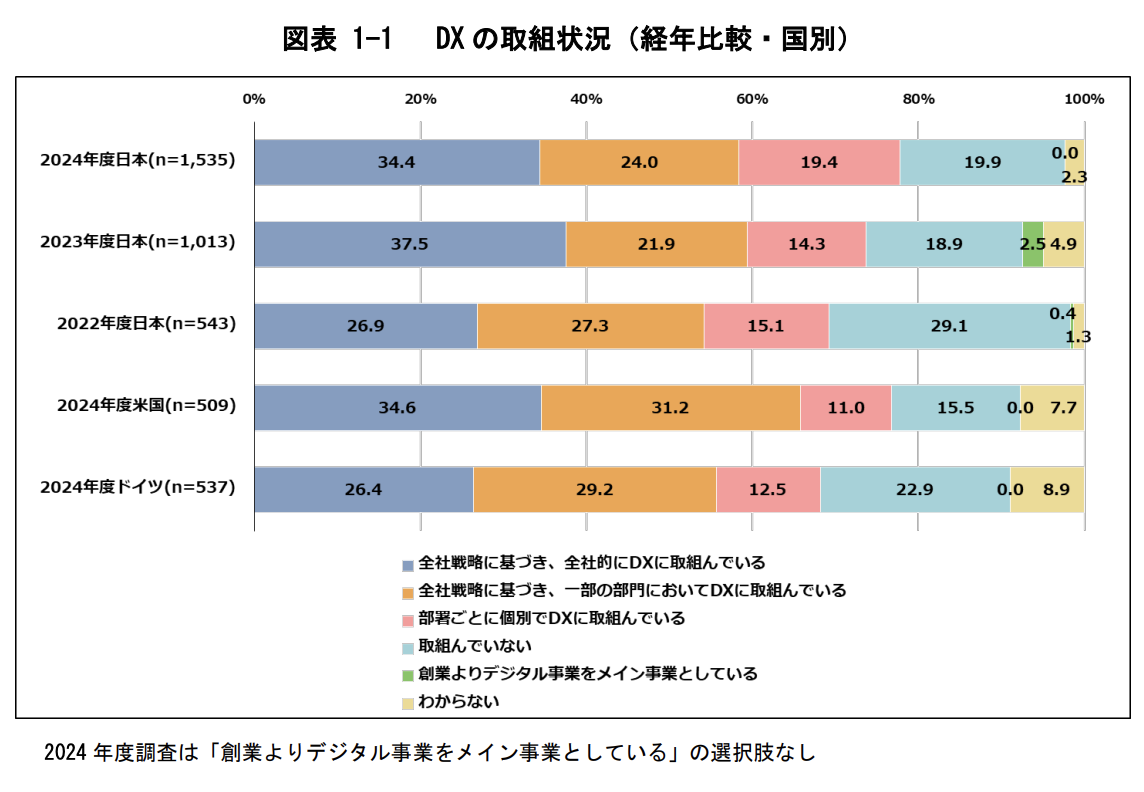
こちらは、独立行政法人情報処理推進機構(IPA)が発行した「DX白書2025」です。日本企業におけるDXやAI活用の最新動向がまとめられていますので、合わせてご覧ください。
https://www.ipa.go.jp/digital/chousa/dx-trend/tbl5kb0000001mn2-att/dx-trend-2025.pdf
なぜChatGPTは社内データ無しでは十分に活用されないのか
社内データを学習させていないChatGPTは、いわば「優秀な新人」のようなものです。
一般的な知識は豊富ですが、自社のルールや過去の経緯、専門用語といった固有のナレッジは全く知りません。
そのため、社内の問い合わせに「分かりません」と答えたり、見当違いな回答を生成したりしてしまいます。
これでは、従業員が求める情報を的確に提供できず、かえって業務の妨げになる可能性すらあります。
社内データを学習させることで、ChatGPTは「経験豊富なベテラン社員」へと成長し、業務に欠かせない存在となり得るのです。
ChatGPTに社内データを学習させる5つの主要な方法
ここからは、具体的にChatGPTへ社内データを学習させるための主要な方法を5つ紹介します。
- プロンプトエンジニアリング
- RAG(Retrieval-Augmented Generation)
- ファインチューニング
- OpenAI APIの活用
- ベクトルデータベースの活用
それぞれに特徴やメリット・デメリットがあるため、自社の目的や状況に合わせて最適な手法を選択することが重要です。
それでは、1つずつ順に解説します。
①プロンプトエンジニアリング:最も手軽な方法
プロンプトエンジニアリングは、ChatGPTに質問や指示(プロンプト)を与える際に、回答に必要な社内データを直接入力する方法です。
例えば、「以下の会議の議事録を要約してください:【議事録のテキストを貼り付け】」のように、プロンプト内にコンテキストとして情報を含めます。
特別な開発は不要で、誰でもすぐに試せる最も手軽な方法です。
しかし、プロンプトには文字数制限があり、一度に大量のデータを扱えない点や、毎回データを手動で入力する必要がある点がデメリットです。
また、Web版のChatGPTに機密情報を入力すると、情報漏洩のリスクがあるため注意が必要です。
こちらはChatGPTで業務効率化を実現するためのプロンプト集です。様々な業務に活用できる具体的なプロンプトを紹介していますので、合わせてご覧ください。 https://taskhub.jp/use-case/chatgpt-business-efficiency-prompt/
②RAG(Retrieval-Augmented Generation):ハルシネーションを抑制
RAGは、ユーザーからの質問に関連する社内データを検索し、その検索結果を基にChatGPTが回答を生成する仕組みです。
「検索(Retrieval)」と「生成(Generation)」を組み合わせることで、ChatGPTが知らない情報についても、根拠を持って回答できるようになります。
この方法の最大のメリットは、ChatGPTが嘘の情報を生成する「ハルシネーション」を大幅に抑制できる点です。
社内データという明確な根拠に基づいて回答するため、情報の正確性が格段に向上します。
多くの企業で採用されている、現在主流とも言える手法です。
③ファインチューニング:モデルを特定の業務に特化
ファインチューニングは、特定の業務データや会話データを追加で学習させ、ChatGPTのモデル自体を自社専用にカスタマイズする方法です。
これにより、業界特有の専門用語や、自社独自の言い回し、特定の回答スタイルなどをモデルに覚え込ませることができます。
例えば、カスタマーサポートの過去の応対履歴を学習させることで、より自然で質の高い回答を自動生成するAIを開発できます。
ただし、高品質な学習データを大量に用意する必要があり、導入には専門的な知識とコストがかかる点がデメリットです。
④OpenAI APIの活用:セキュアな環境で連携
OpenAI APIは、自社開発のアプリケーションやシステムにChatGPTの機能を組み込むためのプログラムインターフェースです。
APIを利用することで、入力したデータがOpenAIのモデル学習に使われないため、セキュリティを確保しながらChatGPTを活用できます。
社内チャットツールと連携させたり、独自の業務システムにAI機能を搭載したりと、柔軟な開発が可能です。
RAGやベクトルデータベースと組み合わせて利用されることが多く、セキュアな社内AI環境を構築する上で中核となる技術です。
⑤ベクトルデータベースの活用:膨大な社内データを高速検索
ベクトルデータベースは、テキストや画像などのデータを「ベクトル」と呼ばれる数値の集まりに変換して格納するデータベースです。
これにより、単なるキーワード検索ではなく、意味の近さや関連性に基づいた高速な検索が可能になります。
RAGの仕組みと組み合わせることで、膨大な量の社内マニュアルや過去の資料の中から、ユーザーの質問の意図に最も近い情報を瞬時に探し出すことができます。
大規模なナレッジデータベースを扱う際に、検索精度と速度を向上させるために不可欠な技術です。
【悩み別】ChatGPTへの社内データ学習方法の最適な選び方
ここまで5つの方法を紹介しましたが、「自社にはどれが合っているのか分からない」と感じる方もいるでしょう。
ここでは、企業が抱える悩みや目的に応じて、どの学習方法が最適なのかを解説します。
情報漏洩リスクを最優先で回避したい場合
情報漏洩リスクを最も重視するなら、OpenAI APIの利用が必須です。
特に、マイクロソフトが提供するAzure OpenAI Serviceは、閉域網接続が可能で、よりセキュアな環境を構築できるため多くの企業に選ばれています。
このセキュアな環境を基盤として、RAGやベクトルデータベースを組み合わせることで、安全かつ高精度な社内AIアシスタントを実現できます。
Web版のChatGPTに直接機密情報を入力するような運用は絶対に避けるべきです。
虚偽情報(ハルシネーション)の生成を防ぎたい場合
回答の正確性を担保し、ハルシネーションを防ぎたい場合には、RAGの導入が最も効果的です。
RAGは、社内データという明確な情報源を基に回答を生成するため、ChatGPTが不確かな知識で勝手に回答を作成するのを防ぎます。
さらに、回答の根拠となった参照元ドキュメントを提示する機能を実装すれば、ユーザーは情報の正しさを自ら確認でき、より安心してAIを利用できます。
企業のコンプライアンスや信頼性が重要視される業務において、RAGは欠かせない技術です。
できるだけ社内データを優先して回答させたい場合
ChatGPTの一般的な知識よりも、社内のナレッジや規定を優先して回答させたい場合にも、RAGが有効です。
プロンプトの設定で「提供された資料の情報だけを使って回答してください」と強く指示することで、社内データに基づいた回答を徹底させることが可能です。
また、特定の言い回しや対話スタイルを重視するなら、RAGとファインチューニングを組み合わせる方法もあります。
RAGで情報の正確性を担保しつつ、ファインチューニングで対話の質を高めるという、両者の長所を活かしたアプローチです。
低コストで手軽に始めたい場合
まずはスモールスタートで効果を試したい、という場合にはプロンプトエンジニアリングが最適です。
開発コストをかけずに、今すぐ始められるのが最大の魅力です。
ただし、情報漏洩のリスクを避けるため、扱うデータは個人情報や機密情報を含まないものに限定しましょう。
例えば、公開されているプレスリリースを要約させる、一般的なビジネスメールの文面を作成させるといった用途から始めるのが安全です。
本格的な活用には、API連携への移行を検討しましょう。
業界知識や専門用語を深く学習させたい場合
特定の業界や業務に特化した、高度な知識や専門用語を扱わせたい場合は、ファインチューニングが最も適しています。
モデル自体が専門知識を学習するため、RAGでは対応しきれないような、ニュアンスや暗黙知を含んだ回答が可能になります。
例えば、医療分野の論文を読解させたり、法律分野の専門的な文書を作成させたりするようなタスクで高い性能を発揮します。
ただし、質の高い大量の学習データが必要になるため、費用対効果を慎重に検討する必要があります。
ChatGPTが学習できる社内データの種類
ChatGPTに学習させるデータは、テキスト情報が中心となります。企業内に存在する様々な形式のドキュメントを活用することが可能です。
ここでは、代表的なデータの種類について解説します。
CSVファイル
CSVファイルは、顧客リスト、売上データ、アンケート結果など、構造化されたデータを格納するのに使われます。
これらのデータをChatGPTに読み込ませることで、データの集計、分析、傾向の把握、グラフ作成用のデータ整形などが可能になります。
例えば、「この顧客データから、購入額上位10名を抽出して」といった指示で、データ分析業務を効率化できます。
PDFファイル
社内には、マニュアル、規定集、研究レポート、契約書など、多くの情報がPDF形式で保存されています。
これらのPDFファイルをデータソースとすることで、内容に関する質疑応答や要約の作成が可能になります。
ファイル数が膨大な場合は、RAGの仕組みを使って、必要な情報を効率的に検索・活用する体制を構築することが重要です.
ドキュメント・テキストファイル
WordやGoogleドキュメント、テキストファイル(.txt)なども、重要な情報源です。
議事録、日報、企画書、仕様書といったドキュメントを学習させることで、過去の経緯を素早く把握したり、新しいドキュメントのたたき台を作成したりできます。
社内に蓄積されたドキュメントは、組織の貴重なナレッジ資産であり、ChatGPTによってその価値を最大限に引き出すことができます。
WebサイトのURL
社内ポータル(イントラネット)や社内Wikiなど、Webサイトの形式でナレッジが管理されている場合も多いでしょう。
これらのサイトのURLを指定し、情報を収集(クローリング)して学習データとすることも可能です。
常に最新の情報が更新されるWebサイトを定期的に読み込ませることで、AIが回答する情報の鮮度を保つことができます。
ChatGPTに社内データを学習させる3つのメリット
ChatGPTに社内データを学習させることには、多くのメリットがあります。ここでは、特に重要な3つのメリットを解説します。
自社の業務に特化した高精度な回答が可能になる
最大のメリットは、自社の状況や文脈を理解した、業務に直結する回答を生成できるようになることです。
社内用語や業界の専門用語、過去のプロジェクトの経緯などを踏まえた回答は、一般的なChatGPTでは決して得られません。
これにより、従業員は必要な情報を探す手間を大幅に削減でき、本来のコア業務に集中できるようになります。
社内ナレッジの検索・活用が効率化される
社内に散在するマニュアルや資料、過去のやり取りといった「暗黙知」を含めたナレッジを、対話形式で簡単に引き出せるようになります。
従来のキーワード検索では見つけにくかった情報にも、自然な言葉で質問するだけでたどり着けるようになります。
これにより、ベテラン社員の知識を若手にスムーズに継承したり、属人化しがちな業務ノウハウを組織全体で共有したりすることが可能になります。
情報漏洩リスクを管理しつつ安全に利用できる
Azure OpenAI ServiceなどのセキュアなAPIを利用して社内専用の環境を構築することで、情報漏洩のリスクを管理しながら安全にChatGPTを活用できます。
入力した社内データが外部のモデル学習に利用される心配がないため、機密情報や個人情報を含むデータも、適切な管理のもとで扱うことができます。
セキュリティと利便性を両立できる点は、企業にとって非常に大きなメリットです。
ChatGPTに社内データを学習させる際のデメリットとリスク
多くのメリットがある一方で、社内データを学習させる際には注意すべきデメリットやリスクも存在します。これらを事前に理解し、対策を講じることが成功の鍵です。
情報漏洩・セキュリティリスクの懸念
最も注意すべきリスクは、情報漏洩です。
Web版のChatGPTに安易に機密情報を入力してしまう、あるいはAPI連携のシステムに脆弱性があるといった場合に、情報が外部に流出する可能性があります。
Azure OpenAI Serviceの活用や閉域網接続、厳格なアクセス権管理など、多層的なセキュリティ対策を講じることが不可欠です。
回答生成の速度が低下する可能性
RAGのように、回答生成前に社内データを検索するプロセスを挟む場合、通常のChatGPTよりも回答速度が若干遅くなることがあります。
ユーザー体験を損なわないためには、ベクトルデータベースの最適化や、システムのインフラ設計を適切に行い、検索速度を可能な限り高速に保つ工夫が必要です。
導入・運用にコストがかかる
社内データを活用するためには、システム開発やAPI利用料、ベクトルデータベースの維持費など、様々なコストが発生します。
ファインチューニングを行う場合は、さらに高額な費用がかかることもあります。
導入前に、どの程度の投資対効果が見込めるのかを慎重に試算し、スモールスタートで効果を検証しながら段階的に投資を拡大していくアプローチが推奨されます。
ハルシネーション(虚偽情報)のリスク
RAGによってハルシネーションは大幅に抑制できますが、完全にゼロにできるわけではありません。
参照する社内データ自体に誤りがあったり、複数の資料を組み合わせる過程で矛盾した情報を生成してしまったりする可能性は残ります。
AIの回答を鵜呑みにせず、最終的には人間が内容をファクトチェックするという運用ルールを徹底することが重要です。
ChatGPTと社内データを連携したビジネス活用法7選
ChatGPTと社内データを連携させることで、具体的にどのような業務が効率化できるのでしょうか。
ここでは、代表的な7つのビジネス活用法を紹介します。
社内規定やマニュアル検索ができるAIチャットボット開発
経費精算のルールや福利厚生の申請方法など、社内の様々な問い合わせに対応するAIチャットボットを開発できます。
従業員は担当部署に電話したり、大量のマニュアルを読み解いたりする必要がなくなり、自己解決できる範囲が大幅に広がります。
バックオフィス部門の問い合わせ対応業務を削減し、生産性向上に大きく貢献します。
顧客対応を自動化するカスタマーサポートAI
過去の問い合わせ履歴やFAQ、製品マニュアルを学習させることで、顧客からの質問に24時間365日自動で回答するカスタマーサポートAIを構築できます。
簡単な質問はAIが即座に解決し、複雑な問題のみ人間のオペレーターが対応することで、顧客満足度の向上とサポート部門の業務負荷軽減を両立できます。
議事録や日報の自動要約・作成
会議の録音データや、従業員が入力した日報のテキストデータを基に、ChatGPTが自動で要約や清書を行います。
文章作成にかかる時間を大幅に短縮できるため、従業員はより創造的な業務に時間を使うことができます。
決定事項やタスクを自動で抽出し、関係者に通知するような仕組みも実現可能です。
契約書や企画書のドラフト作成支援
過去の契約書や企画書のデータを学習させることで、新しい案件のドラフト(たたき台)を瞬時に作成できます。
ゼロから文書を作成する手間が省け、業務スピードが飛躍的に向上します。
法務部門のレビュー負荷軽減や、営業部門の提案資料作成の効率化に繋がります。
こちらはChatGPTで契約書を作成する方法について解説した記事です。法務部門の業務効率化に役立つ情報ですので、合わせてご覧ください。 https://taskhub.jp/use-case/chatgpt-contract-creation/
ソフトウェア開発におけるコード生成・デバッグ
社内のコーディング規約や過去のソースコードを学習させることで、仕様書に基づいたコードの自動生成や、バグの発見・修正案の提示などが可能になります。
開発者は単純なコーディング作業から解放され、より設計や要件定義といった上流工程に集中できます。
開発の生産性と品質の向上に大きく貢献する活用法です。
社内データに基づいた市場分析・需要予測
売上データ、顧客データ、市場調査レポートといった社内データを分析し、新たなビジネスチャンスの発見や、将来の需要予測を行います。
人間では気づきにくいデータ内のパターンや相関関係をAIが発見し、データに基づいた客観的な意思決定を支援します。
マーケティング戦略の立案や、在庫管理の最適化などに活用できます。
個々の従業員に最適化された自律型AIエージェント開発
各従業員の業務内容や役割、過去の成果物などを学習し、一人ひとりに最適化された業務サポートを行うAIエージェントを開発します。
スケジュール管理、メールの自動返信、関連資料の収集などを自律的に行い、まるで優秀な秘書のように従業員の業務を支援します。
従業員一人ひとりの生産性を最大化する、未来の働き方として注目されています。
ChatGPTへの社内データ連携・活用国内・海外事例14選
実際に、多くの企業がChatGPTと社内データの連携に取り組み、成果を上げています。
国内外の先進的な事例を14件、一挙にご紹介します。
【金融】七十七銀行:商品の販売状況の分析・可視化
七十七銀行では、行内のデータをAzure OpenAI Serviceと連携させ、営業担当者が商品の販売状況などを自然な言葉で問い合わせできるシステムを構築しました。これにより、データ分析の専門家でなくても、必要な情報を迅速に入手し、営業活動に活かせるようになりました。
【建設】西松建設:高精度な建設コストの予測
西松建設は、過去の膨大な工事データをAIに学習させ、建設プロジェクトのコストを高精度に予測するシステムを開発しました。資材価格の変動や設計変更にも柔軟に対応し、より正確な見積もりと利益管理を実現しています。
【小売】セブンイレブン:商品企画の期間を大幅短縮
セブン-イレブン・ジャパンでは、社内データやトレンド情報を基に、新商品の企画案をAIが生成する取り組みを進めています。企画担当者はAIが提案した多様なアイデアから有望なものを選択・改良することで、商品開発のスピードを大幅に向上させています。
【製造】サントリー:ユニークなCM企画の立案
サントリーは、過去のCMデータや消費者アンケートの結果を学習させたAIを活用し、新しいCMの企画案を立案しています。人間では思いつかないような意外な組み合わせや斬新な切り口のアイデアをAIが提供し、クリエイティブな企画業務を支援しています。
【金融】三菱UFJ銀行:月22万時間の労働時間を削減
三菱UFJ銀行は、行内の問い合わせ対応や書類作成などに生成AIを導入し、全行的に業務効率化を推進しています。その結果、月間で22万時間もの労働時間削減に成功し、行員がより付加価値の高い業務に集中できる環境を整えています。
【金融】SMBCグループ:独自の対話AIで生産性向上
SMBCグループは、独自の対話AI「SMBC-GPT」を開発し、全グループ社員に展開しています。社内規定の検索や資料作成、アイデア出しなど、幅広い業務に活用することで、組織全体の生産性向上を目指しています。
【IT】LINE:エンジニアの業務効率化
LINEヤフーでは、エンジニア向けに特化したAIアシスタントを開発しました。社内の技術ドキュメントやソースコードを学習しており、コーディングやデバッグ、技術的な問題解決を強力にサポートし、開発効率を大幅に向上させています。
【金融】みずほグループ:システム開発の品質向上
みずほグループは、システム開発の工程において、仕様書のレビューやテストケースの作成に生成AIを活用しています。AIが人間の見落としがちな矛盾点や不備を指摘することで、開発の手戻りを減らし、システムの品質向上に繋げています。
【製造】パナソニックコネクト:全社的なAIアシスタント導入
パナソニックコネクトは、全社員約1万人が利用できるAIアシスタント「ConnectAI」を導入しました。社内文書の検索や翻訳、議事録作成など、日常業務の様々な場面で活用され、全社的な業務効率化とDX推進の原動力となっています。
【製造】アサヒビール:社内情報検索の効率化
アサヒビールでは、社内に散在する様々な情報を統合的に検索できるAIシステムを構築しました。従業員は必要な情報を探すために複数のシステムを渡り歩く必要がなくなり、目的の情報に素早くアクセスできるようになりました。
【小売】ウォルマート:高度な商品検索・提案機能
海外の事例として、小売大手のウォルマートは、自社のECサイトに生成AIを活用した高度な検索機能を導入しました。「キャンプ用の道具一式」のような曖昧な検索に対しても、関連商品をまとめて提案し、顧客の購買体験を向上させています。
【化粧品】ロレアル:AIによるパーソナライズ美容提案
化粧品会社のロレアルは、顧客の肌データや好みを基に、AIが最適なスキンケアやメイクアップ製品を提案するサービスを展開しています。パーソナライズされた体験を提供することで、顧客エンゲージメントを高めています。
【IT】メルカリ:AIによる出品サポート
フリマアプリのメルカリでは、出品したい商品の写真を撮るだけで、AIがカテゴリーやブランド、商品の説明文、さらには売れやすい価格まで自動で提案する機能を導入しています。これにより、出品の手間が大幅に削減され、ユーザーの利便性が向上しました。
【人材】ビズリーチ:職務経歴書の作成支援
ビズリーチは、会員がより魅力的な職務経歴書を作成できるよう、生成AIによる添削・提案機能を導入しました。AIがキャリアの強みを引き出す表現を提案し、転職活動をサポートしています。
ChatGPTに社内データを学習させる際の6つの注意点
ChatGPTへの社内データ活用を成功させるためには、技術的な側面だけでなく、運用面での注意点も押さえておく必要があります。
ここでは、特に重要な6つの注意点を解説します。
学習させる社内データの範囲を適切に設定する
どのようなデータを学習させるかが、AIの性能を大きく左右します。
まずは目的を明確にし、その目的達成に必要なデータは何かを定義することが重要です。
また、古い情報や誤った情報が含まれていると、AIの回答精度が低下するため、データの品質管理(クレンジング)も欠かせません。
セキュリティ対策を万全にする
前述の通り、セキュリティは最重要課題です。
利用するプラットフォームの選定(Azure OpenAI Service 등)、アクセス権の厳格な管理、データの暗号化、定期的な脆弱性診断など、システム面での対策を徹底しましょう。
技術的な対策と同時に、運用ルールの整備も不可欠です。
従業員向けの利用ルールやガイドラインを策定する
どのような情報を入力して良いか、AIの回答をどのように扱うべきかなど、全従業員が遵守すべきルールを明確に定め、周知徹底することが重要です。
特に、個人情報や顧客の機密情報の取り扱いについては、厳格なガイドラインを設ける必要があります。
これにより、不用意な情報漏洩や不適切な利用を防ぎます。
経済産業省と総務省が公開している「AI事業者ガイドライン」です。企業がAIを安全に利活用するための具体的な指針が示されていますので、ぜひご参照ください。https://www.meti.go.jp/press/2024/04/20240419004/20240419004.html
従業員のAIリテラシーを向上させる研修を行う
ツールを導入するだけでは、全社的な活用は進みません。
ChatGPTの基本的な仕組みや、効果的な使い方(プロンプトの書き方など)、利用上の注意点などを学ぶ研修を実施し、従業員全体のAIリテラシーを引き上げることが成功の鍵です。
研修を通じて、従業員の不安を解消し、積極的な活用を促します。
自社の目的に合った最適なプランや手法を選定する
本記事で紹介したように、社内データを学習させる方法には様々な選択肢があります。
「低コストで始めたい」「セキュリティを最優先したい」「特定の業務に特化させたい」など、自社の目的、予算、技術力に応じて、最適な手法やサービスプランを慎重に選定することが大切です。
最新の技術動向を常にチェックし、活用方法を見直す
生成AIの技術は日進月歩で進化しています。
新しいモデルや、より効率的な手法が次々と登場するため、一度システムを構築して終わりにするのではなく、常に最新の技術動向をキャッチアップし、自社の活用方法を継続的に見直していく姿勢が求められます。
定期的なアップデートで、AIの価値を最大化し続けましょう。
企業がChatGPTに社内データを学習させるための4ステップ
これから社内データ活用を始めたい企業は、どのような手順で進めればよいのでしょうか。
ここでは、導入を成功させるための具体的な4つのステップを解説します。
Step1:活用目的と範囲の明確化
まず最初に、「何のためにAIを導入するのか」「どの業務の、どのような課題を解決したいのか」という目的を具体的に定義します。
例えば、「バックオフィスの問い合わせ対応工数を30%削減する」「営業担当者の提案資料作成時間を半分にする」といった、測定可能な目標を設定することが重要です。
目的が明確になることで、必要なデータや最適な技術選定が自ずと見えてきます。
Step2:利用環境の構築とセキュリティ設定
次に、目的に合わせて利用するプラットフォーム(Azure OpenAI Serviceなど)を選定し、セキュアなAIの利用環境を構築します。
この段階で、アクセス権の管理やデータの取り扱いに関するセキュリティポリシーを詳細に設計し、実装することが不可欠です。
情報システム部門と連携し、全社的なセキュリティ基準を満たす環境を準備します。
Step3:スモールスタートでの試験開発・運用(PoC)
いきなり全社展開を目指すのではなく、まずは特定の部署や特定の業務に絞って、小規模な試験開発・運用(PoC: Proof of Concept)から始めることをお勧めします。
スモールスタートでAIの効果や課題を実際に検証し、ユーザーからのフィードバックを収集します。
このPoCの結果を基に、本格導入に向けた改善点や投資対効果を評価します。
Step4:本格的な開発と全社展開
PoCで有効性が確認できたら、その結果を基に本格的な開発に着手し、対象部署や業務範囲を段階的に拡大していきます。
全社展開にあたっては、利用ガイドラインの策定や従業員向けの研修を徹底し、スムーズな導入と活用を支援します。
また、導入後も継続的に利用状況をモニタリングし、改善を繰り返していくことが重要です。
ChatGPTの社内データ活用を成功させる5つのポイント
最後に、これまでの内容を総括し、ChatGPTの社内データ活用を成功に導くための5つの重要なポイントを解説します。
活用する業務の洗い出しと投資対効果の試算
まずは、AIを活用することで大きな効果が見込める業務を具体的に洗い出すことから始めましょう。
定型的で繰り返しの多い業務や、大量の情報検索が必要な業務などが候補となります。
そして、その業務にAIを導入した場合のコスト(開発費、運用費)と、得られる効果(人件費削減、時間短縮など)を試算し、投資対効果(ROI)を明確にすることが、経営層の理解を得る上で重要です。
アジャイルアプローチでの迅速な開発・導入
生成AIの世界は変化が速いため、ウォーターフォール型で時間をかけて完璧なシステムを開発しようとすると、完成した頃には技術が陳腐化している可能性があります。
まずは最小限の機能(MVP: Minimum Viable Product)で迅速にリリースし、ユーザーのフィードバックを得ながら、短いサイクルで改善を繰り返すアジャイルアプローチが有効です。
システムとルールの両面からのリスク管理
セキュリティやコンプライアンスのリスク管理は、技術的な対策(システム)と、従業員が遵守すべき運用方針(ルール)の両面から行うことが不可欠です。
どれだけ強固なシステムを構築しても、従業員のルール違反があれば情報は漏洩します。
逆もまた然りです。システムとルールの両輪で、安全なAI活用環境を維持しましょう。
外部の専門企業のサポート活用も検討する
社内にAIやセキュリティの専門知識を持つ人材が不足している場合、無理に内製にこだわらず、外部の専門企業の支援を活用することも有効な選択肢です。
専門企業の知見や開発力を活用することで、導入のスピードを速め、失敗のリスクを低減できます。
自社の強みを活かしつつ、足りない部分はパートナーと協力する体制を築くことが成功への近道です。
RAG構築の方針(内製か外注か)を決定する
特に、現在の主流であるRAGシステムを構築する際には、自社で一から開発する「内製」か、既存のサービスや開発会社に依頼する「外注」かを慎重に判断する必要があります。
内製はカスタマイズの自由度が高いですが、高度な技術力と開発リソースが必要です。
外注は迅速に導入できますが、コストや仕様の制約が発生します。
自社の技術力、予算、導入スケジュールを総合的に勘案し、最適な方針を決定しましょう。
PwCが実施した「生成AIに関する実態調査」では、国内外の企業が生成AIの活用にどのように取り組んでいるかが分かります。自社の立ち位置を確認するためにも、ぜひご覧くださいhttps://www.pwc.com/jp/ja/knowledge/thoughtleadership/generative-ai-survey2025.html
そのChatGPT活用、無駄になっていませんか?「使えないAI」を「ベテラン社員」に変える新常識
せっかくChatGPTを導入したのに、当たり障りのない一般論しか返ってこない。「自社のあの資料について教えて」と聞いても「分かりません」と答えるばかり。そんな経験はありませんか?実は、標準的なChatGPTは、インターネットの情報しか知らない「物知りな新人」です。あなたの会社のルールや過去の議事録、顧客データといった最も重要な情報は一切学習していません。この問題を放置すると、AIは使われないままコストだけがかかる置物になってしまいます。
この課題を解決する技術として、現在主流となっているのが「RAG(Retrieval-Augmented Generation)」という仕組みです。これは、AIに質問が投げられた際、まず社内データベースから関連する資料を検索し、その内容を根拠として回答を生成させる技術です。これにより、AIが不確かな情報から嘘の回答(ハルシネーション)を作り出すリスクを劇的に低減できます。AIを単なる検索エンジンではなく、社内ナレッジを理解し、文脈に沿った回答ができる「経験豊富なベテラン社員」へと育てることができるのです。
引用元:
スタンフォード大学の研究では、RAGが大規模言語モデルの知識を動的に更新し、より正確で信頼性の高い情報を提供するための効果的な手法であることが示されています。モデルが持つ内部知識と、外部のドキュメントから検索した情報を組み合わせることで、回答の質を向上させることが可能です。(Gao, Y., et al. “Retrieval-Augmented Generation for Large Language Models: A Survey” 2023年)
まとめ
企業は業務効率化や生産性向上のために生成AIの活用を目指していますが、「社内データをどう連携すればいいか分からない」「情報漏洩のリスクが怖い」「AIの専門知識を持つ人材がいない」といった理由で、導入に踏み切れないケースが少なくありません。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
例えば、社内マニュアルの検索や議事録の要約、企画書のドラフト作成など、社内データを活用したい様々な業務を「アプリ」として選ぶだけで、誰でも直感的にAIを活用できます。
しかも、Azure OpenAI Serviceを基盤にしているため、データセキュリティが万全で、入力した社内データが外部で学習に使われる心配もありません。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「どのデータをどう使えば効果的かわからない」という初心者企業でも安心してスタートできます。
RAGシステムの構築といった複雑な開発や高度なAI知識がなくても、すぐに社内ナレッジを活用した業務効率化が図れる点が大きな魅力です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最速かつ安全な社内データ活用”を体験し、御社のDXを一気に加速させましょう。







