

「ChatGPTに自社の情報を学習させて、業務に特化したチャットボットを作れないだろうか?」
「社内データをChatGPTに学習させたいけど、情報漏洩のリスクが心配で踏み出せない…。」
こういった悩みを持っている方もいるのではないでしょうか?
本記事では、ChatGPTに社内データを学習させる具体的な5つの方法と、それぞれのメリット・デメリット、さらに失敗しないための注意点について網羅的に解説しました。
上場企業をメインに生成AIコンサルティング事業を展開している弊社が、実際の導入支援で培った知見を基にご紹介します。
きっと役に立つと思いますので、ぜひ最後までご覧ください。
ChatGPTの社内データ学習の前に知るべき2つの基礎知識
まず初めに、ChatGPTへ社内データを学習させる上で前提となる、以下の基礎知識を解説します。
- ChatGPTが元々学習しているデータの種類とその限界
- 社内データを追加学習させることの重要性
ChatGPTが元々どのようなデータを学習しているのか、そしてなぜ社内データの追加学習が重要なのかを理解することで、自社に最適な活用方法を見つけられるようになります。
それでは、1つずつ順に解説します。
ChatGPTが元々学習しているデータの種類とその限界
ChatGPTは、その基盤となる大規模言語モデル(LLM)が、インターネット上に存在する膨大なテキストデータを学習しています。
これには、ウェブサイト、書籍、論文、ニュース記事など、公開されている多種多様な情報が含まれます。
この広範な知識により、ChatGPTは一般的な質問に対して非常に高い精度で回答を生成できます。
しかし、その知識には限界があります。
第一に、学習データは特定の時点(例:2023年初頭)でカットオフされており、それ以降の最新情報やリアルタイムの出来事には対応できません。
そして最も重要な限界は、社内の業務マニュアル、顧客情報、過去のプロジェクト資料といった、インターネット上に公開されていない非公開情報には一切アクセスできない点です。
そのため、自社の業務に関する具体的な質問をしても、一般的で曖昧な回答しか得られないのです。
ChatGPTの仕組みについて、さらに詳しく知りたい方はこちらの記事もご覧ください。
社内データを追加学習させることの重要性
前述のChatGPTの限界を克服し、ビジネスツールとして真価を発揮させるために不可欠なのが、社内データの追加学習です。
自社が保有する独自の情報をChatGPTに学習させることで、一般的な知識しか持たないアシスタントから、自社の業務や文化、専門用語を深く理解した「エキスパート社員」へと進化させることができます。
例えば、社内規定に関する問い合わせに即座に回答したり、過去の類似案件のデータを基に精度の高い提案書を作成したり、新入社員が業務を覚えるための教育ツールとして活用したりと、その可能性は無限大です。
社内データを学習させることは、単に回答の精度を高めるだけでなく、属人化しがちなナレッジを共有し、組織全体の生産性を向上させるための重要なステップと言えるでしょう。
ChatGPTに社内データを学習させる具体的な手法5選
ここからは、ChatGPTに社内データを学習させるための具体的な手法を5つ紹介します。
- プロンプトエンジニアリング
- RAG(検索拡張生成)
- ファインチューニング
- エンべディング(ベクトルデータベース)
- 専用ツールの導入
それぞれの手法には特徴があり、技術的な難易度やコスト、実現できることの範囲が異なります。
自社の目的やリソースに合わせて最適な方法を選べるよう、1つずつ順に解説します。
①プロンプトエンジニアリング:非エンジニアでも手軽に実行可能
プロンプトエンジニアリングは、ChatGPTとの対話(プロンプト)の中に、参考にしてほしい社内データを直接入力する方法です。
例えば、「以下の会議議事録を参考にして、A社向けの提案書の骨子を作成してください。【議事録データ】」のように、指示と一緒に情報を提供します。
この手法の最大のメリットは、特別な開発や専門知識が不要で、誰でも今すぐに試せる手軽さです。
小規模なタスクや、一時的に少量のデータを参照させたい場合に非常に有効です。
ただし、プロンプトには入力できる文字数に上限があるため、長文のマニュアルや大量のデータを一度に扱うことはできません。
また、対話が終了すると入力した情報は忘れられてしまうため、同じ情報を利用する際は毎回入力し直す手間が発生します。
手軽に始められる反面、本格的な業務利用には向かない手法と言えます。
ChatGPTで使える効果的なプロンプトについて具体的に知りたい方は、こちらの記事も併せてご覧ください。
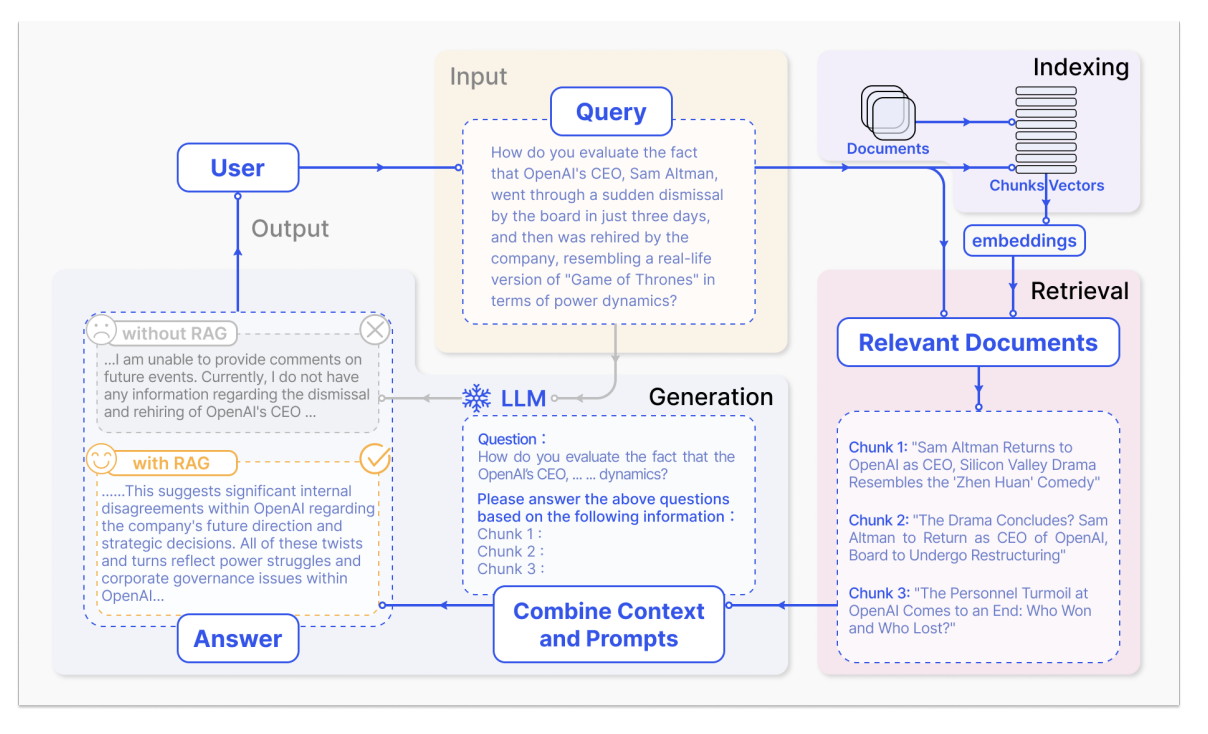
②RAG(検索拡張生成):膨大な社内データからの検索に強み
RAG(Retrieval-Augmented Generation:検索拡張生成)は、現在、社内データ活用の主流となっている技術です。
この仕組みでは、まず社内ドキュメントを専用のデータベースに保管しておきます。
ユーザーが質問をすると、AIがその質問に関連する情報をデータベースから検索し、見つけ出した情報を基にして回答を生成します。
この手法の強みは、膨大な量の社内データを扱える点です。
最新の情報をデータベースに追加するだけで、ChatGPTが参照する知識を常にアップデートできます。
また、回答の根拠となったドキュメントを提示できるため、生成された情報の信頼性が高く、虚偽情報(ハルシネーション)を抑制できるという大きなメリットもあります。
一方で、RAGのシステムを構築するには、データベースの設計や検索精度のチューニングなど、ある程度の専門知識が必要になります。
RAGの技術的な背景や最新の研究動向については、こちらのサーベイ論文で網羅的に解説されています。合わせてご覧ください。 https://arxiv.org/pdf/2312.10997
③ファインチューニング:モデルを自社の目的・用途に特化
ファインチューニングは、特定の目的やタスクに合わせて、ChatGPTの基盤となる言語モデル自体を追加学習させる手法です。
例えば、自社の過去の問い合わせ対応履歴を大量に学習させることで、独自の言い回しや顧客対応のニュアンスを理解した、より人間らしい応答が可能なカスタマーサポート用AIを開発できます。
この手法のメリットは、モデルの挙動そのものを自社のスタイルに最適化できるため、特定のタスクにおいて非常に高いパフォーマンスを発揮する点です。
RAGのように外部データを参照するプロセスがないため、応答速度が速い場合もあります。
ただし、ファインチューニングには、大量の学習データと高い技術力、そしてモデルの学習にかかる高額な計算コストが必要です。
また、一度学習させると、知識の更新にも再度ファインチューニングが必要になるなど、運用面のハードルも高い手法です。
④エンべディング(ベクトルデータベース):関連性の高い情報を高速で抽出
エンべディング(Embedding)は、文章や単語の意味や文脈を数値のベクトルに変換する技術です。
そして、このベクトル化されたデータを保管し、高速で検索できるようにしたものがベクトルデータベースです。
これは主に、前述のRAG(検索拡張生成)の根幹をなす技術として利用されます。
社内ドキュメントをあらかじめベクトル化してデータベースに保存しておくことで、ユーザーからの質問が来た際に、その質問文と意味的に類似・関連性の高い情報を瞬時に見つけ出すことができます。
キーワード検索では見つけられないような、文脈に基づいた柔軟な情報検索が可能になるのが最大の強みです。
この技術を使いこなすには、自然言語処理やデータベースに関する専門知識が求められますが、社内ナレッジ検索の精度を飛躍的に向上させるための鍵となる要素です。
⑤専用ツールの導入:ベンダー提供のセキュアな環境で実現
自社でシステムを構築するのではなく、AIベンダーが提供する法人向けの専用ツールやプラットフォームを導入する方法もあります。
これらのツールの多くは、RAGの仕組みをベースにしており、セキュリティが確保されたクローズドな環境で社内データをアップロードし、対話AIとして利用できるようになっています。
最大のメリットは、高度な専門知識がなくても、比較的容易にセキュアな社内データ活用環境を構築できる点です。
情報漏洩のリスクを最小限に抑えながら、ベンダーによるサポートも受けられるため、安心して導入を進められます。
代表的な例として、Microsoftの「Azure OpenAI Service」を活用したツールが挙げられます。
デメリットとしては、当然ながらツールの利用料(ライセンス費用)が継続的に発生します。
また、提供される機能の範囲内でしかカスタマイズできないため、自社の特殊な要件に完全に対応できない場合もあります。
ChatGPTの社内データ学習に利用できる3つのファイル形式
ここからは、ChatGPTの社内データ学習、特にRAGのような手法で利用されることの多い、以下の代表的なファイル形式を3つ紹介します。
- CSVファイル
- PDFファイル
- WebサイトのURL
これらの形式を理解することで、自社にどのようなデータがあり、それをどう活用できるかのイメージが湧きやすくなります。
CSVファイル
CSV(Comma-Separated Values)は、カンマで区切られたテキスト形式のデータファイルです。
主に、Excelのような表計算ソフトで扱われる構造化データ(行と列で整理されたデータ)を保存する際に利用されます。
例えば、顧客リスト、売上データ、商品マスタ、アンケート結果などがCSV形式で管理されていることが多いでしょう。
これらのデータをChatGPTに学習させることで、「先月の売上トップ5の商品を教えて」「東京都在住の顧客数を集計して」といった、データ分析に関する質問に回答させることが可能になります。
構造が明確であるため、AIがデータを解釈しやすく、正確な集計や分析結果を得やすいのが特徴です。
PDFファイル
PDF(Portable Document Format)は、どのような環境でもレイアウトが崩れずに表示できるファイル形式です。
そのため、ビジネスの現場では、業務マニュアル、社内規定、研究レポート、契約書、プレゼンテーション資料など、非常に多くのドキュメントがPDFで共有されています。
これらのPDFファイルを学習させることで、社内の膨大なナレッジの中から必要な情報を瞬時に探し出すAIナレッジ検索システムを構築できます。
例えば、「在宅勤務規定について教えて」「製品Aのトラブルシューティング方法を教えて」といった質問に対して、関連するマニュアルの該当箇所を要約して提示してくれます。
ただし、PDF内の図表や複雑なレイアウトから正確にテキストを抽出する技術(OCR)の精度が、回答の質に影響します。
WebサイトのURL
社内ポータルサイトや、イントラネット上で公開されているFAQページ、製品情報サイトなども、貴重な学習データソースとなります。
これらのWebサイトのURLを指定することで、サイト内の情報をクローリング(自動巡回収集)し、AIの学習データとして取り込むことができます。
この方法のメリットは、情報が更新されると、再度クローリングするだけでAIの知識も最新の状態に保てる点です。
常に変化する社内の最新情報を反映させたい場合に非常に有効な手段です。
Webサイトの構造によっては、うまく情報を収集できない場合もあるため、対象サイトの作りを考慮する必要があります。
目的・悩み別|最適なChatGPTの社内データ学習方法の5つの選び方
ここまで複数の学習方法を紹介しましたが、「結局、自社にはどの方法が合っているのか?」と迷う方もいるでしょう。
ここでは、企業が抱える目的や悩み別に、どの学習方法が最適なのか、以下の5つ解説します。
- 情報漏洩・セキュリティリスクを最優先で対策したい場合
- 虚偽情報(ハルシネーション)の生成を抑制したい場合
- コストを抑えつつ手軽に始めたい場合
- 回答に利用した社内データの根拠を把握したい場合
- 特定の業務知識を深く習得させたい場合
自社の状況と照らし合わせながらご覧ください。
情報漏洩・セキュリティリスクを最優先で対策したい場合
個人情報や機密情報など、外部への漏洩が絶対に許されないデータを扱う場合、セキュリティが最も重要な選択基準となります。
このケースで最適なのは、「専用ツールの導入」、特にMicrosoftのAzure OpenAI Serviceを基盤としたソリューションです。
Azure OpenAI Serviceは、入力されたデータがOpenAI社のモデル学習に利用されることがなく、クローズドなネットワーク内で安全に利用できる環境を提供します。
自社でRAGシステムを構築する場合も、同様にAzure OpenAI ServiceをAPIで利用することで、高いセキュリティレベルを確保できます。
通常のChatGPT(無料版やChatGPT Plus)に直接機密情報を入力するプロンプトエンジニアリングは、情報漏洩のリスクがあるため絶対に避けるべきです。
ハルシネーションを含むAIのリスク管理については、米国国立標準技術研究所(NIST)が公開しているフレームワークが参考になります。合わせてご覧ください。 https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf
虚偽情報(ハルシネーション)の生成を抑制したい場合
AIが事実に基づかない、もっともらしい嘘の情報を生成してしまう「ハルシネーション」は、ビジネス利用において大きなリスクとなります。
この問題を最も効果的に抑制できるのが「RAG(検索拡張生成)」です。
RAGは、必ず社内データベースに存在する情報を根拠として回答を生成する仕組みです。
そのため、AIが勝手な創作をすることを防ぎ、事実に基づいた信頼性の高い回答を維持できます。
さらに、回答と一緒に「この回答は、社内規定マニュアルのP.5を参考にしました」といったように、参照元のドキュメントを提示する機能も実装可能です。
これにより、ユーザーは回答の正しさを自ら確認でき、安心してAIを利用できます。
こちらはAIのハルシネーションを防ぐプロンプトについて解説した記事です。 合わせてご覧ください。 https://taskhub.jp/use-case/chatgpt-prevent-hallucination/
コストを抑えつつ手軽に始めたい場合
まずは試験的に、コストをかけずにAI活用の可能性を探ってみたいという場合には、「プロンプトエンジニアリング」が最適です。
特別なシステム開発や月額費用は不要で、ChatGPTの画面を開けばすぐにでも試すことができます。
例えば、公開されている情報や、機密性の低い少量のテキストデータをプロンプトに貼り付けて、要約や文章作成を試してみることから始めると良いでしょう。
この方法でAI活用の効果を実感できれば、次のステップとしてRAGシステムの導入などを本格的に検討するための説得材料にもなります。
ただし、前述の通り、扱えるデータ量やセキュリティ面での制約は大きいことを理解しておく必要があります。
企業向けのChatGPT料金プランについて知りたい方は、こちらの記事も合わせてご覧ください。
回答に利用した社内データの根拠を把握したい場合
業務でAIを利用する上で、「なぜAIがその回答をしたのか」という根拠やプロセスがブラックボックス化していると、安心して意思決定に利用できません。
回答の透明性やトレーサビリティを確保したい場合には、「RAG(検索拡張生成)」が最も適しています。
RAGは、回答を生成する際に参照した社内ドキュメントの箇所を特定できます。
そのため、AIの回答と合わせて「参照元:〇〇議事録.pdf」「関連ドキュメント:△△マニュアル.docx」といった形で出典を明記することが可能です。
これにより、ユーザーは情報の裏付けを簡単に行うことができ、万が一AIの回答に疑問があった場合でも、元の資料を確認して迅速に事実確認ができます。
特定の業務知識を深く習得させたい場合
業界特有の専門用語や、社内独自の言い回し、特定の文体などをAIに深く学習させ、それに沿ったアウトプットをさせたい場合には、「ファインチューニング」が最も効果的です。
例えば、法律事務所が過去の判例や法律文書を学習させ、特有の法的文書スタイルに合わせた文章を生成させたり、クリエイティブ企業が自社のブランドボイスに沿ったマーケティングコピーを生成させたりするケースが考えられます。
RAGが「知識を検索して利用する」のに対し、ファインチューニングは「モデルの性格や話し方そのものを変える」イメージです。
高い専門性が求められる特定のタスクを繰り返し行う場合に、その真価を発揮します。
ChatGPTで社内データ学習を行う3つのメリット
ChatGPTに社内データを学習させることで、企業は具体的にどのような恩恵を受けられるのでしょうか。
ここでは、その代表的なメリットを以下の3つに絞って解説します。
- 自社の業界・業務に特化した専門的な回答の生成
- 社内情報に基づいた高精度な回答が可能になる
- 誤った回答が生成されるリスクの軽減
これらのメリットを理解することで、社内導入の目的をより明確にすることができます。
自社の業界・業務に特化した専門的な回答の生成
最大のメリットは、一般的なChatGPTでは不可能な、自社の文脈を深く理解した専門的な回答を得られることです。
社内で使われる独自の略語や専門用語、特定のプロジェクト名などを理解した上で対話ができるようになります。
例えば、「Aプロジェクトの進捗について、先週の定例議事録を基に要約して」といった具体的な指示にも的確に応えることができます。
これは、まるで長年その会社で働いてきたベテラン社員に質問するような感覚に近いでしょう。
このように、業界や自社の業務に特化したAIアシスタントを持つことで、情報検索や資料作成の効率が飛躍的に向上します。
社内情報に基づいた高精度な回答が可能になる
インターネット上の不確かな情報ではなく、自社が保有する正確で信頼性の高い情報を基に回答を生成するため、アウトプットの精度が格段に向上します。
社内規定、業務マニュアル、過去の成功事例、公式な製品スペックなど、正解が明確な情報源を利用することで、一貫性のある正しい回答を得ることができます。
これにより、社員が誤った情報に基づいて判断を下すリスクを減らし、業務品質の標準化にも繋がります。
特に、コンプライアンスや法務、経理といった正確性が厳しく求められる部門において、このメリットは非常に大きな価値を持ちます。
社員が迷うことなく、常に正しい情報にアクセスできる環境を構築できます。
誤った回答が生成されるリスクの軽減
ChatGPTの課題の一つであるハルシネーション(虚偽情報の生成)のリスクを大幅に軽減できる点も大きなメリットです。
AIが回答を生成する際の参照範囲を、管理された社内データのみに限定することで、AIが自由に創作を行ったり、インターネット上の誤った情報を拾ってきたりすることを防ぎます。
特に、顧客対応や公式なドキュメント作成など、誤った情報が外部に出ることが許されない業務において、このリスク軽減効果は不可欠です。
安全な情報源(グラウンディング)に基づいた回答生成は、企業が安心して生成AIを業務に活用するための大前提となります。
社内データを学習させることは、AIの能力を最大限に引き出しつつ、そのリスクをコントロールするための最も有効な手段なのです。
ChatGPTへ社内データを学習させる際の3つのリスク
多くのメリットがある一方で、ChatGPTへの社内データ学習には注意すべきデメリットやリスクも存在します。
これらを事前に把握し、適切な対策を講じることが、導入を成功させるための鍵となります。ここでは、特に注意すべき以下の3つのリスクを解説します。
- 個人情報や機密情報が漏洩するセキュリティリスク
- 回答生成のスピードが遅くなる可能性
- 実装や運用・メンテナンスにコストがかかる可能性
では、それぞれ1つずつ解説していきます。
個人情報や機密情報が漏洩するセキュリティリスク
最も警戒すべきリスクが、情報漏洩です。
特に、無料版のChatGPTや、セキュリティ対策が不十分なツールを利用した場合、入力した社内データがAIモデルの学習に利用され、意図せず他のユーザーへの回答として出力されてしまう可能性があります。
このような事態を防ぐためには、入力データが再学習に利用されないことが保証されている法人向けプラン(ChatGPT Enterpriseなど)や、Microsoft Azureのようなセキュアなクラウド環境上で提供されるAIサービス(Azure OpenAI Service)を選択することが不可欠です。
安易なツール選定は、企業の信頼を揺るがす重大なインシデントに繋がりかねないことを肝に銘じる必要があります。
回答生成のスピードが遅くなる可能性
社内データを活用する手法、特にRAG(検索拡張生成)を導入した場合、回答が生成されるまでのスピードが遅くなる可能性があります。
これは、ユーザーからの質問を受けるたびに、「①データベースへ関連情報を検索しに行く」「②見つかった情報を基に回答を生成する」という2つのステップを踏むためです。
通常のChatGPTのように、モデルが持つ知識だけで即座に回答する場合と比較して、検索のプロセスが加わる分、どうしても応答時間に遅延(レイテンシー)が生じます。
データベースの規模やシステムの設計、ネットワーク環境によっては、ユーザーがストレスを感じるほどの待ち時間が発生することもあります。
リアルタイムでの対話が求められるような用途では、この応答速度が課題となる可能性があります。
実装や運用・メンテナンスにコストがかかる可能性
手軽なプロンプトエンジニアリングを除き、本格的に社内データを学習させるためには、相応のコストがかかります。
RAGシステムを自社で構築する場合には、AIエンジニアの人件費や開発費用といった初期コストが必要です。
さらに、AIモデルのAPI利用料、ベクトルデータベースのサーバー維持費、データの更新や精度を維持するためのメンテナンス費用など、継続的なランニングコストも発生します。
専用ツールを導入する場合も、月額または年額のライセンス費用がかかります。
導入によって得られる業務効率化の効果と、これらのコストを比較検討し、費用対効果を見極めることが重要です。
「とりあえず導入してみよう」という見切り発車は避け、明確な目的と予算計画を立ててから進めるべきです。
失敗しないためのChatGPT社内データ学習における6つの注意点
ChatGPTへの社内データ学習を成功に導くためには、技術的な側面だけでなく、運用面や組織体制の整備も非常に重要です。
ここでは、導入で失敗しないために押さえておくべき以下の6つの注意点を解説します。
- 学習させるデータ範囲を適切に設定する
- 目的に合った最適なChatGPTのプランを選定する
- リスクを最小化するデータマネジメント体制を構築する
- 従業員向けの利用ルールやマニュアルを策定する
- 最新の技術動向を踏まえた定期的な見直しを行う
これらのポイントを事前に検討することで、スムーズかつ効果的なAI活用が実現できます。
学習させるデータ範囲を適切に設定する
AIは学習させたデータを忠実に反映するため、何を学習させるかが回答の質を直接的に決定します。
古くて現状と合わない情報、重複している内容、誤った情報などが含まれていると、AIもそれに基づいた不正確な回答を生成してしまいます。
導入の前には、まず学習対象とする社内ドキュメントを精査し、不要なデータを整理・削除する「データクレンジング」の作業が不可欠です。
また、どの範囲の情報をAIに参照させるかを明確に定義することも重要です。
例えば、「最新版の規定のみを対象とし、旧版は含めない」といったルールを設けることで、情報の混乱を防ぎ、回答の精度と信頼性を高めることができます。
目的に合った最適なChatGPTのプランを選定する
ChatGPTには、個人向けの無料プランやChatGPT Plusから、法人向けのChatGPT Team、ChatGPT Enterprise、そして開発者向けのAPIなど、様々なプランが存在します。
社内データを扱う上で、個人向けのプランを利用するのはセキュリティリスクの観点から絶対に避けるべきです。
基本的には、入力したデータがモデルの学習に使われないことが保証されているAPI経由での利用が前提となります。
その上で、セキュリティ要件が特に厳しい場合はAzure OpenAI Serviceを選択するなど、自社のコンプライアンスポリシーや目的に合致した最適なプランやサービスを選定することが重要です。
コストだけでなく、セキュリティ、機能、サポート体制などを総合的に比較検討しましょう。
リスクを最小化するデータマネジメント体制を構築する
AIを導入する際には、技術的な対策と同時に、社内のデータ管理体制を見直し、強化することが不可欠です。
まず、社内のドキュメントやデータに対して、機密度に応じたラベリング(例:「社外秘」「部外秘」など)を行い、誰がどの情報にアクセスできるのかを明確にする権限管理を徹底する必要があります。
AIに学習させるデータも、この権限設定に基づいて制御し、役職や部署によって参照できる情報の範囲を変えるといった仕組みが求められます。
例えば、人事評価に関するデータは人事部の担当者しかアクセスできないように制御するなど、AI利用においても既存のセキュリティポリシーを遵守する体制を構築することが、リスク管理の基本となります。
従業員向けの利用ルールやマニュアルを策定する
全社的にAI活用を推進するためには、従業員が安心して、かつ適切にツールを利用できるための明確なガイドラインが必要です。
このルールには、どのような情報を入力してはいけないのか(例:個人情報、顧客の機密情報)、AIの回答を鵜呑みにせず、最終的な判断は人間が行うべきであること、業務外での私的利用の禁止など、具体的な禁止事項や注意事項を盛り込む必要があります。
また、ツールの基本的な使い方や、効果的な質問の仕方(プロンプトのコツ)、トラブル発生時の報告先などを記載したマニュアルを作成し、全従業員に周知徹底することが重要です。
ルールを定めることで、セキュリティリスクを低減し、全社で一貫した利用を促進することができます。
最新の技術動向を踏まえた定期的な見直しを行う
生成AIの技術は日進月歩で進化しており、新しいモデルや機能が次々と登場します。
また、AI活用に関する法規制や社会的なガイドラインも変化していきます。
一度システムを導入し、ルールを策定したら終わりではなく、こうした外部環境の変化に追随していくことが重要です。
少なくとも半年に一度、あるいは年に一度は、導入しているシステムの性能や、社内の利用ルール、セキュリティポリシーが現状に即しているかを見直す機会を設けましょう。
より高性能なモデルにアップデートしたり、新しい活用方法を模索したりと、継続的に改善を続けることで、AI活用の価値を維持・向上させることができます。
ChatGPTの社内データ学習で実現できること・ビジネス活用法7選
社内データを学習させたChatGPTは、単なるチャットボットにとどまらず、様々な業務を効率化し、新たな価値を創出する強力なビジネスツールとなります。
ここでは、その具体的なビジネス活用法を以下の7つ厳選してご紹介します。
- 社内ナレッジ検索を効率化するAIチャットボット開発
- 顧客対応を自動化・高度化するカスタマーサポート
- リサーチ・翻訳・要約・分析業務の効率化
- 企画書やメールなど各種ドキュメントの自動作成
- ソフトウェア開発におけるコーディングやデバッグの補助
- 自律的に業務を遂行するAIエージェントの開発
- サービス機能の向上と新たな顧客体験の創出
自社の課題解決に繋がるヒントがきっと見つかるはずです。
社内ナレッジ検索を効率化するAIチャットボット開発
最も代表的で導入効果を実感しやすいのが、社内ナレッジ検索の効率化です。
業務マニュアル、社内規定、過去の議事録、日報など、社内に散在する膨大なドキュメントを学習させることで、「〇〇の経費申請方法を教えて」「△△という顧客との過去の取引履歴は?」といった質問に、AIが最適な回答を瞬時に提示してくれます。
これにより、社員が必要な情報を探すために費やしていた時間を大幅に削減できます。
特に、バックオフィス部門への定型的な問い合わせ対応を自動化することで、担当者はより専門的な業務に集中できるようになり、組織全体の生産性向上に大きく貢献します。
顧客対応を自動化・高度化するカスタマーサポート
製品のFAQ、マニュアル、過去の問い合わせ履歴などを学習させることで、24時間365日対応可能な高機能なカスタマーサポートAIを構築できます。
顧客からの定型的な質問にはAIが自動で回答し、複雑で個別対応が必要な問い合わせのみを人間のオペレーターに引き継ぐことで、サポート業務の効率を大幅に改善します。
さらに、AIがベテランオペレーターの対応ノウハウを学習することで、新人オペレーターでも質の高いサポートを提供できるよう支援することも可能です。
これにより、顧客満足度の向上と、サポート部門のコスト削減、オペレーターの負担軽減を同時に実現できます。
リサーチ・翻訳・要約・分析業務の効率化
大量のテキストデータを扱う業務においても、社内データを学習させたChatGPTは絶大な効果を発揮します。
例えば、特定のテーマに関する社内外のレポートやニュース記事を大量に読み込ませ、その要点を抽出・要約させることで、市場調査や競合分析にかかる時間を劇的に短縮できます。
また、過去の売上データや顧客アンケートの結果を学習させ、傾向を分析したり、新たなインサイトを抽出したりすることも可能です。
海外の文献を翻訳し、社内の文脈に合わせて自然な日本語に修正するといった作業も自動化できます。
これまで人手と時間がかかっていた知的労働の一部をAIに任せることができます。
企画書やメールなど各種ドキュメントの自動作成
過去に作成された質の高い企画書、提案書、報告書、メールの文面などをテンプレートとして学習させることで、各種ドキュメントの作成を自動化できます。
例えば、「A社向けの、B製品に関する提案書のたたき台を作成して」と指示するだけで、過去の成功事例に基づいた構成や表現を用いた質の高いドラフトを瞬時に生成します。
これにより、社員はゼロから文章を考える負担から解放され、内容のブラッシュアップや創造的なアイデア出しといった、より付加価値の高い業務に時間を使うことができます。
特に、営業部門や企画部門における資料作成業務のスピードアップに大きく貢献します。
ソフトウェア開発におけるコーディングやデバッグの補助
社内のコーディング規約、設計書、過去のソースコード、バグ報告書などを学習させることで、ソフトウェア開発のプロセスを強力に支援します。
エンジニアが実装したい機能の概要を伝えると、社内の標準的な規約に準拠したコードを自動で生成してくれます。
また、既存のコードに潜むバグや脆弱性を指摘したり、修正案を提案したりすることも可能です。
これにより、開発スピードの向上はもちろん、コードの品質標準化や、若手エンジニアの教育にも役立ちます。
開発チーム全体の生産性を底上げする、頼れるアシスタントとして機能します。
自律的に業務を遂行するAIエージェントの開発
さらに進んだ活用法として、自律的に業務を遂行する「AIエージェント」の開発が挙げられます。
これは、単一のタスクをこなすだけでなく、与えられた目標に対して、複数のツールやシステムを連携させながら、自律的に計画を立てて業務を処理するAIです。
例えば、「来週の大阪出張を手配して」と指示すると、AIエージェントが社内の出張申請システムにアクセスし、スケジュール管理ツールで空き時間を確認、交通機関や宿泊施設を予約サイトで検索・予約し、最終的な旅程を本人に報告するといった一連の作業を自動で完結させます。
定型的ながらも複数のステップを要する業務の完全自動化が視野に入ります。
サービス機能の向上と新たな顧客体験の創出
自社のサービスに、社内データを学習させたAIを組み込むことで、サービスの機能を向上させ、これまでにない新たな顧客体験を創出することも可能です。
例えば、ECサイトにおいて、顧客の購買履歴や閲覧履歴、さらには社内の商品知識を学習したAIが、一人ひとりの顧客に最適化された商品を推薦したり、専門的な質問にチャットで答えたりします。
また、教育サービスであれば、生徒の学習進捗データと教材データを基に、個々の理解度に合わせた最適な学習プランをAIが自動で生成するといった活用も考えられます。
AIを自社サービスのコア機能として活用することで、競合との差別化を図り、顧客エンゲージメントを高めることができます。
企業がChatGPTの社内データ活用事例6選【製造(食品・飲料・消費財)】
食品・飲料業界では、過去の膨大な商品開発データやマーケティング資料、消費者調査データをChatGPTに連携(RAG)させることで、新商品のアイデア出しや業務効率化に成功しています。
| 企業名 | 活用している社内データ | 主な活用用途・成果 |
| サントリーHD | 商品情報、業務マニュアル、ITヘルプデスク | 問い合わせ対応の自動化、企画アイデアの創出 |
| アサヒビール | 過去の技術情報、市場調査データ | 技術情報の検索時間短縮、商品コンセプト立案 |
| 日本コカ・コーラ | ブランドガイドライン、マーケティング資産 | 広告コピー・画像生成、戦略立案の高速化 |
| 日清食品HD | 営業活動履歴、市場データ | 「NISSIN-GPT」による商談資料作成、業務削減 |
| 江崎グリコ | 消費者アンケート、マーケティングデータ | データ分析業務の短縮、社内文書要約 |
| 六甲バター | 社内規定、総務・人事マニュアル | 社内問い合わせ対応の自動化、バックオフィス効率化 |
サントリーホールディングス株式会社
サントリーホールディングスは、マイクロソフトのAzure OpenAI Serviceを活用した対話型AI「サントリーGPT」を導入しています。
特筆すべきは、社内のイントラネットに散在していた業務マニュアルや商品データをAIに学習・参照させている点です。これにより、社員が「経費精算の方法は?」「過去の〇〇商品のスペックは?」と質問するだけで、社内規定に基づいた正確な回答が得られるようになりました。
IT部門や総務部門への問い合わせ件数が減少し、社員が本来のクリエイティブな業務に集中できる環境が整備されています。
会社HP:https://www.suntory.co.jp/
アサヒビール株式会社(アサヒグループ)
アサヒビールでは、R&D(研究開発)部門を中心に生成AIの活用が進んでいます。
過去数十年分にわたる技術報告書や実験データをデータベース化し、それをChatGPT等のLLMと連携させるシステムを構築しました。従来、研究員が過去の知見を探すのに数時間かかっていた作業が、対話型検索によって数分に短縮されています。
また、市場トレンドデータと社内技術を掛け合わせた新商品コンセプトのブレインストーミングにも活用され、イノベーションの加速に寄与しています。
会社HP:https://www.asahibeer.co.jp/
日本コカ・コーラ株式会社

日本コカ・コーラは、OpenAIとコンサルティング会社ベイン・アンド・カンパニーとの提携を通じ、生成AIをマーケティング領域で高度に活用しています。
社内のブランド資産(ロゴ、過去のキャンペーン画像、トーン&マナーのガイドライン)をAIに学習させ、ブランドイメージを損なわない広告コピーや画像の生成を実現しています。これにより、クリエイティブ制作のリードタイムが大幅に短縮され、変化の激しい市場ニーズに即座に対応可能な体制を構築しています。
日清食品ホールディングス株式会社
日清食品ホールディングスは、独自開発の対話型AI「NISSIN-GPT」をグループ全体で活用しています。
社内の営業活動履歴や市場データをセキュアな環境で連携させており、営業担当者が商談前に「〇〇チェーン向けの提案骨子を作成して」と指示するだけで、過去の成功事例に基づいた提案資料のドラフトが生成されます。これにより、資料作成にかかる時間が劇的に削減され、顧客との対話時間が増加するという成果が出ています。
会社HP:https://www.nissin.com/jp/
江崎グリコ株式会社
江崎グリコでは、マーケティング部門や企画部門において、社内に蓄積された膨大な消費者アンケートや調査データの分析にChatGPTを活用しています。
テキストデータとして保存されている「お客様の声」をAIに読み込ませ、要約や感情分析を行わせることで、商品改善のヒントを素早く抽出しています。また、社内会議の議事録要約や、企画書作成のサポートツールとしても定着しており、事務作業の効率化が進んでいます。
会社HP:https://www.glico.com/jp/
六甲バター株式会社
「Q・B・B」ブランドで知られる六甲バターは、バックオフィス業務の効率化に注力しています。
就業規則や経費規定などの社内ドキュメントを学習させたAIチャットボットを導入し、社員からの総務・人事関連の問い合わせを自動化しました。これにより、担当者が電話やメールで同じ質問に何度も答える手間が省け、本来注力すべきコア業務にリソースを割くことが可能になりました。中小規模の製造業においても、RAG(検索拡張生成)による業務効率化が可能であることを示す好例です。
企業がChatGPTの社内データ活用事例4選【製造(電機・機械・自動車)】
製造業の技術部門では、マニュアルや設計図書、過去のトラブル事例などの「技術資産」をAIに連携させ、技能伝承や品質向上に役立てています。
| 企業名 | 活用している社内データ | 主な活用用途・成果 |
| パナソニック コネクト | 全社イントラネット情報、法務・規定関連 | 法務相談、ITサポート、全社的な生産性向上 |
| トヨタ自動車 | 車両開発データ、技術資料、事務マニュアル | 企画書作成、プログラミング補助、技術検索 |
| オムロン | 技術マニュアル、ソフトウェアコード | 技術的問い合わせ回答、開発コード生成 |
| 旭鉄工 | 工場IoT稼働データ、改善事例 | ライン停止要因分析、現場改善案の創出 |
パナソニック コネクト株式会社
パナソニック コネクトは、日本企業としてはいち早く全社的にAIアシスタント「ConnectAI」を導入したことで知られます。
特筆すべきは、社内の規定集やイントラネット上の情報を検索対象とするRAG(Retrieval-Augmented Generation)の仕組みを早期に構築した点です。法務部門では契約書チェックの一次スクリーニングに活用したり、IT部門では社内ヘルプデスクの回答作成に利用したりと、社内データに基づいた高精度な回答を実現し、大幅な業務時間削減を達成しています。
会社HP:https://connect.panasonic.com/jp-ja/
トヨタ自動車株式会社

トヨタ自動車では、事務職から技術職まで幅広く生成AIを活用していますが、特に注目されるのが技術開発分野での社内データ活用です。
過去の車両開発における膨大な技術資料や実験データをAIに参照させる実証実験を進めており、設計上の過去トラブルの再発防止や、ベテランエンジニアの知見(ナレッジ)の検索性向上に取り組んでいます。また、プログラミング業務においても、社内独自のコーディング規約に沿ったコード生成支援を行い、開発スピードを向上させています。
会社HP:https://global.toyota/jp/
オムロン株式会社
オムロンは、自社製品(制御機器やヘルスケア機器)の技術マニュアルや過去の問い合わせ履歴をAIに学習させ、エンジニアやカスタマーサポートの支援を行っています。
特にソフトウェア開発領域では、社内の既存コードベースを参照させることで、バグの発見やコードのリファクタリング(整理)を効率化。また、顧客からの複雑な技術的質問に対し、膨大なマニュアルの中から関連箇所を即座に特定して回答案を作成するシステムにより、サポート品質の均一化を図っています。
会社HP:https://www.omron.com/jp/ja/
旭鉄工株式会社

自動車部品メーカーの旭鉄工は、IoTを活用した生産性向上で有名ですが、そこに生成AIを組み合わせています。
工場内のセンサーから収集した稼働データや、過去に行われた「カイゼン(改善)」事例のテキストデータをChatGPTに入力し、分析させています。「なぜラインが停止したのか」「どのような対策が有効か」といった問いに対し、過去の類似事例に基づいた改善案をAIが提示することで、現場担当者の意思決定を強力にサポートしています。
会社HP:https://www.asahi-tekko.co.jp/
企業がChatGPTの社内データ活用事例5選【金融(銀行・証券・カード)】
金融業界は規制が厳しく文書量が多いため、コンプライアンス規定や事務マニュアルの検索・照会業務におけるAI活用が進んでいます。
| 企業名 | 活用している社内データ | 主な活用用途・成果 |
| 三井住友FG | 行内規定、金融市場ニュース | 「SMBC-GPT」による照会応答、資料作成支援 |
| 三菱UFJ銀行 | 稟議書フォーマット、過去の社内文書 | 稟議書作成補助、文章校正、ナレッジ検索 |
| みずほFG | システム設計書、保守運用マニュアル | システム開発・保守の効率化、ドキュメント生成 |
| 大和証券 | コンプライアンス・ルール、海外市場情報 | 英語情報の要約、報告書作成、コンプラチェック |
| 横浜銀行 / 七十七銀行 | 銀行内事務規定、通達文書 | 営業店からの事務手続き問い合わせ対応の自動化 |
株式会社三井住友フィナンシャルグループ
三井住友フィナンシャルグループは、専用AI「SMBC-GPT」を導入し、行内の膨大な情報資産を活用しています。
数千ページに及ぶ銀行内の事務規定やマニュアル、コンプライアンス・ルールをAIにインデックス化させることで、行員が自然言語で質問するだけで必要な手続きを即座に回答するシステムを構築しました。これにより、本部への電話照会が減少し、支店業務のスピードアップと正確性の向上が実現しています。
株式会社三菱UFJ銀行
三菱UFJ銀行では、稟議書や報告書の作成業務において社内データを活用しています。
過去に作成された優秀な稟議書の構成や表現をAIに学習・参照させることで、若手行員でも質の高い稟議書を短時間で作成できるよう支援しています。また、行内に蓄積された膨大なドキュメントの中から必要な情報を探し出す「ナレッジ検索」としても機能しており、情報探索にかかるコストを大幅に削減しています。
株式会社みずほフィナンシャルグループ
みずほフィナンシャルグループは、システム開発・運用の領域で生成AIを積極的に活用しています。
過去のシステム設計書や運用マニュアルをAIに読み込ませることで、システム更新時の影響範囲調査や、テスト仕様書の自動生成などに役立てています。複雑化した銀行システムの保守業務において、社内技術ドキュメントをAIが解析・要約することで、エンジニアの負荷軽減とヒューマンエラーの防止につなげています。
会社HP:https://www.mizuho-fg.co.jp/
大和証券株式会社
大和証券は、全社員約9,000人が利用可能なAI環境を整備しています。
特に「英語のマーケット情報」や「海外の規制文書」を、社内ネットワーク内で安全に翻訳・要約させる活用が目立ちます。また、社内のコンプライアンス規定と照らし合わせた営業資料のチェックなど、金融機関特有の厳格なルール遵守をAIがサポートする体制を構築し、業務品質と効率の両立を図っています。
株式会社横浜銀行 / 株式会社七十七銀行
地方銀行においても、共同システムや独自の基盤を通じて社内データ活用が進んでいます。
横浜銀行や七十七銀行では、営業店から本部への事務手続きに関する問い合わせ対応に生成AIを活用しています。
頻繁に改定される事務通達や規定集をAIがリアルタイムで参照し、オペレーターや行員に対して最適な回答を提示することで、顧客を待たせないスピーディーな窓口対応を実現しています。
横浜銀行HP:https://www.boy.co.jp/
七十七銀行HP:https://www.77bank.co.jp/
企業がChatGPTの社内データ活用事例3選【建設・不動産】
建設業界では、現場ごとの施工記録や安全法令などのドキュメントをAIに読み込ませ、現場監督の事務負担軽減に注力しています。
| 企業名 | 活用している社内データ | 主な活用用途・成果 |
| 大林組 | 過去の工事実績、施工要領書、安全法規 | 施工計画書の作成支援、現場での法規確認 |
| 竹中工務店 | 建物設備データ、設計図書、議事録 | ビルメンテ業務効率化、設計補助、技術伝承 |
| 西松建設 | 社内会議議事録、技術文書 | 議事録要約・タスク抽出、技術情報検索 |
株式会社大林組

大林組は、「Obayashi AI」などの名称で社内特化型の生成AIを運用しています。
過去の工事実績データや膨大な施工要領書、安全衛生法などの法規データをAIに連携させています。現場監督が施工計画書を作成する際、AIが過去の類似案件のデータを参照してドラフトを作成したり、安全管理上の注意点を指摘したりすることで、長時間労働が課題となる建設現場の働き方改革を推進しています。
会社HP:https://www.obayashi.co.jp/
株式会社竹中工務店
竹中工務店では、設計データや施工記録に加え、ビルメンテナンス業務における設備データもAI活用しています。
過去の不具合対応履歴や設備マニュアルをAIに学習させ、ビル管理スタッフがトラブル発生時に迅速な対応策を検索できる仕組みを構築。「建設承認メタバース」構想などと合わせ、ベテラン社員が持つ暗黙知(技術ノウハウ)をデジタル化し、AIを通じて若手に継承する取り組みを行っています。
会社HP:https://www.takenaka.co.jp/
西松建設株式会社

西松建設は、全社的なAI導入により、日々の業務で発生する大量のテキストデータの処理を効率化しています。
特に社内会議の議事録データや技術文書をAIに参照させ、重要な決定事項やネクストアクション(次のタスク)を自動抽出する仕組みを活用しています。また、過去の技術トラブル事例を検索しやすくすることで、設計・施工段階でのリスク回避に役立てています。
会社HP:https://www.nishimatsu.co.jp
企業がChatGPTの社内データ活用事例5選【IT・通信・サービス・その他】
IT・通信業界では、エンジニアの支援だけでなく、コールセンターの顧客対応データや営業ナレッジを活用した事例が豊富です。
| 企業名 | 活用している社内データ | 主な活用用途・成果 |
| ソフトバンク | 営業ノウハウ、契約書DB、コールセンターログ | 契約審査自動化、営業提案書作成、CC支援 |
| KDDI | サービス仕様書、社内FAQ、社員情報 | 「KDDI AI-Chat」による社内問い合わせ対応 |
| LINEヤフー | 社内Wiki、開発ドキュメント | 社内知識を前提としたQA、コード生成 |
| JR西日本CS | 顧客からの入電内容(音声データ) | 通話内容の要約・分類、FAQ候補提示 |
| セブン‐イレブン | 店舗運営マニュアル、過去指導記録 | OFC(指導員)の店舗分析・指導業務支援 |
ソフトバンク株式会社

ソフトバンクは、国内最大級の社内AI活用を行っています。
営業部門では過去の優れた提案書や営業トークのデータをAIに学習させ、個々の顧客に合わせた提案資料を自動生成しています。また、法務部門との連携により、契約書データベースを参照して条文審査を半自動化したり、コールセンターの通話ログを分析してオペレーターへの回答支援を行ったりと、全部門で社内データを徹底活用しています。
KDDI株式会社

KDDIは、「KDDI AI-Chat」を導入し、セキュアな環境で社内データを活用しています。
人事制度や経理処理、社内システムの利用方法など、社内イントラネット上のFAQやマニュアルをAIと連携。社員がチャットで質問するだけで即座に回答が得られるため、バックオフィス部門の問い合わせ対応工数が大幅に削減されました。また、AWS等と連携し、機密情報を保持したままAIを利用する基盤を整えています。
LINEヤフー株式会社
LINEヤフーでは、エンジニア向けの活用だけでなく、全社的なナレッジ共有にAIを用いています。
社内のWikiやプロジェクト管理ツール上のドキュメントをRAG(検索拡張生成)の技術でAIに検索させ、社内固有の用語やプロジェクトの文脈を理解した上での回答を実現しています。これにより、新入社員のオンボーディング(早期戦力化)や、部署を跨いだ情報共有がスムーズに行われています。
会社HP:https://www.lycorp.co.jp/ja/
株式会社JR西日本カスタマーリレーションズ
JR西日本カスタマーリレーションズは、コールセンター業務において「お客様の声」という社内データを活用しています。
顧客との通話内容を音声認識でテキスト化し、そのデータをChatGPTに入力して自動で要約・分類を行っています。従来、オペレーターが手作業で行っていた記録業務(アフターコールワーク)の時間を大幅に短縮し、応対品質の向上とオペレーターの負担軽減を両立させました。
株式会社セブン‐イレブン・ジャパン
セブン‐イレブン・ジャパンは、店舗経営相談員(OFC)向けに生成AIシステム「Seven Central」を導入しています。
膨大な店舗運営マニュアルや、過去の指導事例、各店舗の販売データをAIが横断的に検索・分析します。OFCが移動中などに「今週のデザートの販売戦略は?」と問えば、AIがデータに基づいた具体的な指導案を提示するため、加盟店オーナーへのコンサルティングの質とスピードが向上しました。
企業のChatGPT活用事例をもっと幅広く知りたい方は、こちらの記事いも合わせてご覧ください。
企業がChatGPTの活用を成功させるための5つの鉄則
ChatGPTの導入を単なる「話題のツール導入」で終わらせず、実質的な「業務変革」へと繋げるためには、戦略的なアプローチが不可欠です。
成功企業が共通して実践している、導入プロジェクトを成功に導くための5つの重要ポイントを解説します。
| ポイント | 具体的なアクション | 期待される成果 |
| ① 業務の棚卸し | 現状の業務フローを可視化し、AI活用のインパクトを試算する | 「入れたけど使われない」を防ぎ、確実な時短効果を狙う |
| ② 領域の選定 | 生成AIの「得意・不得意」を見極め、高ROIな業務に絞る | 誤回答のリスクを避けつつ、最大の投資対効果を得る |
| ③ アジャイル導入 | いきなり完成形を目指さず、プロトタイプ作成と改善を繰り返す | 現場のニーズとシステムの乖離を防ぎ、実用性を高める |
| ④ リスク管理 | 「システム的な制御」と「運用ルール」の両輪で守る | 情報漏洩を防ぎながら、社員が安心して使える環境を作る |
| ⑤ リテラシー向上 | プロンプトエンジニアリング等の研修を継続的に実施する | AIのポテンシャルを最大限に引き出し、アウトプットの質を高める |
① 業務内容の棚卸しと活用インパクトの試算
ChatGPT活用の成否は、ツールを入れる「前」に決まっていると言っても過言ではありません。
「とりあえず導入しよう」と見切り発車するのではなく、まずは自社の業務フローを詳細に棚卸しすることが重要です。
どの業務に時間がかかっているのか、どの作業が定型的でAIに置き換え可能なのかを洗い出し、「この業務にAIを使えば、月間〇〇時間の削減になる」という定量的インパクトを事前に試算します。目的が明確であればあるほど、導入後の社内浸透スピードは格段に上がります。
② 投資対効果(ROI)の高い課題と活用方法の選定
ChatGPTは万能ツールではありません。「文章の要約」「アイデア出し」「プログラミング補助」は得意ですが、「正確な計算」「最新の事実確認」は(そのままでは)苦手です。
このAIの特性(得意・不得意)を正しく理解した上で、自社のどの課題に適用するかを選定する必要があります。「メールのドラフト作成」や「議事録の要約」など、AIの強みが活き、かつ業務頻度の高い領域からスモールスタートすることが、高い投資対効果(ROI)を生むための鉄則です。
③ アジャイルアプローチでの開発・導入
ChatGPTを活用したシステム開発では、最初から完璧な完成品を目指すべきではありません。AIモデルの進化スピードは速く、また現場の要望も実際に使ってみて初めて明確になることが多いからです。
まずは数週間単位で簡易的なプロトタイプ(試作品)を作成し、現場で使ってもらい、フィードバックを受けて改善する。このアジャイル(俊敏)なサイクルを回すことで、現場の業務実態に即した、本当に「使える」ツールへとブラッシュアップしていくことができます。
④ システムとルールの両面からのリスク管理
企業導入における最大のハードルは、情報漏洩や著作権侵害などのリスクです。しかし、これらを恐れて禁止するだけでは機会損失になります。重要なのは「マネジメント(管理)」です。
- システム面: API経由で利用し、入力データがAIの学習に使われない設定(オプトアウト)にする。
- ルール面: 「個人名は入力しない」「出力内容は必ず人間が確認する」といったガイドラインを策定する。
このように、技術的なガードレールと人的な運用ルールの両面から対策を講じることで、リスクを最小化しつつ活用を推進することが可能です。
⑤ 研修等での社員のAI活用リテラシーの向上
どれほど高性能なAIを導入しても、使い手である社員のスキルが不足していては宝の持ち腐れです。ChatGPTは、指示の出し方(プロンプト)ひとつで、回答の品質が天と地ほど変わります。
そのため、単にアカウントを配布するだけでなく、「AIリテラシー研修」や「プロンプトエンジニアリング講習をセットで提供することが不可欠です。「どのように質問すれば良い回答が得られるか」「AIのリスクはどこにあるか」を社員全員が理解することで、組織全体の生産性は飛躍的に向上します。
企業でChatGPTの社内データ学習を導入する4つのステップ
最後に、実際に企業がChatGPTへの社内データ学習を導入する際の具体的なプロセスを、以下の4つのステップに分けて解説します。
- Step1:活用目的と方針の明確化
- Step2:セキュリティを担保した利用環境の構築
- Step3:スモールスタートでの試験開発・運用(PoC)
- Step4:本格的な開発と全社的な運用展開
このステップに沿って計画的に進めることで、手戻りを防ぎ、着実に導入を成功させることができます。
Step1:活用目的と方針の明確化
最初のステップは、最も重要です。
「何のためにAIを導入するのか」「どの業務の、どのような課題を解決したいのか」という目的を具体的に定義します。
例えば、「バックオフィスへの問い合わせ対応工数を30%削減する」「営業部門の提案書作成時間を半分にする」といった、測定可能な目標を設定することが理想です。
また、この段階で、AI活用に関する全社的な基本方針(セキュリティポリシー、倫理ガイドラインなど)を定めておくことも重要です。
目的と方針が明確になることで、その後の技術選定や開発プロセスがブレなく進められます。
Step2:セキュリティを担保した利用環境の構築
次に、Step1で定めた目的と方針に基づき、安全に利用できる技術基盤と環境を構築します。
情報漏洩リスクを回避するため、Azure OpenAI Serviceのような法人利用を前提としたセキュアなプラットフォームを選定することが一般的です。
自社のセキュリティ部門と連携し、既存のネットワーク環境や認証基盤とどのように統合するのかを設計します。
この段階で、データ管理体制やアクセス権限のルールも具体的に定義し、技術的な実装に落とし込んでいきます。
安全性の確保は、AI活用の絶対条件です。
Step3:スモールスタートでの試験開発・運用(PoC)
いきなり全社的に大規模なシステムを導入するのではなく、まずは特定の部署や限定された用途で試験的に導入し、その効果を検証する「PoC(Proof of Concept:概念実証)」から始めることが成功の秘訣です。
例えば、「人事部の社内規定に関する問い合わせ対応」といった具体的なテーマを設定し、小規模なRAGシステムを構築してみます。
このスモールスタートを通じて、技術的な課題や運用上の問題点を洗い出し、ユーザーからのフィードバックを収集します。
ここで得られた知見は、本格展開に向けた計画をより現実的で精度の高いものにするための貴重なデータとなります。
Step4:本格的な開発と全社的な運用展開
PoCで有効性が確認できたら、いよいよ本格的な開発と全社展開に進みます。
PoCの結果を踏まえてシステムを改修・拡張し、より多くの従業員が利用できる安定した環境を構築します。
同時に、全従業員を対象とした利用マニュアルの整備や研修会を実施し、AIリテラシーの向上と利用促進を図ります。
また、導入後も利用状況をモニタリングし、定期的にユーザーからの意見をヒアリングする場を設けることが重要です。
AIは導入して終わりではなく、現場で使われ、継続的に改善していくことで、その価値を最大限に発揮するのです。
まとめ
企業がChatGPTに社内データを学習させたいと考える一方で、「情報漏洩のリスクが怖い」「RAGやファインチューニングなど専門的な知識を持つ人材がいない」といった理由で、導入の第一歩を踏み出せずにいるケースは少なくありません。
そこでおすすめしたいのが、Taskhubです。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
たとえば、社内マニュアルやFAQを学習させたAIチャットボットの開発、議事録の自動要約、提案書の自動作成など、さまざまな業務を「アプリ」として選ぶだけで、誰でも直感的にAIを活用できます。
しかも、Azure OpenAI Serviceを基盤にしているため、データセキュリティが万全で、情報漏えいの心配もありません。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「どのデータをどう学習させればいいのか」といった専門的な知見がない初心者企業でも安心してスタートできます。
導入後すぐに効果を実感できる設計なので、複雑なシステム開発や高度なAI知識がなくても、すぐに高精度な社内専用AI環境が構築できる点が大きな魅力です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最速の生成AI活用”を体験し、御社のDXを一気に加速させましょう。







