

「ChatGPTを自社の業務に活用したいけど、一般的な知識しかなくて使い物にならない…。」
「社内の専門知識をChatGPTに教えて、高精度な回答を生成させるにはどうすればいいの?」
こういった悩みを持っている方もいるのではないでしょうか?
本記事では、ChatGPTに専門知識を教える具体的な5つの方法と、それによって何が実現できるのか、さらに導入する際の注意点まで詳しく解説しました。
上場企業をメインに生成AIコンサルティング事業を展開している弊社が、実践的なノウハウをもとに解説します。
きっと役に立つと思いますので、ぜひ最後までご覧ください。
まずは基本から!ChatGPTの専門知識とは?
ここからは、ChatGPTが元々持っている知識と、なぜ専門知識を追加で学習させる必要があるのかについて解説します。
- ChatGPTが元々持っている知識の限界
- 追加学習で独自のナレッジベースを構築する重要性
基本を理解することで、自社に合った学習方法を選択しやすくなります。
それでは、1つずつ順に解説します。
ChatGPTが元々持っている知識の限界
ChatGPTは、インターネット上に存在する膨大なテキストデータを学習しており、非常に広範な知識を持っています。
しかし、その知識はあくまで「一般的」かつ「公開された」情報に限られます。
そのため、企業独自の社内ルールや非公開の製品情報、特定の業界でしか通用しない専門用語、2023年以降の最新情報などについては、正確に回答することができません。
この知識の偏りや時間的な制約が、ChatGPTをそのままビジネス利用する上での大きな壁となります。
こちらは、大規模言語モデル(LLM)が事実に基づかない情報を生成する「ハルシネーション」について、その分類、原因、および緩和策を包括的に調査したサーベイ論文です。合わせてご覧ください。 https://arxiv.org/pdf/2311.05232
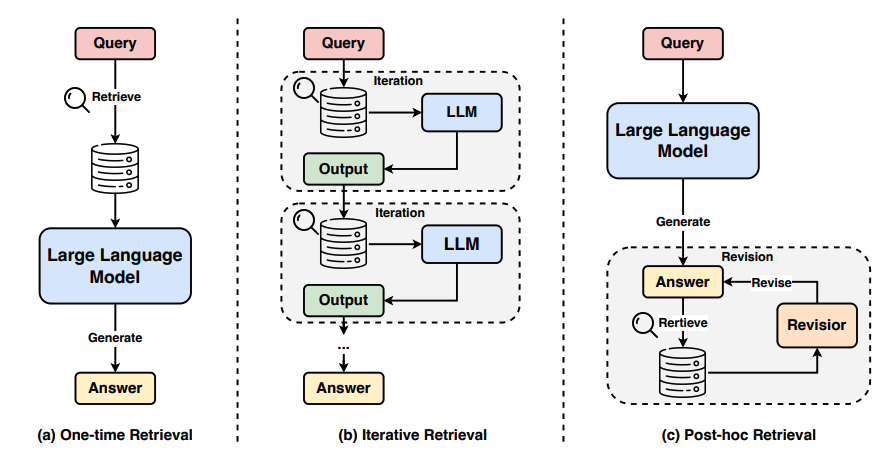
追加学習で独自のナレッジベースを構築する重要性
ChatGPTが元々持っている知識の限界を突破するために不可欠なのが、専門知識の追加学習です。
自社のマニュアルやFAQ、過去の問い合わせ履歴といった独自のデータを学習させることで、ChatGPTを「自社専用のAIアシスタント」としてカスタマイズできます。
これにより、一般的な応答しかできなかったChatGPTが、社内のエキスパートのように振る舞い、業務に特化した質問にも的確に答えられるようになります。
独自のナレッジベースを構築することは、業務効率化や顧客満足度の向上を実現するための第一歩と言えるでしょう。
ChatGPTに専門知識を学習させる5つの方法
ここからは、ChatGPTに専門知識を学習させる具体的な5つの方法を紹介します。
- プロンプトで直接情報を与える
- プラグインを利用して外部情報と連携する
- ファインチューニングでモデルを微調整する
- エンべディング(Embeddings)でベクトル化する
- 外部の専用ツールを導入する
それぞれの方法にメリット・デメリットがあるため、目的やコストに合わせて最適な手段を選ぶことが重要です。
それでは、1つずつ順に解説します。
方法①:プロンプトで直接情報を与える
最も手軽で基本的な方法が、プロンプト(指示文)の中で直接、必要な情報をChatGPTに提供することです。
例えば、「以下の資料を参考にして、質問に答えてください」といった形で、文章やデータをプロンプトに含めることで、その情報を基にした回答を生成させることができます。
この方法は、特別なツールや技術知識が不要で、誰でもすぐに試せるのが最大のメリットです。
ただし、プロンプトに入力できる文字数には上限があり、永続的に知識を記憶させることもできないため、一時的・限定的な利用に向いています。
方法②:プラグインを利用して外部情報と連携する
ChatGPTの有料プランで利用できる「プラグイン」を活用する方法もあります。
プラグインは、ChatGPTの機能を拡張する追加プログラムで、特定のウェブサイトの内容を要約したり、PDFファイルを読み込んだり、外部のデータベースにアクセスしたりすることが可能になります。
例えば、WebPilotのようなプラグインを使えば、リアルタイムでウェブ上の最新情報を取得し、それを基に回答を生成させることができます。
特定の外部サービスと連携させたい場合に有効ですが、自社内の閉じたネットワークにある情報にはアクセスできない点がデメリットです。
方法③:ファインチューニングでモデルを微調整する
ファインチューニングは、ChatGPTのモデル自体に独自のデータセットを追加学習させる、より高度な方法です。
特定のタスクや専門分野に合わせてモデルの応答スタイルや知識を「微調整」することで、より自然で精度の高い回答を生成できるようになります。
例えば、自社の過去の問い合わせ対応履歴を学習させることで、顧客サポートに特化した対話AIを開発できます。
モデル自体に知識が統合されるため高い性能が期待できますが、大量の学習データと技術的な専門知識、そして安くはないコストが必要になる点が大きなハードルです。
方法④:エンべディング(Embeddings)でベクトル化する
エンべディング(Embeddings)は、独自データを「ベクトル」という数値の羅列に変換してデータベースに保存しておく方法です。
ユーザーから質問があると、その質問と関連性の高い情報をベクトルデータベースから検索し、見つけ出した情報をプロンプトに含めてChatGPTに渡すことで、的確な回答を生成します。
この仕組みはRAG(Retrieval-Augmented Generation)と呼ばれ、ファインチューニングよりも少ないコストで、最新の情報を反映させやすいのが特徴です。
多くのAI活用ツールの裏側で使われている主要な技術となっています。
方法⑤:外部の専用ツールを導入する
自社でシステムを開発するのではなく、ChatGPTと連携済みの外部ツールやSaaSを導入する方法も有力な選択肢です。
これらのツールは、社内ドキュメントのアップロードやURLの指定だけで、簡単に自社専用のAIチャットボットを構築できる機能を提供しています。
開発にかかる時間や専門人材を必要とせず、セキュリティ対策もツール提供企業に任せられるため、手軽に導入できるのが最大のメリットです。
一方で、月額利用料などのランニングコストが発生し、ツールの仕様に依存するためカスタマイズの自由度は低くなります。
ChatGPTの専門知識学習の鍵「Embeddings」とは?
先ほど紹介した学習方法の中でも、特に重要度が高い「Embeddings」について、もう少し詳しく解説します。
- Embeddingsの仕組みをわかりやすく解説
- なぜEmbeddingsが重要なのか
この技術を理解することで、ChatGPTの専門知識活用の可能性がより明確に見えてきます。
Embeddingsの仕組みをわかりやすく解説
Embeddings(エンべディング)とは、文章や単語が持つ「意味」を、AIが理解できる数値の集まり(ベクトル)に変換する技術です。
例えば、「犬」と「イヌ」、「dog」は異なる文字列ですが、意味は非常に近いため、ベクトルに変換すると空間上で非常に近い位置に配置されます。
この仕組みを利用して、社内マニュアルやFAQなどの大量のテキストデータをあらかじめベクトル化しておきます。
そしてユーザーが質問をすると、その質問文もベクトルに変換し、ベクトル空間上で最も意味が近い情報を瞬時に探し出すことができるのです。
なぜEmbeddingsが重要なのか
Embeddingsが重要視される理由は、ハルシネーション(AIがもっともらしい嘘をつく現象)を抑制し、回答の正確性を担保する上で極めて効果的だからです。
ChatGPTは、あくまで外部から与えられた情報を基に回答を生成するため、事実に基づかない自由な創作を大幅に減らすことができます。
また、ファインチューニングのようにモデル自体を再学習させる必要がないため、情報の追加や更新が容易である点も大きなメリットです。
ビジネスの現場では、常に情報は変化するため、メンテナンス性の高さは非常に重要な要素となります。
ChatGPTの専門知識の学習に必要なデータ
ここからは、実際にChatGPTに専門知識を学習させる際に、どのようなデータが必要になるのかを解説します。
- テキストデータ(FAQ・マニュアル・論文など)
- 構造化データ(CSV・JSONなど)
- データの質と量が回答精度を左右する
精度の高いAIを構築するためには、適切なデータを準備することが不可欠です。
テキストデータ(FAQ・マニュアル・論文など)
最も一般的で活用しやすいのが、文章を中心としたテキストデータです。
これらは「非構造化データ」とも呼ばれ、特定のフォーマットを持たない自由な形式のデータを指します。
具体的には、社内の業務マニュアル、製品の取扱説明書、よくある質問と回答をまとめたFAQ、過去の問い合わせ履歴、研究論文、社内規定集などが挙げられます。
これらのテキストデータを学習させることで、AIは専門用語や業務の流れ、過去の事例を理解できるようになります。
構造化データ(CSV・JSONなど)
構造化データとは、CSVファイルのように行と列で整理されたデータや、JSON形式のように項目名と値がセットになった、構造が明確なデータのことです。
例えば、顧客リスト、製品カタログ、在庫データ、売上実績などがこれに該当します。
これらのデータを学習させることで、「〇〇という製品の価格は?」といった具体的な質問に対して、表の中から正確な情報を見つけ出して回答することが可能になります。
非構造化データと組み合わせることで、より幅広い質問に対応できるようになります。
データの質と量が回答精度を左右する
ChatGPTの回答精度は、学習させるデータの「質」と「量」に大きく依存します。
「Garbage In, Garbage Out(ゴミを入れればゴミしか出てこない)」という言葉があるように、情報が古かったり、誤りを含んでいたりするデータを学習させると、AIも不正確な回答を生成してしまいます。
また、データ量が少なすぎると、網羅性が低くなり、答えられない質問が多くなってしまいます。
精度を高めるためには、常に最新かつ正確な状態に保たれた、網羅性の高いデータを十分に用意することが成功の鍵となります。
こちらは、RAGシステムの性能を評価する上で、参照させるデータの品質が精度にどのような影響を与えるかを具体的に調査した研究論文です。合わせてご覧ください。 https://arxiv.org/html/2508.11758v1
ChatGPTの専門知識で実現できること
それでは、専門知識を学習させたChatGPTは、具体的にどのような場面で役立つのでしょうか。
ここでは、代表的な活用事例を4つ紹介します。
- 高度な問い合わせ対応の自動化
- 社内ナレッジ検索・業務の効率化
- 専門的な文章作成やリサーチの補助
- 【実践】ChatGPTの専門知識でSELECT文を作成
これらの事例を見ることで、自社での活用イメージがより具体的になるはずです。
高度な問い合わせ対応の自動化
自社製品の仕様やサービスに関するマニュアル、過去のFAQを学習させることで、高度な問い合わせに対応できるAIチャットボットを構築できます。
24時間365日、顧客からの専門的な質問に対して、担当者に代わって即座に一次回答を行うことが可能です。
これにより、顧客満足度の向上はもちろん、コールセンターのオペレーターやカスタマーサポート担当者の負担を大幅に軽減し、より複雑で個別対応が必要な業務に集中させることができます。
社内ナレッジ検索・業務の効率化
社内規定や業務マニュアル、過去の議事録といった膨大なナレッジを学習させることで、従業員向けの「何でも知っている社内アシスタント」を作成できます。
従業員は、知りたい情報を探して複数のファイルを開いたり、担当者を探して質問したりする必要がなくなり、自然な言葉でAIに質問するだけで必要な情報に素早くアクセスできます。
特に、新入社員のオンボーディングや、部署異動者への情報提供、複雑な社内手続きの確認といった場面で絶大な効果を発揮し、組織全体の生産性を向上させます。
専門的な文章作成やリサーチの補助
特定の業界に関する論文やレポート、法律の条文などを学習させることで、専門的な文章作成やリサーチ業務を強力にサポートします。
例えば、業界の慣習に沿った報告書のドラフトを作成させたり、膨大な資料の中から関連する情報だけを要約させたりすることが可能です。
企画書の作成、契約書のレビュー、技術仕様書の記述など、専門知識が求められるドキュメント作成にかかる時間を大幅に短縮し、本来注力すべきコア業務に多くの時間を割けるようになります。
【実践】ChatGPTの専門知識でSELECT文を作成
より実践的な例として、データベースのテーブル定義(テーブル名、カラム名、データ型など)をChatGPTに学習させるケースを考えてみましょう。
この知識を与えることで、SQLを直接書けない非エンジニアでも、自然言語で指示するだけでSQL文(SELECT文)を生成させることが可能になります。
例えば、「顧客マスターテーブルから、東京都在住で、かつ年齢が30歳以上のユーザーの氏名とメールアドレスを抽出して」と指示するだけで、ChatGPTが適切なSELECT文を自動で作成してくれます。
これにより、データ抽出業務が大幅に効率化されます。
ChatGPTに専門知識を学習させる際の注意点
多くのメリットがある一方で、専門知識を学習させる際にはいくつかの注意点も存在します。
導入を検討する際には、以下の3つのポイントを必ず押さえておきましょう。
- 回答の生成スピードが遅くなる可能性
- 実装やメンテナンスにコストがかかる
- 情報の正確性とセキュリティリスクの管理
これらのデメリットを理解し、対策を講じることが成功の鍵です。
回答の生成スピードが遅くなる可能性
Embeddings(RAG)の仕組みを利用する場合、ユーザーからの質問を受けるたびに、まずベクトルデータベースへ関連情報を検索しにいくというプロセスが発生します。
そのため、通常のChatGPTに直接質問するよりも、回答が生成されるまでに少し時間がかかる可能性があります。
利用するモデルやデータベースの性能、データの量にもよりますが、リアルタイムでの高速な応答が求められるシステムを構築する際には、この応答速度(レイテンシ)が許容範囲内であるか、事前に検証することが重要です。
実装やメンテナンスにコストがかかる
ファインチューニングやEmbeddingsを用いたシステムを自社で構築する場合、初期の開発コストがかかります。
AIやデータベースに関する専門知識を持つエンジニアの人件費や、クラウドサービスの利用料、OpenAI APIの利用料などが必要です。
また、導入後も学習させたデータが古くならないように、定期的に最新の情報へ更新するメンテナンス作業が不可欠であり、そのための運用コストも継続的に発生します。
これらのトータルコストを考慮した上で、投資対効果を見極める必要があります。
情報の正確性とセキュリティリスクの管理
専門知識を学習させた場合でも、ChatGPTのハルシネーション(もっともらしい嘘をつく現象)のリスクを完全にゼロにすることはできません。
そのため、生成された回答の根拠となった参照元ドキュメントを同時に提示するなど、ユーザーが情報の真偽を検証できる仕組みを設けることが推奨されます。
さらに、顧客情報や社外秘の技術情報といった機密性の高いデータを扱う場合は、厳重なセキュリティ対策が不可欠です。
アクセス権限の管理を徹底し、データが外部に漏洩しないようにセキュアな環境でシステムを構築・運用する必要があります。
こちらはChatGPTの利用における注意点やリスクについて解説した記事です。 合わせてご覧ください。 https://taskhub.jp/useful/chatgpt-caveat/
ChatGPTの専門知識を活かすプロンプト検証ツール
専門知識を学習させたChatGPTの性能を最大限に引き出すためには、優れたプロンプトを作成することが非常に重要です。
ここでは、そのプロンプト作成を効率化するための検証ツールについて解説します。
- おすすめのプロンプト検証ツール紹介
- ツール活用のメリット
適切なツールを活用することで、AIの導入効果をさらに高めることができます。
おすすめのプロンプト検証ツール紹介
プロンプト検証ツールやプロンプトエンジニアリング支援プラットフォームは、最適なプロンプトを効率的に見つけ出すための機能を提供します。
例えば、複数のプロンプトパターンを登録し、それぞれの回答結果を並べて比較・評価する機能があります。
また、同じプロンプトでも、モデルのパラメータ(Temperatureなど)を変更すると回答がどう変わるかをシミュレーションする機能や、回答の品質をスコアリングして定量的に評価する機能を持つツールもあります。
これにより、勘や経験だけに頼らない、データに基づいたプロンプトの最適化が可能になります。
ツール活用のメリット
プロンプト検証ツールを活用する最大のメリットは、プロンプト開発の属人化を防ぎ、組織としてノウハウを蓄積できる点にあります。
誰が作成しても一定の品質を担保できるような、標準化されたプロンプトのテンプレートを作成・管理することができます。
また、手作業で一つずつ試す場合に比べて、ABテストなどを通じて最適なプロンプトをはるかに高速に見つけ出すことができます。
これにより、開発サイクルが短縮され、AI活用の費用対効果を最大化することに繋がります。
こちらはそのまま使えるAIプロンプトのテンプレート集です。 合わせてご覧ください。 https://taskhub.jp/useful/ai-prompt-japanese/
専門知識を教えたAIは「優秀な部下」か、それとも「思考の鏡」か?
自社の専門知識を学習させたChatGPT、あなたはそれを「答えを教えてくれる便利な部下」だと思っていないでしょうか。実はその認識が、AI活用の成果を大きく左右する分かれ道かもしれません。せっかく構築した専用AIも、使い方を誤れば、ただ指示された範囲の情報を返すだけの「検索エンジン」に成り下がってしまいます。しかし、AIとの対話方法を少し変えるだけで、それはあなたの思考を刺激し、一人ではたどり着けない結論へと導く「最強の戦略パートナー」になり得ます。この記事では、AIに「答えさせる」のではなく「考えさせる」ための、一歩進んだ活用術を紹介します。
【警告】あなたの指示がAIを「指示待ち人間」にしている
専門知識を学習させたAIが、期待したほど賢くならない…。その原因はAIではなく、あなたの「聞き方」にあるかもしれません。次のような聞き方は、AIの能力に蓋をしてしまう典型的な例です。
- 単純な情報検索で終わる:「〇〇について教えて」これでは、AIはデータベースから関連情報を探し出すだけで思考を停止してしまいます。
- 結論だけを求める:「この企画の結論を出して」AIは最も無難な答えを提示するだけで、そこに新たな発見や深い洞察は生まれません。
- AIの答えを鵜呑みにする:「わかった、その通りに進めよう」AIが提示した答えの背景や根拠を問いたださなければ、ハルシネーションのリスクを見逃し、思考を深める機会を失います。
これらの使い方は、AIを「思考の外部委託先」として扱う行為であり、結果的にあなた自身の思考停止を招く危険性すらあります。
【実践】AIを「思考のパートナー」に変える3つの対話術
AIの真価を引き出す人は、AIを「答えの箱」ではなく「思考の壁打ち相手」として扱います。今日から試せる、AIの思考を深めるための3つの対話術を見ていきましょう。
対話術①:あえて「制約」を与えて思考の角度を変えさせる
AIに自由な発想を求めるのではなく、あえて難しい条件を課してみましょう。
プロンプト例:
「当社の新製品(〇〇)のプロモーション案を考えてください。ただし、広告予算はゼロ、SNSも一切使わないという制約で、最も効果的なアイデアを3つ提案してください。」
このような制約が、AIに普段とは違う思考回路を使わせ、創造的なアイデアを引き出すきっかけになります。
対話術②:「その結論に至った根拠は?」と論理的なステップを説明させる
AIが出した回答に対して、必ずその背景を尋ねる習慣をつけましょう。
プロンプト例:
「その3つのアイデアの中で、最も効果的だと判断した理由は何ですか?評価した際の基準と、それぞれのアイデアの論理的なつながりをステップバイステップで説明してください。」
これにより、AIの回答の妥当性を検証できるだけでなく、自分自身の思考プロセスも整理されます。
対話術③:「もし前提が違ったら?」と未来をシミュレーションさせる
AIに過去のデータを分析させるだけでなく、未来の可能性を探るパートナーとして活用します。
プロンプト例:
「もし、競合他社が同じような製品を半額で発売した場合、先ほどのプロモーション戦略はどのように変更すべきですか?考えられるリスクと、それに対する具体的な対策を挙げてください。」
AIとの対話を通じて未来のシナリオを検討することで、より強固で柔軟な戦略を練り上げることができます。
まとめ
ChatGPTに自社の専門知識を学習させ、業務に特化したAIアシスタントを構築したいというニーズは急速に高まっています。
しかし、本記事で紹介されたように、ファインチューニングやEmbeddingsといった手法を自社で実装するには、高度な技術知識や開発コスト、そして情報漏えいを防ぐための厳重なセキュリティ管理など、多くのハードルが存在します。
そこでおすすめしたいのが、Taskhub です。
Taskhubは、社内ドキュメントやURLをアップロードするだけで、専門知識を持ったAIを誰でも簡単に構築できる生成AI活用プラットフォームです。
たとえば、社内規定を学習させて総務への問い合わせを自動化したり、過去の提案書を学習させて営業資料の作成を効率化したりと、さまざまな業務を「アプリ」を選ぶ感覚でAIに任せられます。
しかも、Azure OpenAI Serviceを基盤にしているため、データセキュリティが万全で、機密情報も安心して扱うことができます。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「どのデータをどう使えばいいのか」といった専門的な部分から支援を受けられ、AI活用の知見がない企業でも安心してスタートできます。
プログラミングや難しい設定は一切不要で、導入後すぐに業務効率化を実感できる点が大きな魅力です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最も簡単で安全な自社専用AI”を体験し、御社のDXを一気に加速させましょう。







