

「Googleの次世代AI、Gemini 3.0って結局何がすごいの?」
「2025年8月にGPT-5が出たけど、今回のGemini 3.0はどう違うのかな…。」
こういった疑問を持っている方も多いのではないでしょうか?
本記事では、Gemini 3のスペック、衝撃の新機能「Deep Think」、開発者向けツール「Antigravity」、そして気になる料金プランまで、最新情報を余すところなく解説します。
AI技術の最新動向を日々追いかけている弊社が、2025年11月時点で出回っている情報を精査してまとめています。
この記事を読めば、Gemini 3.0に関する全ての情報がわかりますので、ぜひ最後までご覧ください。
Gemini 3.0の概要
ここではGemini3.0リリース内容の概要について、以下の流れで解説します。
- Gemini3.0リリースの概要
- Gemini3.0の性能は?GPT-5.1やClaudeを圧倒するベンチマーク
それでは、1つずつ解説していきます。
Gemini3.0リリースの概要
Gemini 3.0は、単なる性能向上にとどまらず、「推論」「エージェント」「マルチモーダル」の3点において劇的な進化を遂げた次世代AIモデルです。
- 圧倒的な推論能力: 専門家レベルの試験や複雑な論理パズルで世界最高スコアを記録。
- エージェント機能: 自律的に計画し、ツールを使い分け、長期的なタスクを遂行。
- マルチモーダル: テキスト、画像、音声、動画をシームレスに理解し、「空気を読む」レベルに到達。
今回のリリースでは、以下の構成が明らかになっています。
| モデル/ツール | 概要 | 対象 |
| Gemini 3 Pro | 最新の中核モデル。検索、Workspace、開発ツールで利用可能。 | 一般/開発者 |
| Gemini 3 Deep Think | 推論能力を極限まで高めた「熟考」モード。 | 上位プラン |
| Google Antigravity | エージェント型開発プラットフォーム(新IDE)。 | 開発者 |
こちらは「Google Japan Blog」がGemini3.0について解説した記事になります。CEOメッセージや具体的な機能について公式目線で書かれているため、Gemini3.0のリリース内容についてより詳しく知りたい方は合わせてご覧ください。
https://blog.google/intl/ja-jp/company-news/technology/gemini-3/#note-from-ceo
Gemini3.0の性能とは?GPT-5.1やClaudeとの比較結果
Googleは、Gemini 3 Proが「主要ベンチマークのすべてでGemini 2.5 Proを上回った」と発表しており、競合他社の最新モデルに対して圧倒的に優れているという結果になりました。
特に注目すべきは、独立評価「LMArena」でのElo 1501というスコアや、難関テスト「Humanity’s Last Exam」での結果です。
ベンチマーク項目 | Gemini 3 Pro | 備考 |
| LMArena (Elo) | 1501 | GPT-5.1等を上回る世界最高水準 |
| Humanity’s Last Exam | 37.5% | ツール非使用時。GPT-5 Pro (31.64%) を凌駕 |
| GPQA Diamond | 91.9% | 科学・物理・化学などの専門知識 |
| MMMU-Pro | 81.0% | マルチモーダル理解の指標 |
実際に以下のデータを見ても、主要なAIベンチマークのほぼ全てでトップの成績を叩き出しているのがわかります。
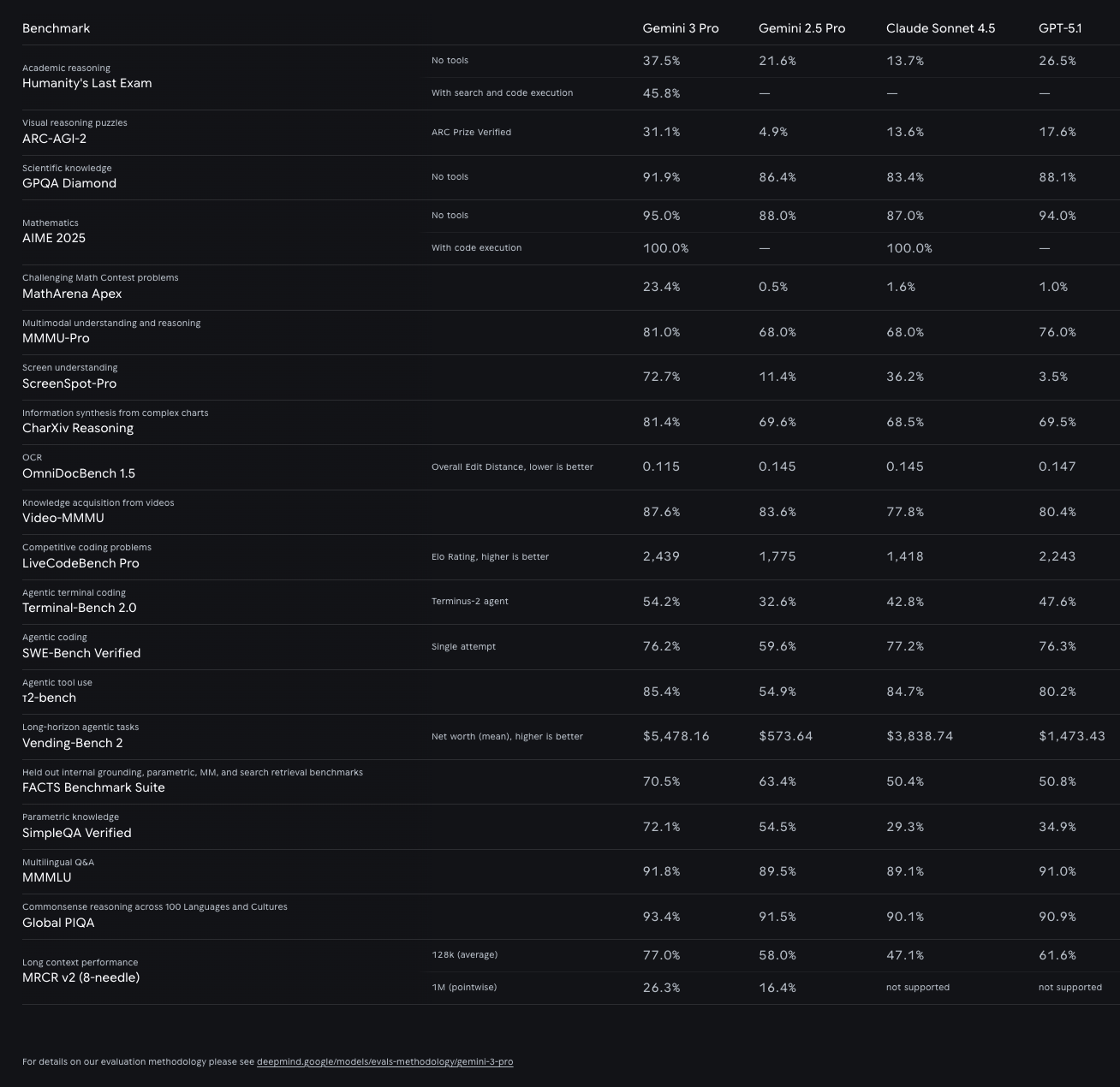
引用:Google DeepMind Gemini3.0 pro Performance
Gemini3.0リリースでの2つの新機能
Gemini 3のリリースに伴い、主に以下の2つのユーザー体験を大きく変える新機能が搭載されました。
- Gemini 3 Deep Think(ディープ・シンク)
- Google検索での「Generative UI」
では、1つずつ解説していきます。
① Gemini 3 Deep Think(ディープ・シンク)
通常のProモデルに加え、より時間をかけて深く思考する「Deep Thinkモード」が導入されました(Google AI Ultra加入者向け)。
人間が熟考するように問題をステップごとに分解・検証する「System 2」思考を行い、以下のような超難問で真価を発揮します。
- 活用例: 科学論文の読解、未解決の数学問題、複雑なコードのデバッグ。
- 性能: GPQA Diamondで93.8%、Humanity’s Last Examで41.0%を記録。
② Google検索での「Generative UI」
Gemini 3は発表当日からGoogle検索の「AI Mode」に採用されました。
「Generative UI」機能により、検索結果は単なるテキストリンクではなく、動的なインターフェースとして生成されます。
- 例: 「ゴッホについて」→ タップやスクロールで学べるインタラクティブな年表やギャラリーを生成。
- 例: ローン計算や物理シミュレーションなど、質問に応じたツールをその場で作成。
Gemini3.0の開発者向けの2つの新機能
エンジニアや開発者にとって、Gemini 3は「コーディング体験の革命」と言えます。以下2つの新機能が追加されました。
- 新IDE「Google Antigravity」
- Vibe Coding(バイブ・コーディング)
では、1つずつ解説していきます。
新IDE「Google Antigravity」
新IDE「Google Antigravity」は、Gemini 3を前提とした新しいエージェント型開発プラットフォームです。
エディター、ターミナル、ブラウザが統合されており、AIエージェントが「自律的に計画・コーディング・検証」を行います。開発者は高レベルな指示を出す「アーキテクト」としての役割に集中できます。
Vibe Coding(バイブ・コーディング)
Vibe Coding(バイブ・コーディング)は、ざっくりとした自然言語の指示(Vibe)から、完成度の高いコードを一発で生成する能力です。
- 実績: 「3D宇宙船ゲームを作って」の一言でHTML5ゲームが完成。「ピカチュウをSVGで描いて」で忠実なグラフィックを生成。
- 効率化: 100万トークンのコンテキストを活かし、巨大なコードベース全体を理解した上での改修が可能。
Gemini3.0の料金プランと利用方法
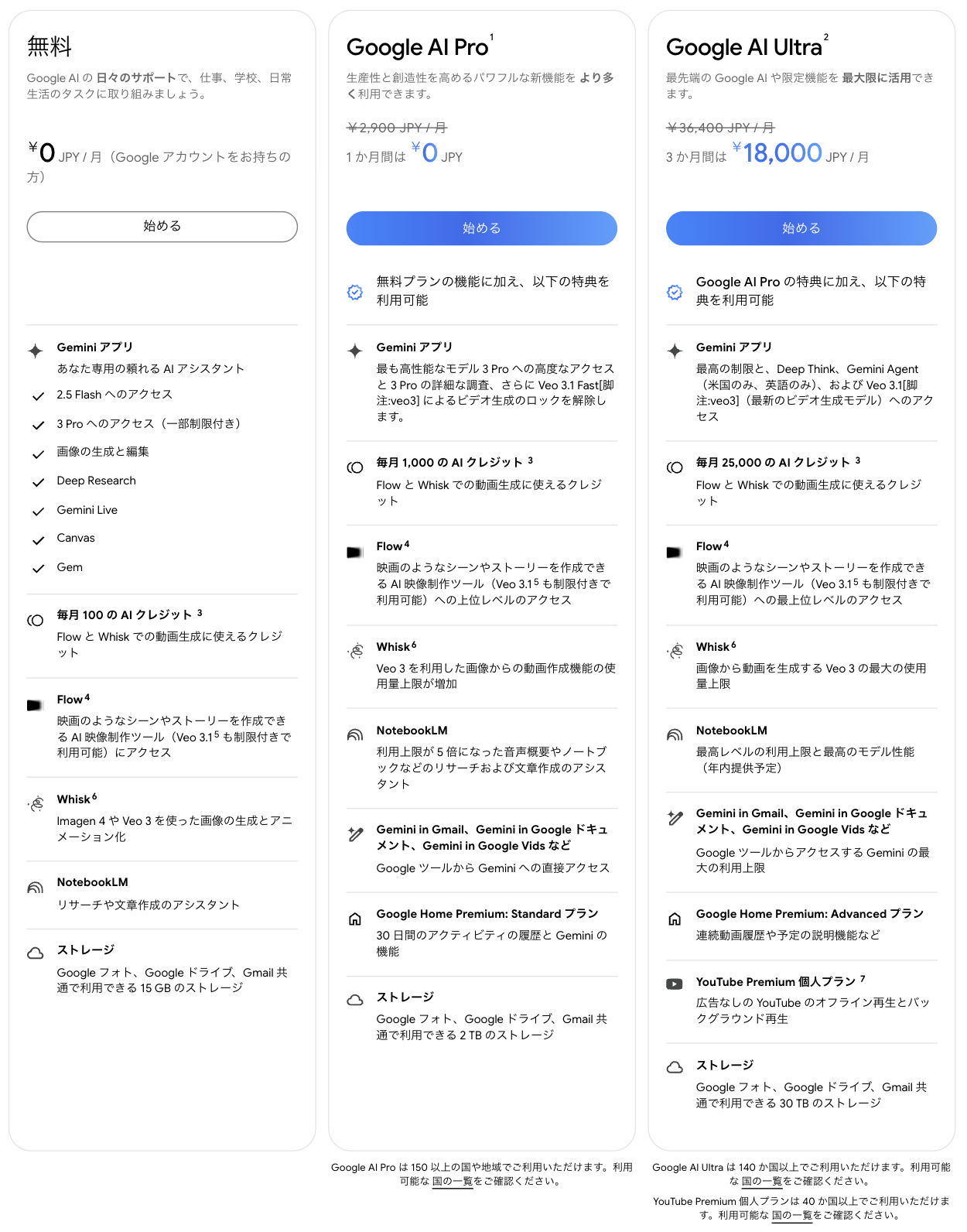
Gemini 3は、無料から利用可能ですが、高度な機能を使うにはプランのアップグレードが必要です。
一般ユーザー・ビジネス向けプラン
| プラン | 料金 (月額) | 主な特徴 | おすすめユーザー |
| 無料プラン | 0円 | Gemini 3 Pro (制限あり) 基本的なチャット・画像生成 | お試し利用 ライトユーザー |
| Google AI Pro | 2,900円 | Gemini 2.5 Proの高頻度利用 Deep Research機能 2TBストレージ | フリーランス 個人事業主 |
| Google AI Ultra | 36,400円 | Gemini 3 Deep Think Gemini Agent機能 動画生成(Veo 3)無制限 | 研究者 プロ開発者 |
注意: 学生向けには「Google AI Ultra」が2026年まで無料になるキャンペーンも実施中です。
こちらは実際のGemini料金プランのサイトになります。合わせてご確認ください。
Gemini3.0のAPI料金
開発者や企業がGemini 3.0をシステムに組み込む場合、APIの利用料金は従量課金制(Pay-as-you-go)となります。Gemini 3.0 Proは高性能モデルであるため、コストパフォーマンスと性能のバランスを考慮した価格設定になっています。
料金プラン概要
Google AI Studioを利用した検証段階では無料枠が用意されていますが、本格的な商用利用やプロダクション環境では以下の有料プランが適用されます。
Gemini 3.0 ProのAPI料金(100万トークンあたり)
入力(Input):2.00ドル 出力(Output):12.00ドル 画像・音声・動画入力:2.10ドル
従来のGemini 2.5 Proと比較すると約20%の価格上昇となっていますが、推論能力やマルチモーダル処理の精度が飛躍的に向上しているため、GPT-5シリーズなどの競合ハイエンドモデルと比較してもコストパフォーマンスに優れた設定と言えます。
また、プロンプトの長さ(コンテキストウィンドウの使用量)や、Batch API(バッチ処理)の利用有無によって価格が変動する場合があります。キャッシュ機能(Context Caching)を活用することで、入力コストを大幅に削減することも可能です。
無料枠について
Google AI Studioでは、レート制限(1分あたりのリクエスト数制限など)の範囲内でGemini 3.0 Proを無料で利用できるプランが継続して提供されています。プロトタイプの作成や、個人的な開発用途であれば、クレジットカード登録なしで即座に利用を開始できます。
最新の正確な料金体系や、無料枠の具体的な制限内容については、必ず以下の公式サイトで詳細をご確認ください。
参考リンク:Google AI Studio – Pricing(公式サイト) https://ai.google.dev/pricing

Gemini3.0とGemini Enterpriseプランの関係性
2025年11月のGemini 3.0リリースに伴い、企業向けプランであるGemini Enterpriseの価値も大きく向上しました。なぜビジネス利用において無料版ではなくEnterpriseプランが推奨されるのか、Gemini 3.0との具体的な関係性やメリットを解説します。
最新モデルGemini 3.0 Proが標準搭載へ
Gemini Enterpriseプランを契約している企業は、追加料金や複雑な設定なしで、バックエンドのAIモデルがGemini 3.0 Proへとアップグレードされます。
これにより、推論能力や日本語処理能力が飛躍的に向上した最新AIを、社内の全ユーザーが即座に業務利用できるようになります。特にGemini 3.0は論理的な思考力が強化されているため、従来のモデルでは難しかった複雑な市場分析や、法的文書のチェックといった高度な業務でも実用性が高まっています。
学習データに利用されない強固なセキュリティ
Gemini 3.0をビジネスで利用する際、最も重要なのがセキュリティです。無料版や個人向けプランでは、サービス向上のために会話データがGoogleの学習に利用される可能性があります。
しかし、Gemini Enterpriseプランを通じてGemini 3.0を利用する場合、入力したデータや生成された回答がGoogleのAIモデルの学習に使われることは一切ありません。機密情報、顧客データ、未発表の製品情報などを扱う業務でも、情報漏洩のリスクを排除して最新AIを活用できるのが最大の特徴です。
Workspaceアプリとの連携がより高度に
Gemini Enterpriseプランでは、Gmail、Googleドキュメント、スプレッドシート、スライドといったGoogle Workspaceアプリ内でGemini 3.0を直接呼び出せます。
Gemini 3.0の搭載により、この連携機能も強化されました。例えば、Gemini 3.0の優れたマルチモーダル機能により、スプレッドシートのグラフ画像を読み取って分析したり、ドライブ内の大量の資料を横断的に検索してドキュメントにまとめたりといった、エージェント的な動きがスムーズに行えるようになっています。
Vertex AIでの社内独自アプリ開発
Gemini Enterpriseには、開発者向けプラットフォームであるVertex AIの利用権も含まれています。企業はVertex AI経由でGemini 3.0のAPIを利用し、自社専用のチャットボットや業務システムを構築できます。
Gemini 3.0はコンテキストウィンドウ(記憶容量)が大きいため、社内の膨大なマニュアルや過去の議事録をすべて読み込ませた上で回答させるRAG(検索拡張生成)システムの構築にも最適です。これにより、汎用的な回答だけでなく、その企業特有のルールに則った正確な回答をGemini 3.0に行わせることが可能になります。
Gemini EnterPriseプランについて、こちらの記事で詳しく解説しているので、もっと知りたい方は併せてご覧ください。
Gemini 3に関するよくある質問
最後に、Gemini 3に関してユーザーから多く寄せられる質問について、2025年11月18日の公式発表に基づいた確定情報をまとめます。
Q1. Gemini 3は無料で使えますか?
はい、無料で利用可能です。 Googleは、最新の中核モデルであるGemini 3 Proを、Geminiアプリ(Web版・スマホ版)およびGoogle AI Studioを通じて無料ユーザーにも開放しています。ただし、利用回数などに一部制限がかかる場合があります。
一方で、さらに高度な推論を行う上位モードGemini 3 Deep Thinkや、複雑なタスクを自動化するGemini Agent機能を利用するには、有料プランであるGoogle AI Ultra(月額36,400円)への加入が必要となります。まずは無料版のGemini 3 Proで、その進化した性能を試してみるのがおすすめです。
Q2. リリース日はいつですか?
2025年11月18日(米国時間)に正式リリースされました。 Google公式ブログにて発表があり、同日より日本を含む世界中で利用が可能になっています。一般ユーザー向けのGeminiアプリだけでなく、開発者向けのAPIやGoogle検索(AI Mode)への統合も同時に開始されており、すでに誰でもすぐにアクセスできる状態です。
Q3. GPT-5とどちらが高性能ですか?
ベンチマークテストの結果においては、Gemini 3 Proが上回っています。 Googleの発表および独立系ベンチマークサイトLMArenaの結果において、Gemini 3 ProはEloスコア 1501を記録し、GPT-5.1やClaude Sonnet 4.5を抑えてランキング1位を獲得しました。
特に、専門家レベルの知識を問うHumanity’s Last Examや、科学領域のGPQA DiamondにおいてGPT-5シリーズを凌駕するスコアを出しています。また、GPT-5の特徴であるThinking(長考)機能に対しても、GoogleはDeep Thinkモードで対抗しており、推論能力においても互角以上の高い性能を示しています。
Q4. 日本語の精度は向上しますか?
はい、劇的に向上しています。 Gemini 3は多言語処理能力が強化されており、日本語特有の文脈の読み取りや、曖昧な表現の理解力が格段に上がっています。
さらにマルチモーダル性能の進化により、日本語の手書き文字(レシピやメモなど)の認識精度も向上しました。Deep Thinkモードを使えば、複雑な日本語の論文読解や、日本の商習慣に合わせた契約書の要約などにおいても、非常に高い精度を発揮します。
まとめ
企業は労働力不足や業務効率化の課題を抱える中で、生成AIの活用がDX推進や業務改善の切り札として注目されています。
しかし、実際には「どこから手を付ければいいかわからない」「社内にAIリテラシーを持つ人材がいない」といった理由で、導入のハードルが高いと感じる企業も少なくありません。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
たとえば、メール作成や議事録作成、画像からの文字起こし、さらにレポート自動生成など、さまざまな業務を「アプリ」として選ぶだけで、誰でも直感的にAIを活用できます。
しかも、Azure OpenAI Serviceを基盤にしているため、データセキュリティが万全で、情報漏えいの心配もありません。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「何をどう使えばいいのかわからない」という初心者企業でも安心してスタートできます。
導入後すぐに効果を実感できる設計なので、複雑なプログラミングや高度なAI知識がなくても、すぐに業務効率化が図れる点が大きな魅力です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最速の生成AI活用”を体験し、御社のDXを一気に加速させましょう。







