
「最近よく聞くLLMって何?ChatGPTとどう違うの?」
「LLMの仕組みやビジネスでの活用方法が知りたい…。」
こういった悩みを持っている方もいるのではないでしょうか?
本記事では、LLM(大規模言語モデル)の基本的な定義から、ChatGPTや生成AIとの違い、その仕組みや歴史、そして具体的なビジネス活用事例まで、初心者にも分かりやすく解説します。
さらに、利用時の注意点や導入を成功させるためのポイントについても触れています。
きっと役に立つと思いますので、ぜひ最後までご覧ください。
LLMとは何か?ChatGPTとの関係も含めて基本を解説
まず、LLMの基本的な意味や特徴、そしてなぜ今これほどまでに注目されているのかを解説します。
- LLM(大規模言語モデル)の簡単な定義と特徴
- 従来の言語モデルとの比較
- なぜ今LLMが注目されているのか
これらのポイントを理解することで、LLMが現代のテクノロジーにおいていかに重要な役割を果たしているかが明確になります。
それでは、1つずつ順に見ていきましょう。
LLM(大規模言語モデル)の簡単な定義と特徴
LLM(Large Language Models)とは、日本語で「大規模言語モデル」と訳されるAIの一種です。
その名の通り、膨大な量のテキストデータを学習させることで、人間のように自然な文章を生成したり、要約したり、翻訳したりする能力を持ちます。
LLMの最大の特徴は、その圧倒的なパラメータ数と学習データ量にあります。
これにより、文法的な正しさはもちろん、文脈やニュアンスを深く理解し、非常に高度で複雑な言語タスクをこなすことが可能です。
まるで人間と対話しているかのような、自然で滑らかな応答ができる点が、多くの人々を驚かせています。
従来の言語モデルとの比較
従来の言語モデルも、文章の生成や翻訳といったタスクを行ってきました。
しかし、その性能は限定的で、文法的に不自然であったり、文脈を無視した応答をしたりすることが少なくありませんでした。
これは、学習するデータの量やモデルの規模(パラメータ数)がLLMに比べてはるかに小さかったためです。
一方、LLMはインターネット上のテキスト全体に匹敵するような膨大なデータを学習します。
この莫大な知識量によって、専門的な質問への回答や、創造的な文章の作成など、従来モデルでは不可能だったタスクを実現しました。
質の高い応答能力が、LLMと従来モデルを分ける決定的な違いと言えるでしょう。
なぜ今LLMが注目されているのか
LLMが現在、世界的な注目を集めている最大の理由は、2022年11月にOpenAI社が公開した「ChatGPT」の登場です。
ChatGPTが示した、人間と遜色ない対話能力や文章生成能力は、社会に大きな衝撃を与えました。
この背景には、コンピュータの計算能力の飛躍的な向上と、「Transformer」という革新的な技術の登場があります。
これにより、従来では考えられなかったほどの巨大なモデルを効率的に学習させることが可能になりました。
ビジネスから日常生活まで、あらゆる場面での活用が期待されており、新たな産業革命の中核技術として世界中から注目されています。
LLMとは?ChatGPTや生成AIとの違いを徹底解説
ここからは、混同されがちな「LLM」「生成AI」「ChatGPT」という3つの言葉の違いと、それぞれの関係性について解説します。
- LLMと生成AIの違い
- LLMとChatGPTの違いと関係性
- ChatGPTはLLMの一種:その位置づけ
これらの関係性を正しく理解することで、AIに関するニュースや情報をより深く読み解けるようになります。
それでは、順番に解説していきます。
LLMと生成AIの違い
「生成AI(Generative AI)」とは、文章、画像、音声、プログラムコードなど、様々な新しいコンテンツを生成するAIの総称です。
つまり、何かを生み出す能力を持つAI全般を指す、非常に広い概念です。
一方、「LLM」は、その生成AIという大きな枠組みの中に含まれる一分野です。
LLMは、特に「言語(テキスト)」の生成に特化したモデルを指します。
したがって、画像生成AIや音声生成AIは生成AIですが、LLMではありません。
LLMは、生成AIの中でもテキスト処理を専門とする技術、と理解すると分かりやすいでしょう。
LLMとChatGPTの違いと関係性
「ChatGPT」は、LLMを活用して作られた具体的なアプリケーション(対話型AIサービス)の名前です。
開発したのは米国のOpenAI社で、ユーザーが入力した質問に対して、自然な対話形式で回答を生成します。
一方、「LLM」は、そのChatGPTを動かしている頭脳、つまり根幹となる技術そのものを指します。
例えるなら、LLMが「エンジン」で、ChatGPTがそのエンジンを搭載した「自動車」のような関係です。
私たちはChatGPTというサービスを通じて、その背後にあるLLMの驚異的な性能を体験しているのです。
ChatGPTはLLMの一種:その位置づけ
正しくは、ChatGPTはLLMを基盤として作られた「対話型AIサービス」です。
そして、ChatGPTが使用しているLLMのモデル名が「GPTシリーズ(例:GPT-4o)」です。
つまり、GPT-4oというLLM(エンジン)を使って、ChatGPTというアプリケーション(自動車)が動いています。
LLMにはGPTシリーズ以外にも、Googleの「Gemini」やAnthropic社の「Claude」など、様々な種類が存在します。
ChatGPTは、数あるLLM応用サービスの中で、最も成功し、広く知られるようになった代表的な事例と言えます。
この成功が、LLMという技術そのものへの注目を加速させました。
LLMとは?ChatGPTを動かす仕組みと動作原理を解説
ここからは、LLMがどのようにして人間のような文章を生成するのか、ChatGPTを動かす仕組みと動作原理を解説します。
- 言語処理の流れ1:トークン化
- 言語処理の流れ2:ベクトル化(埋め込み)
- 言語処理の流れ3:ニューラルネットワーク(Transformer)による学習
- 言語処理の流れ4:文脈理解と予測
- 言語処理の流れ5:デコードと自然な文章生成
- ファインチューニングによるLLMのカスタマイズ
この一連の流れを理解することで、LLMの能力の源泉が見えてきます。
それでは、1つずつ順に解説します。
言語処理の流れ1:トークン化
LLMが文章を処理する最初のステップは「トークン化(Tokenization)」です。
これは、入力された文章を、モデルが処理しやすい最小単位である「トークン」に分割する作業を指します。
例えば、「こんにちは、元気ですか?」という文章は、「こん」「にちは」「、」「元気」「です」「か」「?」のように分割されます。
英語の場合は単語単位で区切られることが多いですが、日本語の場合は単語や文節、あるいはより細かい単位で分割されます。
このトークン化によって、コンピュータは人間が使う自然な言葉を、計算可能なデータの集合として扱えるようになります。
言語処理の流れ2:ベクトル化(埋め込み)
次に、トークン化された各トークンは、「ベクトル化(Embedding)」というプロセスを経て、数値の羅列に変換されます。
ベクトルとは、向きと大きさを持つ数値の組み合わせのことで、AIはこの数値データを使って単語の意味や単語間の関係性を捉えます。
例えば、「王様」と「女王」という単語は、ベクトル空間上で非常に近い位置に配置されます。
さらに、「王様」から「男性」のベクトルを引き、「女性」のベクトルを足すと、「女王」のベクトルに近くなる、といった意味的な計算も可能になります。
このベクトル化によって、LLMは単なる文字列としてではなく、意味的な関連性を持ったデータとして言葉を扱えるようになります。
言語処理の流れ3:ニューラルネットワーク(Transformer)による学習
ベクトル化されたデータは、人間の脳神経を模した「ニューラルネットワーク」に入力され、学習が行われます。
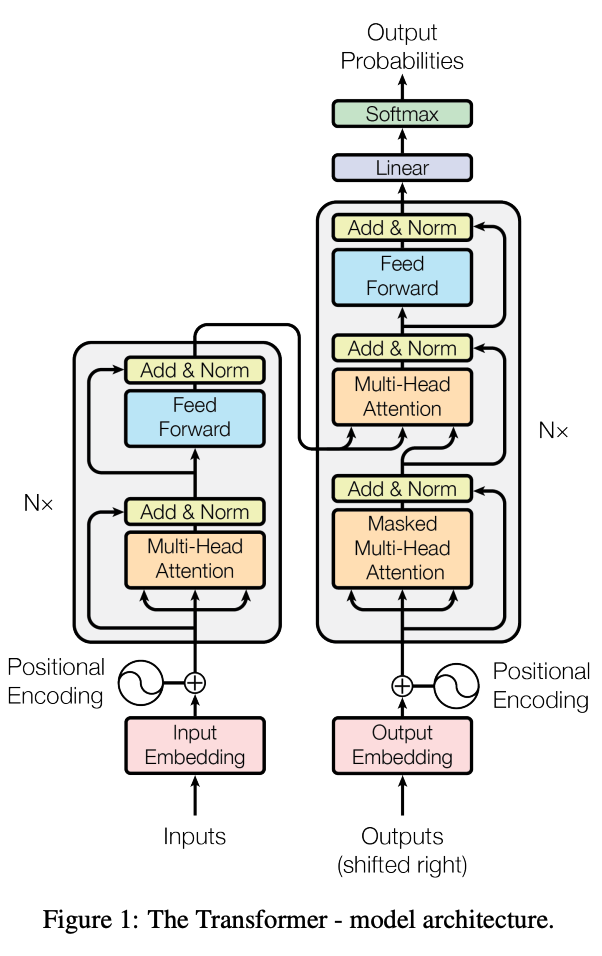
近年のLLMの進化を支えているのが、「Transformer(トランスフォーマー)」と呼ばれるニューラルネットワークのモデルです。
Transformerモデルの最大の特徴は、「Self-Attention(自己注意機構)」という仕組みにあります。
これにより、文章中のどの単語が他のどの単語と関連が深いのかを効率的に学習できます。
例えば、「彼がボールを蹴った」という文では、「彼」と「蹴った」の関連性が強いことを理解します。
この仕組みのおかげで、従来モデルが苦手としていた長い文章の文脈理解能力が飛躍的に向上しました。
こちらは、近年のLLMの進化を支えるTransformerモデルの仕組みを提唱した、歴史的に重要な論文です。 合わせてご覧ください。 https://papers.neurips.cc/paper/7181-attention-is-all-you-need.pdf
言語処理の流れ4:文脈理解と予測
Transformerモデルは、膨大なテキストデータを学習する過程で、単語と単語のつながりや文脈のパターンを統計的に学習します。
その結果、ある単語の次には、どのような単語が来る確率が最も高いかを予測できるようになります。
例えば、「今日の天気は晴れ、明日の天気は」という文章が与えられたら、学習したデータの中から「雨」「曇り」「晴れ」といった単語が続く確率が高いと予測します。
LLMの文章生成は、このようにして「次に来る確率が最も高い単語」を次々と予測し、つなぎ合わせていくことで行われています。
言語処理の流れ5:デコードと自然な文章生成
最後のステップが「デコード(Decoding)」です。
これは、モデルが予測した次に来る単語の確率分布から、最終的に出力する単語を決定し、文章として組み立てていくプロセスです。
最も確率の高い単語を常に選ぶ方法もありますが、それだけでは単調で面白みのない文章になりがちです。
そのため、ある程度のランダム性を持たせることで、より自然で創造的な文章を生成する工夫がなされています。
こうして、トークン化から始まった一連の処理を経て、LLMは人間が書いたような自然な文章を生成することができるのです。
ファインチューニングによるLLMのカスタマイズ
ファインチューニング(Fine-tuning)とは、既に大規模なデータで学習済みのLLMを、特定の目的や専門分野に合わせて追加で学習させ、性能を調整(カスタマイズ)する手法です。
「微調整」とも呼ばれます。
例えば、一般的なLLMに医療分野の専門論文を追加学習させることで、医療に関する専門的な質問にも高い精度で答えられる「医療特化LLM」を作成できます。
また、自社の問い合わせ履歴を学習させれば、独自のカスタマーサポート用AIを構築することも可能です。
ゼロからLLMを開発するには莫大なコストがかかりますが、ファインチューニングなら比較的低コストで、特定の業務に最適化された高性能なAIを実現できます。
ChatGPTの仕組みについては、こちらの記事でさらに詳しく解説しています。 ぜひ合わせてご覧ください。 https://taskhub.jp/useful/chatgpt-explanation/
LLMとは?ChatGPTの登場で注目される歴史と背景
ここからは、LLMがどのようにして生まれ、なぜ今これほど注目を集めるに至ったのか、その歴史と背景を紐解いていきます。
- LLMのこれまでの歴史
- LLMが注目されている背景
技術の進化の流れを知ることで、LLMの将来性や今後の可能性をより深く理解することができます。
LLMのこれまでの歴史
LLMの歴史は、自然言語処理(NLP)研究の進化と密接に関連しています。
2010年代前半までは、統計的な手法に基づく言語モデルが主流でした。
転換点となったのは、2017年にGoogleが発表した「Transformer」モデルです。
この革新的な技術により、大規模なデータを効率的に学習させることが可能になり、言語モデルの性能は飛躍的に向上しました。
2018年にはGoogleが「BERT」を、2020年にはOpenAIが「GPT-3」を発表し、その圧倒的な性能で世界を驚かせました。
そして2022年の「ChatGPT」の登場が、LLMの存在を一部の研究者だけでなく、一般社会にまで広く知らしめる決定的な出来事となったのです。
LLMが注目されている背景
LLMが注目される背景には、いくつかの要因が複合的に絡み合っています。
第一に、前述した「Transformer」モデルの登場と、GPUなどハードウェアの計算能力の向上により、巨大なモデルの学習が可能になった技術的進歩が挙げられます。
第二に、インターネットの普及により、学習に利用できる高品質なテキストデータが爆発的に増加したことがあります。
そして第三に、ChatGPTの登場により、LLMの驚異的な能力が可視化され、誰もがその利便性を手軽に体験できるようになったことです。
これにより、ビジネス活用の可能性が一気に広がり、世界的な開発競争が加速しているのです。
LLMとは?ChatGPT以外の主要なモデル具体例
ここからは、ChatGPTの基盤であるGPTシリーズ以外に、どのようなLLMが存在するのか、主要なモデルの具体例を紹介します。
- GPTシリーズ
- Gemini
- Claude
- Llama
- BERT
- 日本語対応LLMの現状
それぞれのモデルが持つ特徴を知ることで、目的に合ったLLMを選択する際の助けになります。
それでは、1つずつ見ていきましょう。
GPTシリーズ
GPT(Generative Pre-trained Transformer)シリーズは、ChatGPTを開発したOpenAI社によるLLMです。
自然な文章生成能力に非常に長けており、対話や創作といったタスクで高い評価を得ています。
2020年に発表されたGPT-3は、その後のLLM開発競争の火付け役となりました。
現在では、さらに性能が向上したGPT-4や、画像や音声も扱えるマルチモーダル対応のGPT-4oなどが提供されており、多くのアプリケーションの基盤技術として利用されています。
LLMの代名詞とも言える存在です。
こちらは、GPT-4の性能や開発経緯、安全性について詳細に記述されたOpenAI公式のテクニカルレポートです。 合わせてご覧ください。 https://cdn.openai.com/papers/gpt-4.pdf
Gemini
Gemini(ジェミニ)は、Googleが開発したLLMです。
最大の特徴は、開発当初からテキスト、画像、音声、動画などを統合的に扱える「マルチモーダルAI」として設計されている点です。
性能別に、最も高性能な「Ultra」、幅広い用途に対応する「Pro」、スマートフォンなどでの利用を想定した「Nano」の3つのモデルが用意されています。
Googleの各種サービス(Google検索、Google Workspaceなど)に深く統合されており、今後の展開が最も注目されるLLMの一つです。
Claude
Claude(クロード)は、元OpenAIのメンバーが設立したAnthropic社が開発したLLMです。
安全性や倫理性を重視した設計が特徴で、「Constitutional AI(憲法AI)」と呼ばれる手法を用いて、より丁寧で害の少ない回答を生成するように訓練されています。
また、一度に処理できるテキスト量(コンテキストウィンドウ)が非常に大きいことでも知られており、長文の文書読解や要約、複雑な指示の理解に優れています。
ビジネス文書の作成や分析など、信頼性が求められる場面での活用が期待されています。
Llama
Llama(ラマ)は、Meta社(旧Facebook)が開発し、オープンソースとして公開されているLLMです。
オープンソースであるため、誰でも自由にモデルをダウンロードし、研究や商用目的で利用・改変できるのが最大の特徴です。
これにより、世界中の開発者がLlamaをベースとした独自のLLMを開発することが可能になり、AI技術の民主化とイノベーションを促進しています。
性能も非常に高く、オープンソースLLMの分野で事実上の標準(デファクトスタンダード)としての地位を確立しつつあります。
こちらは、オープンソースLLMの代表格であるLlama 3の技術的な詳細について解説した、Meta AIによる公式論文です。 合わせてご覧ください。 https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
BERT
BERT(バート)は、2018年にGoogleが開発した言語モデルです。
文章中の単語をその前後両方の文脈から理解する「双方向」処理を実現した画期的なモデルで、その後のLLM開発に大きな影響を与えました。
文章生成よりも、文章の意味を正確に理解することに長けており、特にGoogle検索の検索精度向上に大きく貢献しました。
近年の文章生成を得意とするLLMとは少し役割が異なりますが、LLMの歴史を語る上で欠かせない重要なモデルです。
日本語対応LLMの現状
海外で開発されたLLMの多くは、主に英語のデータで学習されているため、日本語の扱いや日本の文化・社会に関する知識が不十分な場合があります。
この課題に対応するため、日本国内でも日本語に特化したLLMの開発が活発に進められています。
NTTが開発した「tsuzumi」や、Stability AI Japanが公開した「Japanese Stable LM」、サイバーエージェントの「calm2」などがその代表例です。
これらのモデルは、日本の商習慣や文化的背景を理解しているため、より自然で適切な日本語の文章を生成できると期待されています。
LLMとは?ChatGPTのビジネス活用事例
ここからは、LLMやChatGPTが実際のビジネスシーンでどのように活用されているのか、具体的な事例を6つ紹介します。
- テキストの作成・校正・要約
- 市場調査・情報収集
- プログラミングの補助
- カスタマーサポートの効率化
- 広告・マーケティングのクリエーティブ制作
- 教育・学習支援
自社の業務にどのように応用できるか、イメージしながらご覧ください。
テキストの作成・校正・要約
LLMが最も得意とする分野の一つが、テキスト関連の業務です。
メールの文面、ブログ記事、プレスリリース、報告書など、あらゆる文章の草案を瞬時に作成できます。
また、既存の文章を入力し、誤字脱字のチェックや、より自然な表現への修正を依頼することも可能です。
長文の会議議事録や調査レポートを数行の箇条書きに要約させることもでき、情報整理の時間を大幅に削減します。
これらの活用により、ライティング業務の生産性は劇的に向上します。
市場調査・情報収集
LLMは、膨大な知識を活かして、リサーチ業務のアシスタントとしても活躍します。
特定の業界の市場動向や、競合他社の最新情報を尋ねれば、インターネット上の情報を基に整理して提示してくれます。
例えば、「日本のEV市場の今後の展望について教えて」と質問すれば、関連する情報をまとめてくれます。
複数のウェブサイトを横断して情報を探す手間が省け、効率的な情報収集が可能になります。
ただし、情報の鮮度や正確性には注意が必要なため、最終的なファクトチェックは人間が行うことが重要です。
プログラミングの補助
LLMは、プログラミングの分野でも強力なツールとなります。
実現したい機能や仕様を自然言語で伝えるだけで、対応するプログラムコードを生成してくれます。
これにより、プログラミングの専門知識が少ない人でも、簡単なツール開発が可能になります。
また、既存のコードにエラー(バグ)があった場合に、その原因を特定し、修正案を提示させることもできます。
コードの仕様書(ドキュメント)を自動生成させるなど、開発プロセス全体の効率化に貢献し、エンジニアがより創造的な作業に集中できる環境を整えます。
カスタマーサポートの効率化
カスタマーサポートの領域では、チャットボットへのLLM導入が進んでいます。
従来のシナリオ型チャットボットとは異なり、LLM搭載のチャットボットは、定型外の複雑な質問にも人間のように自然な対話で応答できます。
これにより、「よくある質問」への対応を24時間365日自動化し、オペレーターの負担を大幅に軽減します。
オペレーターは、より専門的で複雑な問い合わせに集中できるようになり、顧客満足度の向上とサポート部門の生産性向上の両立が期待できます。
広告・マーケティングのクリエーティブ制作
広告やマーケティングの分野では、クリエーティブなアイデア出しやコンテンツ制作にLLMが活用されています。
ターゲット顧客や商品の特徴を伝えるだけで、キャッチコピーやSNS投稿文、メールマガジンの文面などを複数パターン提案してくれます。
また、広告キャンペーンの企画案や、ペルソナ設定のアイデア出しなど、ブレインストーミングの相手としても非常に有効です。
制作プロセスの初動を早め、人間のクリエイターがより洗練されたアイデアを生み出すための時間的・精神的余裕を生み出します。
教育・学習支援
教育分野では、個々の学習者の理解度や進捗に合わせた、パーソナライズされた学習支援ツールとしてLLMの活用が期待されています。
生徒からの質問に対して、対話形式で分かりやすく解説したり、理解度を確認するための練習問題を自動で生成したりすることができます。
また、語学学習の相手として、自由に会話練習をすることも可能です。
教員の負担を軽減しつつ、生徒一人ひとりに寄り添った質の高い教育を提供する上で、LLMは大きな可能性を秘めています。
LLMとは?ChatGPT利用時の問題点と注意点(課題)
LLMやChatGPTは非常に便利なツールですが、その利用にはいくつかの問題点や注意すべき課題も存在します。
- ハルシネーション(もっともらしい嘘)のリスク
- セキュリティとプライバシーに関する注意点
- 法的・倫理的リスク(著作権など)
- 情報の正確性とバイアスの課題
これらのリスクを正しく理解し、適切な対策を講じることが、安全なLLM活用の鍵となります。
ハルシネーション(もっともらしい嘘)のリスク
ハルシネーションとは、LLMが事実に基づかない情報を、あたかも真実であるかのように、もっともらしく生成してしまう現象です。
「幻覚」を意味する英語に由来します。
LLMは、学習データに基づいて「次に来る確率が最も高い単語」を予測して文章を生成する仕組みのため、情報の正しさを保証するものではありません。
存在しない事件や人物、論文などを創作してしまうことがあります。
ビジネスで利用する際は、生成された情報が正確かどうかを必ず人間の目で確認(ファクトチェック)するプロセスが不可欠です。
ハルシネーションを防ぐ具体的な方法については、こちらの記事で詳しく解説しています。 合わせてご覧ください。 https://taskhub.jp/use-case/chatgpt-prevent-hallucination/
セキュリティとプライバシーに関する注意点
多くのLLMサービスでは、入力された情報がモデルの再学習に利用される可能性があります。
そのため、ChatGPTなどの外部サービスに、企業の機密情報や個人情報を入力してしまうと、情報漏えいのリスクにつながります。
また、企業の内部情報を学習させた独自のLLMを構築した場合でも、質問の仕方によっては、本来アクセス権限のないユーザーに機密情報が出力されてしまう可能性も否定できません。
利用ルールの策定や、セキュリティが確保された法人向けサービスの選定が重要です。
法的・倫理的リスク(著作権など)
LLMが生成した文章や画像が、学習データに含まれる既存の著作物と酷似してしまうケースがあり、意図せず著作権を侵害してしまうリスクが指摘されています。
生成物を利用する際には、他者の権利を侵害していないか慎重に確認する必要があります。
また、LLMを利用して差別的・攻撃的なコンテンツが生成される可能性や、フェイクニュースの拡散に悪用されるといった倫理的な課題も存在します。
LLMの生成物を公表する際には、社会的な影響を考慮する責任が求められます。
情報の正確性とバイアスの課題
LLMの学習データには、インターネット上に存在する膨大なテキストが使われていますが、その情報がすべて正確で中立的であるとは限りません。
そのため、学習データに含まれる誤った情報や、特定の思想・文化に基づく偏見(バイアス)を、LLMがそのまま学習・再生産してしまう可能性があります。
生成された回答が、特定の性別、人種、思想に対して偏った見方を反映してしまうことがあります。
LLMの出力はあくまで一つの参考情報と捉え、多様な視点からその内容を批判的に吟味することが重要です。
LLMとは?ChatGPTをビジネス導入する際のポイント
ここからは、LLMやChatGPTを自社のビジネスに導入し、成果を出すために押さえておくべきポイントを解説します。
- 導入目的を明確にする
- 柔軟な改善サイクルを構築する
- 最新モデルへの追従戦略を立てる
- 専門家との連携の重要性
これらのポイントを意識することで、導入の失敗リスクを減らし、LLMの価値を最大限に引き出すことができます。
導入目的を明確にする
LLM導入を成功させるための最初のステップは、「どの業務課題を解決するためにLLMを使うのか」という目的を明確にすることです。
「流行っているから」といった曖昧な理由で導入を進めても、具体的な成果にはつながりません。
「カスタマーサポートの一次対応を自動化して、応答率を90%以上にしたい」「記事作成の時間を30%削減したい」など、具体的で測定可能な目標を設定することが重要です。
目的が明確であれば、導入すべきツールや評価指標もおのずと定まります。
柔軟な改善サイクルを構築する
LLMは万能ではなく、導入してすぐに完璧な結果が出るわけではありません。
まずは特定の部署や業務に限定して小さく導入を開始し(スモールスタート)、実際に使ってみて得られたフィードバックを基に、使い方やプロンプト(指示文)を改善していくサイクルを回すことが重要です。
実際に使ってみると、想定外の課題や、逆に新たな活用アイデアが見つかることもあります。
現場の意見を吸い上げながら、継続的に改善を繰り返すアジャイルなアプローチが、LLMの業務定着を成功させる鍵となります。
最新モデルへの追従戦略を立てる
LLMの技術は日進月歩で、数ヶ月単位で新しい、より高性能なモデルが登場します。
特定のモデルやサービスに依存しすぎると、技術が陳腐化してしまい、競争力を失うリスクがあります。
そのため、APIなどを活用して、必要に応じてバックエンドで利用するLLMを柔軟に切り替えられるようなシステム設計を検討することが望ましいです。
常に最新の技術動向を注視し、コストと性能のバランスを見ながら、自社にとって最適なモデルを選択し続ける戦略的な視点が求められます。
最新モデルのChatGPT-4oについては、こちらの記事で詳しく解説しています。 合わせてご覧ください。 https://taskhub.jp/useful/chatgpt-4o/
専門家との連携の重要性
LLMをビジネスに深く組み込むには、AIに関する技術的な知見だけでなく、自社の業務プロセスへの深い理解も必要です。
しかし、これら両方のスキルを兼ね備えた人材は非常に希少です。
そのため、自社だけで全てを完結させようとせず、LLMの導入支援を専門とする外部のコンサルタントや開発パートナーと連携することも有効な選択肢です。
専門家の知見を活用することで、導入の失敗リスクを低減し、より早く、より大きな成果を得ることが可能になります。
LLMとは?ChatGPTが拓く技術の将来性
最後に、LLMという技術が今後どのように進化し、私たちのビジネスや社会にどのような未来をもたらすのかを展望します。
- LLMの進化がビジネスにもたらす未来
- LLMを活用してビジネスを拡大しよう
LLMの持つ大きな可能性を理解し、未来への準備を始めましょう。
LLMの進化がビジネスにもたらす未来
LLMの進化は、今後さらに加速していくと予想されます。
より高度な推論能力や専門知識を獲得し、人間を超える分析や問題解決能力を持つようになるかもしれません。
また、テキストだけでなく、画像、音声、動画など複数のデータを統合的に扱うマルチモーダル化がさらに進み、より人間に近い形で世界を認識できるようになるでしょう。
これにより、ビジネスにおける意思決定の自動化、パーソナライズされたサービスの高度化、研究開発のスピードアップなど、あらゆる領域で革命的な変化がもたらされます。
LLMを使いこなす能力が、企業や個人の競争力を左右する重要なスキルになることは間違いありません。
LLMを活用してビジネスを拡大しよう
企業は労働力不足や業務効率化の課題を抱える中で、LLMをはじめとする生成AIの活用が、DX推進や業務改善の切り札として注目されています。
しかし、実際には「どこから手を付ければいいかわからない」「社内にAIリテラシーを持つ人材がいない」といった理由で、導入のハードルが高いと感じる企業も少なくありません。
自社の状況に合わせてスモールスタートで導入を始め、試行錯誤を繰り返しながら成功パターンを見つけていくことが重要です。
まずは、本記事で紹介したようなメール作成や情報収集といった身近な業務からLLMの活用を試し、その効果を実感してみてください。
LLMを単なる業務効率化ツールとしてだけでなく、新たなビジネスチャンスを創出する戦略的パートナーと捉え、積極的に活用していくことで、企業の未来は大きく拓けるはずです。
LLMを使いこなせないと“時代遅れ”に?AI時代の新たな必須スキル
LLM(大規模言語モデル)の登場は、単なる業務効率化ツール以上の、働き方の根本的な変革を迫っています。ゴールドマン・サックスの報告によれば、生成AIは世界で3億人ものフルタイムの仕事に影響を与える可能性があると予測されています。これは、AIを「使う側」と「使われる側」の二極化が進む未来を示唆しています。これからのビジネスパーソンに求められるのは、LLMに指示を出すだけで満足するのではなく、その能力を最大限に引き出し、新たな価値を創造するスキルです。
具体的には、以下の3つの能力が重要になります。
- 課題発見・設定能力: どの業務にLLMを適用すれば最大の効果が得られるかを見極める力。
- プロンプト設計能力: AIの性能を最大限に引き出す、的確で創造的な指示を出す力。
- 批判的吟味・編集能力: AIの生成した出力が本当に正しいか、文脈に合っているかを判断し、最終的な成果物へと昇華させる力。
これらのスキルは、AIに仕事を奪われるのではなく、AIを最強の「副操縦士」として乗りこなし、自らの専門性を高めていくために不可欠です。もはやLLMを使いこなす能力は、かつてのPCスキルや英語力のように、ビジネスにおける普遍的な必須スキルとなりつつあります。
引用元:
世界経済フォーラムの「仕事の未来レポート2023」では、今後5年間で企業が最も重視するスキルとして、「分析的思考」や「創造的思考」が挙げられています。これは、AI技術の普及に伴い、単なる情報処理ではなく、AIが出した結果を批判的に評価し、新たなアイデアを生み出す人間の能力がより重要視されることを示唆しています。(World Economic Forum, “The Future of Jobs Report 2023”, 2023年)
まとめ
企業は労働力不足や業務効率化の課題を抱える中で、LLMをはじめとする生成AIの活用が、DX推進や業務改善の切り札として注目されています。
しかし、実際には「どこから手を付ければいいかわからない」「社内にAIリテラシーを持つ人材がいない」といった理由で、導入のハードルが高いと感じる企業も少なくありません。
そこでおすすめしたいのが、Taskhubです。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
たとえば、メール作成や議事録作成、画像からの文字起こし、さらにレポート自動生成など、さまざまな業務を「アプリ」として選ぶだけで、誰でも直感的にAIを活用できます。
しかも、Azure OpenAI Serviceを基盤にしているため、データセキュリティが万全で、情報漏えいの心配もありません。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「何をどう使えばいいのかわからない」という初心者企業でも安心してスタートできます。
導入後すぐに効果を実感できる設計なので、複雑なプログラミングや高度なAI知識がなくても、すぐに業務効率化が図れる点が大きな魅力です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最速の生成AI活用”を体験し、御社のDXを一気に加速させましょう。





