

RAGとは
RAGとは、Retrieval-Augmented Generationの略で、事前に用意した外部情報を検索し、大規模言語モデル(LLM)にそれを参考にして回答させる技術です。この技術を導入することで、生成AIが社内データといったクローズドな情報に関する質問に回答することができます。
日本語でRetrievalは検索、Augmentedは拡張、Generationは生成であることから、RAGは「検索拡張生成」とよばれることもあります。
※LLMとは、膨大なテキストデータと深層学習(ディープラーニング)技術を用いて構築された言語モデルです。LLMは生成AIの一種であり、テキスト生成、要約、翻訳、質問応答、文章校正など、さまざまな自然言語処理タスクを実行できます。有名なLLMには、OpenAIのGPT-4やGoogleのLaMDAなどが挙げられます。
RAGの仕組み
RAGの仕組みは意外とシンプルで、「検索段階」と「生成段階」という2つの段階で成り立っています。
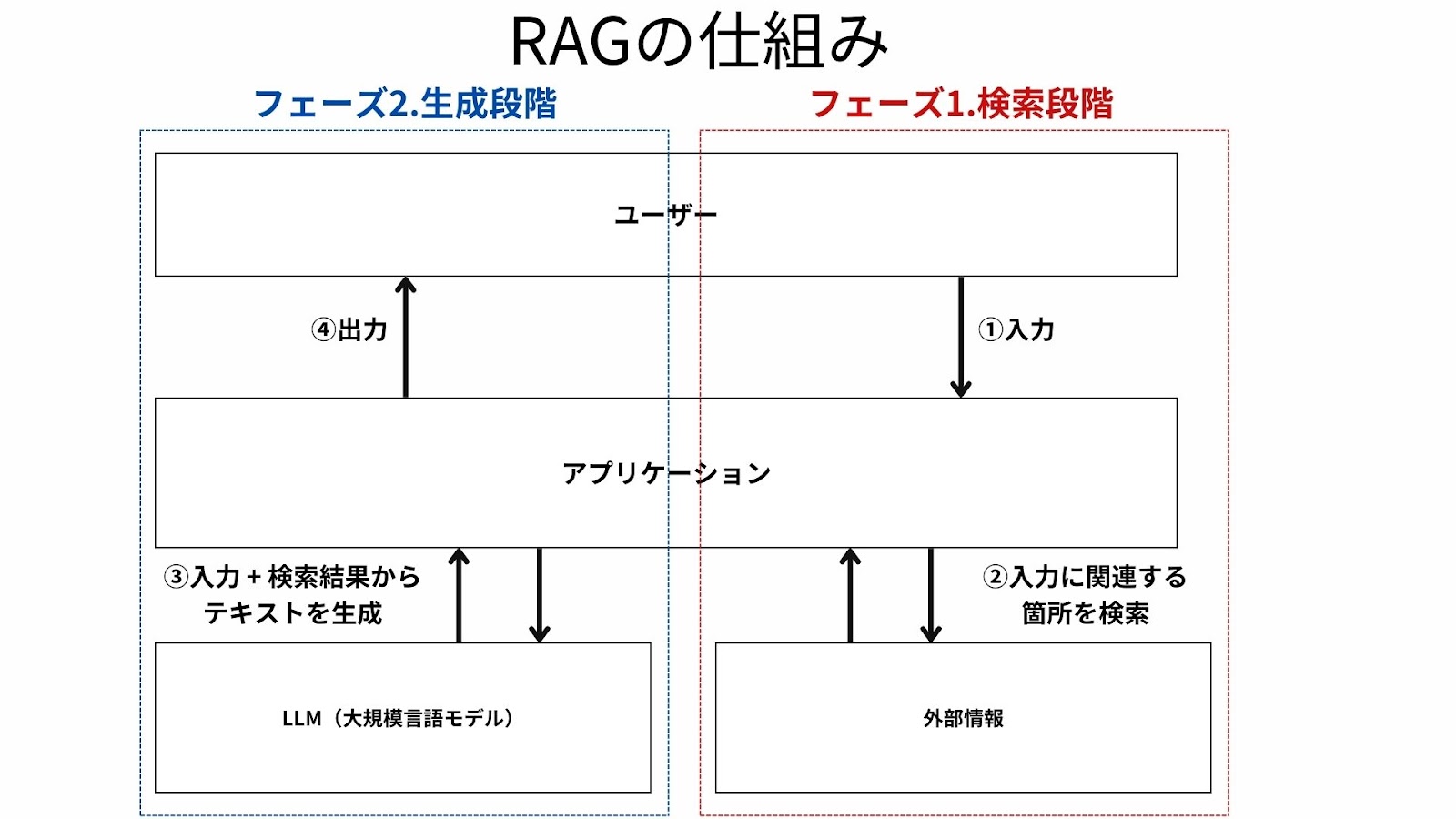
「検索段階」では、使用者が生成AIに質問した際、事前に用意した外部データベース(vector DB)にアクセスをし、回答作成に必要な情報の検索を行います。
「生成段階」では、取得してきた情報をLLMに対する命令文(プロンプト)に挿入し、回答を作成します。
その後、得られた回答結果を生成AIから使用者に対して提示するというプロセスがRAGの内部的なプロセスとなっています。
RAGのメリットとデメリット
RAGにはメリットとデメリットがそれぞれ存在します。これから、それらを紹介していきます。
RAGでできること
①生成AIがクローズドな情報に関する質問に回答できるようになる
LLMは一般的な情報を基に回答を生成するため、社内データといったクローズドな情報に関する質問に回答を生成することはできません。
そこで、外部情報を検索して利用するRAGを導入することで、生成AIがクローズドな情報に関する質問に回答できるようになります。
これにより、社内お問い合わせや顧客のサービス・商品に関するお問い合わせなどに生成AIが回答できるようになります。
②生成AIのハルシネーションリスクを低減できる
RAGは事前に用意した外部情報を検索し、LLMにそれを参考にして回答させることで、生成AIの「ハルシネーション」(誤った情報を生成すること)のリスクを低減できます。
これにより、ユーザーに提供される情報の正確性が向上し、信頼性の高い回答が得られます。
③最新の情報の回答が容易に行える
RAGはモデル自体に新たな情報を学習させる必要がないため、外部情報を変更するだけで、生成AIは最新の情報をもとに回答を生成できます。
これにより、常に最新のデータや知識を取り込むことができ、情報の鮮度が求められる場合でも効果的に対応できます。
④モデルのトレーニングコストがかからない
RAGはモデル自体に新たな調整を加えるわけではないため、モデルのトレーニングコストがかかりません。
RAGでできないこと
①回答精度はデータベースの質に依存する
RAGは事前に用意した外部情報を検索し、LLMにそれを参考にして回答させるため、回答精度は使用するデータベースの質に依存します。
そのため、古いデータや誤った情報が含まれているデータベースを使用すると、生成される回答の質も低下します。
②LLMの回答傾向そのものの制御には不向き
RAGは外部情報を利用して回答を補強しますが、GPT-4などのLLMの基本的な回答傾向を制御することには向いていません。
例えば、GPT-4が会話の最後に「他に質問はありますか?」といったフレーズを使用する傾向がある場合、RAGを導入してもその傾向は残ります。RAGは情報の精度を向上させる一方で、モデル自体の固有のパターンやバイアスを制御することには向いていません。
③LLMの使用コストが高くなる可能性がある
RAGは外部情報を検索し、それをLLMに命令文(プロンプト)として挿入するため、利用回数が多くなると、LLMの従量課金制によって利用料金が高くなる可能性があります。
特に、大量のデータを扱う場合や頻繁に検索を行う場合では、LLMの使用コストが増大してしまうリスクがあります。
④実装にはLLMやLang-Chainの専門知識が必要
RAGは検索と生成AIを組み合わせた複雑なアーキテクチャです。そのため、実装にはLLMやLang-Chainに関する専門知識が求められます。
RAGとファインチューニングの違い
RAGとファインチューニングは、生成AIに追加の情報を与えて、その情報を元に特定の目的に応じた回答を出力する手法として挙げられますが、この2つの手法にはいくつかの違いがあります。
ここでは、この2つの手法の違いを解説します。
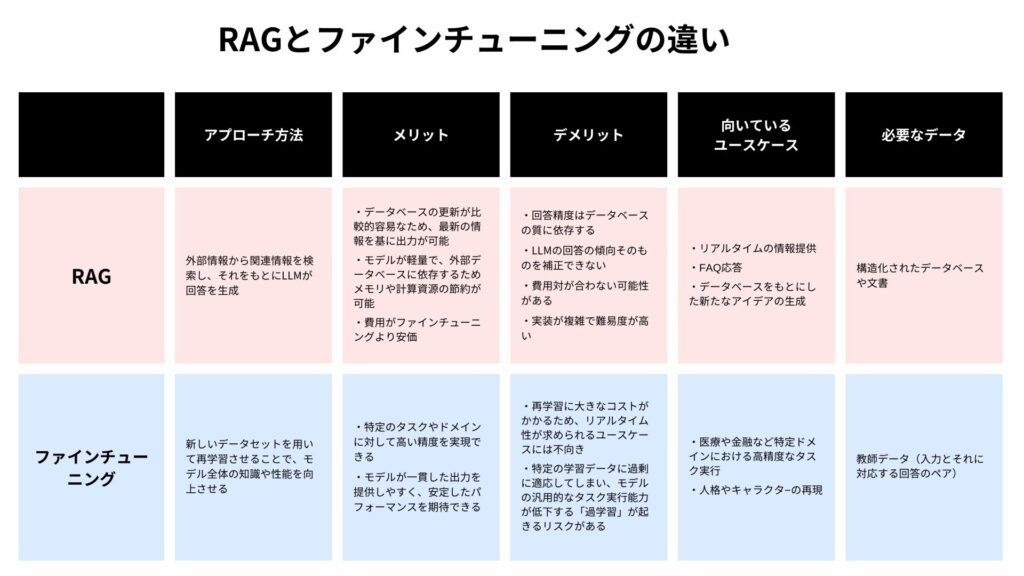
RAGとファインチューニングの違いで、最も重要なのは「アプローチ方法」の項目です。アプローチ方法の違いが、メリット・デメリットや向いてるユースケース、必要なデータの違いを生んでいるからです。
アプローチ方法の違いは一言で言えば「学習させているか否か」です。
RAGは外部情報を検索しLLMが回答を生成しますが、ファインチューニングはLLMそのものに情報を学習させます。
RAGの導入方法
RAGの導入方法としては、主に以下の3つの方法があります。
- RAG対応の生成AIツールを利用
- 自社でRAG環境を構築する
- ベンダーにRAG構築を依頼する
この3つの中で、最も現実的な選択肢としてあげられるのがRAG対応の生成AIツールを利用することでしょう。
もちろん、自社でRAG環境を構築できるならばそれが最善ですが、RAGのデメリットでも述べた通り、RAGの実装にはLLMやLang-Chainに関する専門知識が必要であり、自社でRAG環境を構築するのは技術的、コスト的な観点から難しい場合が多いと言えるでしょう。
また、ベンダーにRAG環境の構築を依頼するのもありですが、費用が高額になる可能性があります。
こういった背景から、RAG対応の生成AIツールを利用するのが最も現実的な選択肢です。
RAGでできること
ここでは、RAGでできることを2つ活用事例と共に挙げていきます。
1:社内業務の支援
RAGを活用することで、RAGを活用していない場合以上に生成AIが社内業務の支援を行うことができます。これには、検索する外部情報として社内規定や社内ナレッジなどを設定しておくことで、生成AIがそういった情報を検索して回答できるようにすることが必要です。
例えば、社内規定について知りたい時に生成AIに聞くことで回答が返ってきたり、資料を作成する時に生成AIに過去の資料から参考になりそうな部分を見つけてもらったりができるようになります。
実際の活用事例として、LINEヤフー株式会社がRAGを活用した生成AIツールである「SeekAI」 を社内展開し、業務に活用しています。
「SeekAI」は社内の技術情報に関する問い合わせや課題解決に関する部分、また各部門ごとに異なる申請フローや手続きに対応するワークフローがあり、それに基づいたマニュアルを活用して、部門ごとの手続きを支援するといった形で使われています。
参考:PROMPTY
2:クローズドな情報を使ったタスク遂行
RAGを活用することで、生成AIがクローズドな情報を使ってタスクを遂行することができるようになります。
これは、RAGが情報検索の形でクローズドな情報を参照することができるためです。
実際の活用事例として、東洋建設のRAGを活用した労働災害事例検索システムである「K-SAFE東洋 RAG適用Version」があります。
東洋建設は元々、「K-SAFETM」という厚生労働省の労働災害データを格納し、災害傾向を分析できる危険予知ツールを導入していました。
しかし、これは東洋建設が独自に制定している「東洋建設災害防止基準」や「社内災害事例」を参照できなかったそうです。
そこで、東洋建設はRAGを活用して「東洋建設災害防止基準」、「社内災害事例」等の社内安全関係資料を参照し、さらに画像を合わせて掲載することができる「K-SAFE東洋 RAG適用Version」を導入しました。
参考:東洋建築
RAGの導入を検討されている方へ
RAGの導入を検討する際、一番最初は自社に近い業態の企業がどのようにRAGを活用しているのか、事例を確認してみることがオススメです。
我々は全65社のRAGユースケースや導入の効果などのRAG導入事例をまとめたカオスマップと、RAG導入事例の分析レポートをご提供しています。
RAGの導入を検討する方は、是非下記リンクからダウンロードしてください。








