

「ChatGPTって、どうやって人間みたいに会話できるんだろう?」
「ChatGPTがどんな仕組みで動いているのか、その作り方を知りたい。」
このように、ChatGPTの裏側にある技術について疑問を持っている方も多いのではないでしょうか。
本記事では、ChatGPTがどのように作られたのか、その根幹をなす技術の仕組みから、具体的な学習プロセス、そしてこれまでの歴史までを分かりやすく解説します。
AIに関する専門的な知識がない方でも理解できるよう、丁寧に説明していきますので、ぜひ最後までご覧ください。
そもそもChatGPTはどうやって作った技術?基本のGPTを解説
「そもそもChatGPTとは何か、基本的な使い方を知りたい」という方は、こちらの記事で詳しく解説しています。合わせてご覧ください。
まずはじめに、ChatGPTを理解する上で欠かせない、その基礎技術である「GPT」について解説します。
ChatGPTとGPTは混同されがちですが、その役割には明確な違いがあります。
GPTとは何か、そしてChatGPTとGPTの違いを理解することで、ChatGPTがどのように作られたのかをより深く知ることができます。
それでは、一つずつ見ていきましょう。
GPTとは?
GPTとは、「Generative Pre-trained Transformer」の略称で、OpenAIによって開発された大規模言語モデル(LLM)の一種です。
「Generative(生成)」は、新しい文章を自ら作り出す能力を意味します。
「Pre-trained(事前学習済み)」は、インターネット上の膨大なテキストデータをあらかじめ学習していることを示しています。
そして「Transformer(トランスフォーマー)」は、このモデルの根幹をなす画期的なAIの仕組みの名前です。
つまりGPTは、事前に大量の文章を学習し、それに基づいて人間のように自然な文章を生成することができるAIモデルと言えます。
このGPTが、ChatGPTの頭脳として機能しています。
ChatGPTとGPTの違い
GPTとChatGPTの最も大きな違いは、その役割と目的にあります。
GPTは、文章生成、翻訳、要約など、言語に関する様々なタスクをこなすことができる、非常に汎用性の高い「基盤モデル」です。
いわば、様々な料理に応用できる万能な「エンジン」や「頭脳」のような存在です。
一方、ChatGPTは、そのGPTというエンジンを搭載し、特に「人間との対話」に特化させた「アプリケーション」です。
ユーザーからの質問に答えたり、自然な会話を続けたりできるように、GPTを対話形式に最適化(ファインチューニング)したものがChatGPTなのです。
つまり、GPTが言語モデルそのものであるのに対し、ChatGPTはGPTをより使いやすく、特定の目的のために調整されたサービスと考えることができます。
ChatGPTはどうやって作った?開発者OpenAIと開発目的
次に、この革新的なAIであるChatGPTを開発した組織「OpenAI」と、彼らがどのような目的でChatGPTを作ったのかについて掘り下げていきます。
開発者のビジョンや目的を知ることは、ChatGPTという技術の本質を理解する上で非常に重要です。
ChatGPTを開発したOpenAIとは
ChatGPTを開発したのは、アメリカのサンフランシスコに拠点を置く人工知能の研究開発企業「OpenAI」です。
OpenAIは、2015年にイーロン・マスク氏やサム・アルトマン氏などによって、「人類全体に利益をもたらす友好的なAIを普及・発展させること」を目的として設立された非営利団体からスタートしました。
現在は、研究開発を加速させるために「上限付き利益会社」という形態をとっており、Microsoft社などから巨額の出資を受け、世界最先端のAI研究開発をリードする存在となっています。
彼らは、AI技術が社会に与える影響を深く考慮し、安全で倫理的なAIの開発を目指しています。
こちらは、OpenAIが設立当初から掲げている理念や目的を記した公式憲章です。合わせてご覧ください。 https://openai.com/charter/
OpenAIがChatGPTを作った目的
OpenAIがChatGPTを作った主な目的は、AI技術の可能性を広く一般に示し、人間とAIがどのように協調できるかを探ることにあります。
これまでAIの研究は専門家の中だけのものになりがちでしたが、ChatGPTを誰もが簡単に使える形で公開することで、世界中の人々からフィードバックを得ることができます。
このフィードバックは、AIの能力向上だけでなく、潜在的なリスクや課題を特定し、より安全なAIシステムを構築するために不可欠です。
また、文章作成、アイデア出し、プログラミング補助など、様々なタスクをAIに任せることで、人間の生産性を向上させ、より創造的な活動に集中できるようにすることも大きな目的の一つです。
ChatGPTはどうやって作った?AIの基本となる仕組みとアルゴリズム
ここからは、ChatGPTがどのようにして作られたのか、その技術的な心臓部である仕組みとアルゴリズムについて掘り下げていきます。
ChatGPTが人間のような自然な文章を生成できる背景には、「トランスフォーマーモデル」という画期的な仕組みと、膨大な学習データ、そして人間による評価のプロセスが存在します。
それぞれの要素について、詳しく見ていきましょう。
ChatGPTのベースは「トランスフォーマーモデル」
ChatGPTの性能を支える最も重要な技術が「トランスフォーマー(Transformer)」モデルです。
2017年にGoogleが発表したこのモデルは、自然言語処理の分野に革命をもたらしました。
トランスフォーマーモデルの最大の特徴は、「Attention(アテンション)機構」と呼ばれる仕組みにあります。
これは、文章中のどの単語とどの単語が重要で、互いに強く関連しているのかをAIが自ら学習し、その関連性の強さに応じて重み付けをする技術です。
この仕組みにより、長い文章でも文脈を正確に理解し、「彼」や「それ」といった代名詞が何を指しているのかを的確に把握することができます。
その結果、文脈に沿った、より自然で一貫性のある文章の生成が可能になったのです。
こちらは、ChatGPTの根幹技術である「トランスフォーマー」を提唱した、Googleによる画期的な論文です。やや専門的な内容ですが、ご興味のある方はご覧ください。 https://papers.nips.cc/paper/7181-attention-is-all-you-need
ChatGPTの主なデータセット
ChatGPTが豊富な知識を持ち、様々な話題について会話できるのは、その学習に使われた膨大な「データセット」のおかげです。
ChatGPTは、主にインターネット上に存在するウェブサイト、書籍、ニュース記事、Wikipedia、ブログなど、多岐にわたるテキストデータを大規模に収集して学習しています。
そのデータ量は数千億単語にも及ぶと言われており、この膨大な情報の中から言語のパターン、文法、事実関係、さらには文章のスタイルなどを学んでいます。
どのようなデータをどれだけ学習したかが、AIの知識の広さや回答の質を大きく左右するため、データセットはAIの性能を決定づける非常に重要な要素です。
ただし、学習データには誤った情報や偏見が含まれている可能性もあり、それがAIの回答に影響を与えることも課題の一つとされています。
ChatGPTが使用する評価モデル
ChatGPTが単に知識が豊富なだけでなく、人間にとって自然で、安全かつ役に立つ回答を生成できるのは、「評価モデル」を用いた学習プロセスがあるからです。
このプロセスは「人間のフィードバックによる強化学習(RLHF)」と呼ばれています。
まず、AIが生成した複数の回答を、人間の評価者が「どちらの回答がより優れているか」を基準にランク付けします。
この大量のランク付けデータをAIに学習させることで、「評価モデル」が作られます。
このモデルは、どのような回答が人間にとって好ましいかを判断する「採点官」のような役割を果たします。
AIは、この採点官から高得点をもらえるように、自らの回答を改善していく学習を繰り返します。
この仕組みによって、ChatGPTの回答はより洗練され、質が高まっていくのです。
こちらは、ChatGPTの回答品質を飛躍的に向上させた「人間のフィードバックによる強化学習(RLHF)」の仕組みを解説したOpenAIの論文です。 https://arxiv.org/abs/2203.02155
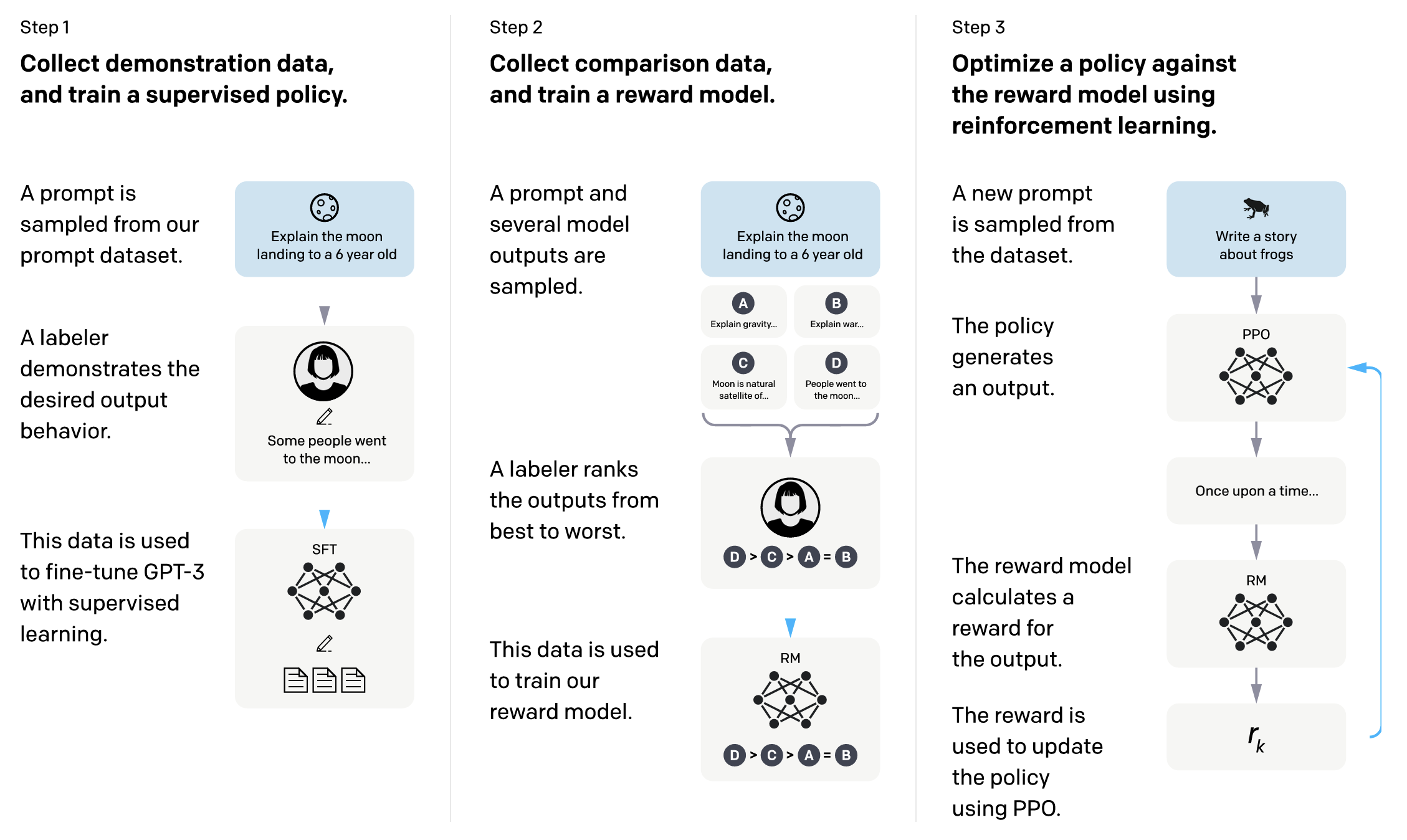
ChatGPTはどうやって作った?3つの学習プロセスを解説
ChatGPTが人間のように自然な文章を生成できる背景には、大きく分けて3つの学習プロセスがあります。
プロセス1. 事前学習(Pre-training)
プロセス2. ファインチューニング(Fine-tuning)
プロセス3. 評価モデルで学習(強化学習)
これらの段階的な学習を経ることで、ChatGPTは広範な知識と自然な対話能力を身につけていきます。
それでは、一つずつ順に解説します。
プロセス1. 事前学習(Pre-training)
最初のステップは「事前学習(Pre-training)」です。
この段階では、GPTモデルはインターネット上から収集されたウェブページ、書籍、論文といった、人間が書いた膨大な量のテキストデータをひたすら読み込みます。
ここでの学習方法は非常にシンプルで、「文章の途中までを与えられ、その次に続く単語を予測する」というタスクを繰り返し行います。
例えば、「吾輩は猫である。名前はまだ__」という文章を見せられたら、「無い」という単語を予測する、といった具合です。
この地道な学習を何億回、何兆回と繰り返すことで、モデルは単語と単語のつながりや文法のルール、さらには世界に関する幅広い知識など、言語の根底にある複雑なパターンを自ら習得していきます。
これが、ChatGPTの持つ広範な知識の基礎となります。
プロセス2. ファインチューニング(Fine-tuning)
事前学習で広範な知識を身につけたモデルは、次のステップである「ファインチューニング(Fine-tuning)」に進みます。
これは、モデルを特定のタスク、ChatGPTの場合は「対話」に適応させるための「微調整」のプロセスです。
この段階では、AI開発者が用意した、質の高い「手本となる対話データセット」を使って学習を行います。
このデータセットには、「こういう質問には、このように答えるのが望ましい」という形式の、人間が作成した理想的な質疑応答の例が大量に含まれています。
モデルはこの手本を学習することで、ユーザーの指示に従う方法や、質問の意図を汲み取って適切な形で応答するスタイルを学びます。
事前学習が広くて浅い知識を身につけるプロセスだとすれば、ファインチューニングは特定の目的に合わせて専門知識やスキルを磨くプロセスと言えます。
プロセス3. 評価モデルで学習(強化学習)
最後のステップが、人間の価値観に沿った回答を生成するための「強化学習」です。
このプロセスでは、「人間のフィードバックによる強化学習(RLHF: Reinforcement Learning from Human Feedback)」という手法が用いられます。
まず、ある質問に対して、AIに複数の回答案を生成させます。
次に、人間の評価者がそれらの回答を読み、「最も良いもの」から「最も悪いもの」まで順番にランク付けをします。
この「人間による評価データ」をAIに学習させることで、「人間がどのような回答を好むか」を判断する「報酬モデル(または評価モデル)」を構築します。
その後、AIは自ら回答を生成し、その回答が報酬モデルから高い評価(報酬)を得られるように、試行錯誤を繰り返しながら回答の仕方を自己改善していきます。
このプロセスにより、ChatGPTはより安全で、倫理的で、ユーザーにとって役立つ回答を生成する能力を高めていくのです。
ChatGPTはどうやって作った?GPTモデルの歴史と進化
ChatGPTの性能は、その基盤となるGPTモデルの進化とともに飛躍的に向上してきました。
初代のGPT-1から現在のGPT-4に至るまで、モデルは大規模化・高性能化を続けています。
ここでは、GPTモデルがどのように進化してきたのか、その歴史と各モデルの性能の違いを振り返ります。
この進化の過程を知ることで、ChatGPTがどのように作られてきたのかをより深く理解できるでしょう。
GPT-1からGPT-3までの歴史
GPTモデルの歴史は、2018年に発表された「GPT-1」から始まります。
GPT-1は、トランスフォーマーモデルをベースに、事前学習というコンセプトを大規模に適用した先駆けであり、自然言語処理の分野に大きなインパクトを与えました。
2019年には、パラメータ数を大幅に増やした「GPT-2」が登場します。
GPT-2は非常に流暢で一貫性のある文章を生成できることから、その能力が悪用される危険性が懸念され、当初はフルモデルが公開されないという異例の対応が取られたことでも有名です。
そして2020年、パラメータ数をさらに桁違いに増やした「GPT-3」が発表されます。
GPT-3は、 few-shot learning(いくつかの例を示すだけでタスクをこなす能力)において驚異的な性能を示し、文章生成のクオリティが人間と見分けがつかないレベルに達したと評価されました。
このGPT-3の登場が、現在の生成AIブームの直接的な火付け役となりました。
こちらは、現在の生成AIブームの火付け役となり、AIの能力を世に知らしめた「GPT-3」の技術詳細を解説した論文です。 https://arxiv.org/abs/2005.14165
GPT-4とGPT-3.5の性能の違い
ChatGPTが2022年11月に公開された当初、搭載されていたのは「GPT-3.5」モデルでした。
これはGPT-3を対話用に改良したもので、その高い性能で世界中を驚かせました。
そして2023年3月、さらに進化した「GPT-4」が発表されます。
GPT-4は、GPT-3.5と比較して、あらゆる面で性能が飛躍的に向上しています。
最も大きな違いの一つは、テキストだけでなく画像の内容も理解できる「マルチモーダル性」を獲得した点です。
また、推論能力が大幅に向上し、アメリカの司法試験で上位10%に入るほどの成績を収めるなど、より複雑で専門的なタスクをこなせるようになりました。
さらに、一度に扱える文章量(コンテキスト長)も増加し、長文の読解や要約、より複雑な文脈を維持した会話が可能になっています。
これらの進化により、GPT-4はより信頼性が高く、幅広い用途で活用できるモデルとなっています。
こちらは、画像も理解できるようになったGPT-4の性能や特徴について、OpenAIが公式に発表しているテクニカルレポートです。合わせてご覧ください。 https://arxiv.org/abs/2303.08774
ChatGPTはどうやって作った?従来のチャットボットとの違い
ChatGPTの登場以前にも、チャットボットは存在していましたが、その能力には限界がありました。
ChatGPTは、従来のチャットボットとは一体何が違うのでしょうか。
その革新性は、主に「応答の柔軟性と文脈理解能力」と「生成できるコンテンツの多様性」という2つの観点から説明できます。
これらの違いを理解することで、ChatGPTがもたらした技術的なブレークスルーの大きさが分かります。
応答の柔軟性と文脈理解能力
従来のチャットボットの多くは、「ルールベース」や「シナリオベース」と呼ばれる仕組みで動いていました。
これは、あらかじめ開発者が設定した特定のキーワードやシナリオにしか反応できず、想定外の質問には「分かりません」と答えるしかありませんでした。
一方、ChatGPTは、トランスフォーマーモデルと膨大なデータによる学習を通じて、文脈を深く理解する能力を持っています。
会話の流れ全体を記憶し、曖昧な表現や複雑な質問の意図を汲み取って、柔軟に応答することができます。
そのため、事前にプログラムされていない未知の質問に対しても、人間のように創造的で適切な回答を生成することが可能です。
生成できるコンテンツの多様性
従来のチャットボットの役割は、主に特定の質問に対して決められた情報を返す、という限定的なものでした。
それに対してChatGPTは、単なる質疑応答にとどまらず、非常に多様なコンテンツを生成できる能力を持っています。
例えば、長い文章の要約、外国語への翻訳、小説や詩、歌詞の創作、ビジネスメールの作成、さらにはプログラムのコード生成まで、ユーザーの要求に応じて様々なテキストコンテンツを作り出すことができます。
この生成能力の多様性が、ChatGPTを単なる情報検索ツールではなく、人間の知的生産活動をサポートする強力なパートナーへと押し上げた最大の要因と言えるでしょう。
ChatGPTはどうやって作った技術か分かる具体的な活用方法
ChatGPTの具体的な業務活用事例については、こちらの記事で40選にまとめて紹介していますので、ぜひ参考にしてください。
ChatGPTがどのように作られたかを理解すると、その技術がどのような場面で役立つのか、具体的な活用方法もより明確になります。
ここでは、ChatGPTの高度な言語処理能力がビジネスシーンでどのように活かされているか、具体的な活用例をいくつか紹介します。
これらの事例は、ChatGPTの技術的な特徴をよく表しています。
カスタマーサポート
ChatGPTの技術は、カスタマーサポートの分野で大きな変革をもたらしています。
よくある質問(FAQ)に対する回答をChatGPTに任せることで、24時間365日、顧客からの問い合わせに即座に対応することが可能になります。
従来のチャットボットと違い、多少曖昧な表現や口語的な質問でも意図を汲み取って適切な回答を生成できるため、顧客満足度の向上につながります。
また、人間のオペレーターは、より複雑で個別対応が必要な問い合わせに集中できるようになり、サポート全体の質と効率を大幅に改善することができます。
予約業務の自動化
飲食店や美容院、クリニックなどの予約受付業務も、ChatGPTを活用して自動化することができます。
従来の予約システムは、決まったフォーマットに顧客が入力する必要がありましたが、ChatGPTを使えば、人間と会話するように自然な対話形式で予約を完結させることが可能です。
「明日の夜、2名で予約したいのですが」「窓際の席は空いていますか?」といった、自由な形式の要望にも柔軟に対応し、空き状況を確認して予約を確定させることができます。
これにより、電話対応などの業務負担を軽減し、人手不足の解消にも貢献します。
企業データの分析
企業内には、顧客からのフィードバック、営業日報、会議の議事録、社内チャットなど、膨大な量のテキストデータが蓄積されています。
ChatGPTの高度な要約能力や文脈理解能力を使えば、これらのテキストデータを効率的に分析し、ビジネスに役立つ知見(インサイト)を抽出することができます。
例えば、大量の顧客レビューを要約して製品改善のヒントを得たり、議事録から重要な決定事項やタスクを自動でリストアップしたりすることが可能です。
これにより、データに基づいた迅速な意思決定を支援します。
マーケティングへの応用
マーケティング分野は、ChatGPTのクリエイティブな文章生成能力が最も活かせる領域の一つです。
広告のキャッチコピー、メールマガジンの文面、ブログ記事、SNSへの投稿内容など、様々なマーケティングコンテンツのアイデア出しや草稿作成をChatGPTに任せることができます。
ターゲット顧客のペルソナを伝えるだけで、その層に響くような複数のキャッチコピー案を瞬時に生成させることも可能です。
これにより、マーケティング担当者はコンテンツ制作の時間を大幅に短縮し、より戦略的な業務に集中することができます。
ChatGPTはどうやって作った?技術的な課題と今後の展望
ChatGPTは非常に強力な技術ですが、まだ完璧ではなく、いくつかの技術的な課題も抱えています。
最もよく知られているのが「ハルシネーション(Hallucination)」です。
これは、AIが事実に基づかない、もっともらしい嘘の情報を生成してしまう現象です。
また、学習データに含まれる偏見(バイアス)をAIが再現してしまう問題や、悪用のリスクといった倫理的な課題も存在します。
今後の展望としては、これらの課題を克服するための研究が進められています。
事実に基づいた回答を徹底する技術や、AIの思考プロセスを透明化する技術の開発が期待されます。
また、GPT-4で実現したようなマルチモーダル化がさらに進み、テキストや画像だけでなく、音声や動画も統合的に理解し、生成できる、より人間に近い能力を持ったAIが登場することも予測されます。
特定の専門分野に特化して学習させた、より高精度なAIモデルの開発も進んでおり、ChatGPTを支える技術はこれからも私たちの社会に大きな影響を与え続けるでしょう。
こちらは、ChatGPTの課題である「ハルシネーション」がなぜ起こるのか、その原因や種類、対策について網羅的に調査した論文です。 https://arxiv.org/abs/2311.05232
あなたの脳は思考停止する?ChatGPTで「賢くなる人」と「怠ける人」の分岐点
ChatGPTを日常的に利用しているものの、本当に思考力が鍛えられているのか不安に感じていませんか。使い方を誤ると、私たちの脳は無意識のうちに考えることをやめてしまうかもしれません。
マサチュー-セッツ工科大学(MIT)の研究は、その危険性を示唆しています。しかし、心配は不要です。ChatGPTを「思考を深めるためのパートナー」として活用し、知的能力を高める方法も存在します。この記事では、「思考停止に陥る人」と「賢く使いこなす人」を分ける決定的な違いを、最新の研究結果を基に解説します。
AIに頼りすぎると「脳がサボる」という現実
「ChatGPTに聞けば、自分で考えなくて済む」という考えは、思考力を低下させる危険な兆候かもしれません。MITの研究によれば、ChatGPTの支援を受けて文章を作成した人は、自力で取り組んだ人に比べて脳の活動が著しく低下する結果となりました。これは、思考そのものをAIに委ねてしまう「認知の外部委託」が起きていることを示しています。この状態が続くと、物事の本質を深く探求する力や、情報を多角的に疑う批判的思考力が衰える可能性があります。便利なツールに依存するあまり、本来持っているはずの貴重な「考える力」が、知らず知らずのうちに失われていくのです。
引用元:
MITの研究チームは、大規模言語モデル(LLM)の使用が人間の認知に与える影響を調査しました。その結果、LLMを利用して文章作成タスクを行った参加者は、自力で取り組んだ参加者と比較して、脳内の認知活動が大幅に低下することが示されました。(Artem Shmidman, B. Sciacca, et al. “Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task” 2024年)
こちらが、記事中で言及したマサチューセッツ工科大学(MIT)による、AIアシスタントの使用が脳の認知活動に与える影響を調査した研究論文です。 https://arxiv.org/abs/2405.02339
AIを「思考のトレーニングジム」に変える賢い使い方
では、「賢くなる人」はChatGPTをどのように活用しているのでしょうか。答えは、AIを「答えを出す機械」としてではなく、「思考を鍛えるための壁打ち相手」として使うことにあります。ここでは、今日から実践できる3つの使い方を紹介します。
使い方①:あえて「反対意見」を求め、思考の穴をなくす
自分の考えをより強固にするためには、弱点や見落としている視点に気づくことが不可欠です。そこで、ChatGPTに優秀な批評家の役を演じてもらいましょう。
プロンプト例:
「(あなたの企画や意見)について、あなたは批判的な視点を持つコンサルタントです。このアイデアの最も重大な欠点を3つ、理由とともに指摘してください。」
これにより、自分一人では気づきにくい論理の矛盾や弱点を客観的に把握し、思考をより深く、多角的にする訓練ができます。
使い方②:自分が「生徒」となり、AIに要約・解説させる
複雑なテーマを理解したい時、ただ情報をインプットするだけでは知識は定着しにくいものです。そこで、ChatGPTを専門家と見立て、自分が生徒になって解説を求めてみましょう。
プロンプト例:
「(あなたが学びたい専門テーマ)について、私は専門知識のない新人です。このテーマの最も重要なポイントを3つに絞り、中学生にも分かるように、具体的な例を交えて解説してください。」
AIによる分かりやすい解説を通じて、難しい概念の全体像を素早く掴み、効率的に知識を吸収することができます。
使い方③:アイデアの「種」を渡し、発想を飛躍させる
「何か面白いアイデアを出して」と丸投げするのは、思考停止への近道です。そうではなく、自分のアイデアの断片をAIに触媒として与え、化学反応を起こさせるのです。
プロンプト例:
「新しい(製品やサービス)の企画を考えています。キーワードは『A』と『B』です。この2つの要素を組み合わせた、これまでにない斬新なコンセプトのアイデアを5つ提案してください。」
AIが提示する多様な切り口からインスピレーションを得て、最終的なアイデアへと昇華させるのはあなた自身です。このプロセスにより、創造性が刺激され、発想の幅が大きく広がります。
まとめ
生成AIの仕組みやその進化への関心が高まる一方で、多くの企業では人手不足の解消や生産性向上の課題に直面しており、AIの業務活用が解決策として期待されています。
しかし、現実には「何から始めればいいか分からない」「社内にAIを使いこなせる人材がいない」といった声が多く、導入への一歩を踏み出せない企業が少なくありません。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本で初めてのアプリ型インターフェースを特徴とし、200種類以上の実用的なAI業務をパッケージ化した生成AI活用プラットフォームです。
たとえば、日々のメール作成や議事録の要約、画像からの文字起こしや、さらには詳細なレポートの自動生成まで、多岐にわたる業務を「アプリ」を選ぶような感覚で、誰でも簡単にAIに任せることができます。
基盤にはAzure OpenAI Serviceを採用しているため、入力したデータが外部で学習に使われる心配がなく、セキュリティ面でも万全です。
さらに、専門のAIコンサルタントが導入から活用まで丁寧にサポートするため、「AIをどう業務に活かせばいいのか」という根本的な悩みを持つ企業でも、安心して導入を進められます。
導入後すぐに効果を実感できるよう設計されており、専門的なプログラミング知識や高度なAIリテラシーがなくても、迅速に業務効率化を実現できる点が最大の魅力です。
まずは、Taskhubの具体的な活用事例や多彩な機能を詳しく解説した【サービス概要資料】を無料でダウンロードしてみてください。
Taskhubで“最も簡単な生成AI活用”を始め、貴社のデジタルトランスフォーメーションを力強く推進しましょう。






