

「社内にある膨大なデータをAIに学習させて、業務効率化を図りたい」
「RAGという言葉を聞くけれど、通常のAI学習と何が違うのかよくわからない…。」
このように考えている担当者の方も多いのではないでしょうか?
生成AIの活用が進む中で、自社独自のデータをAIに扱わせたいというニーズは急速に高まっています。しかし、その手法として「追加学習(ファインチューニング)」を選ぶべきか、「RAG」を選ぶべきかで迷ってしまうケースは少なくありません。
本記事では、RAGの仕組みやファインチューニングとの違い、具体的な導入ステップについて解説しました。
上場企業をメインに生成AIコンサルティング事業を展開している弊社が、最新のGPT-5などの動向も踏まえて、実用的な視点でご紹介します。
こちらは生成AIへ社内データを学習させる方法について解説した記事です。 合わせてご覧ください。
社内データの活用における最適な手法が見つかるはずですので、ぜひ最後までご覧ください。
RAG(検索拡張生成)とは?AIに学習させずにデータを扱う技術
ここでは、RAGの基本的な概念と仕組みについて解説します。
- RAGとは何か
- なぜ学習なしで回答できるのか
- LLMとの関係性
これらを理解することで、なぜ今RAGが企業から注目されているのか、その本質的な理由が見えてくるはずです。
それでは、一つずつ順に解説します。
RAGのわかりやすい定義と仕組み
RAG(Retrieval-Augmented Generation)は、日本語で「検索拡張生成」と呼ばれています。簡単に言えば、AIが回答を生成する際に、外部のデータベースから関連する情報を検索し、その情報を「カンニング」しながら回答を作成する技術のことです。
通常、ChatGPTなどのAIは、過去に学習したデータに基づいて回答を行います。そのため、学習していない社内の非公開情報や、昨日のニュースなどの最新情報には答えられません。しかし、RAGを使えば、AI自体に知識を記憶させなくても、必要な瞬間に必要なデータを参照させることで、正確な回答を引き出すことができます。
イメージとしては、試験の際に「持ち込み可能な教科書」を参照しながら答案を書くようなものです。教科書(社内データ)さえ渡せば、AIは暗記していなくても内容に基づいた答えを出すことができます。この仕組みにより、AIの再学習というコストのかかる工程を経ずに、自社専用のAIのような振る舞いをさせることが可能になります。
こちらはRAG(Retrieval-Augmented Generation)の概念が提唱された基礎論文です。より学術的な背景や原典を確認したい方は合わせてご覧ください。 https://arxiv.org/abs/2005.11401
なぜ「追加学習」させなくても社内データに回答できるのか
多くの人が誤解しやすいポイントですが、RAGはAIモデル自体を賢くしているわけではありません。AIがもともと持っている「文章を理解し、要約して答える能力」を応用しているに過ぎないのです。
RAGのシステムでは、ユーザーが質問をした瞬間に、その質問に関連する社内ドキュメントを検索システムが探し出します。そして、見つかったドキュメントの文章を、ユーザーの質問と一緒にAIへの指示(プロンプト)として渡します。「以下の参考資料をもとに、この質問に答えてください」という指示を裏側で送っているのです。
最新のGPT-5などの高度なモデルは、渡された長文の資料を瞬時に読み解き、文脈を理解する能力が非常に高まっています。そのため、事前にデータを学習(記憶)させていなくても、その場で提示された情報を元に、あたかもその情報を知っていたかのように流暢に回答することができます。これが、学習不要で社内データを扱える理由です。
RAGとLLM(大規模言語モデル)の関係性
RAGは、LLM(大規模言語モデル)の弱点を補完する重要な技術です。LLMは膨大な知識を持っていますが、その知識は「学習データのカットオフ(学習終了時期)」までの情報に限られます。また、確率的に言葉を繋ぐ仕組みであるため、もっともらしい嘘をつく「ハルシネーション」という現象が起きることがあります。
RAGを組み合わせることで、LLMは検索結果という「根拠」に基づいて回答を生成できるようになります。これにより、情報の鮮度という問題と、回答の正確性という問題の両方を大きく改善することができます。
特に、2025年8月にリリースされたOpenAIのGPT-5のような最新モデルでは、複雑な推論能力が強化されており、RAG経由で渡された専門的な技術文書や社内規定などの難解なデータであっても、より正確に解釈して回答できるようになりました。LLMが「脳」であるなら、RAGは最新の知識が詰まった「辞書」や「図書館」の役割を果たし、両者が連携することでビジネスでの実用性が飛躍的に高まるのです。
こちらはMicrosoft AzureによるRAGの概要解説ドキュメントです。LLMとRAGの技術的な関係性について詳細を知りたい方は合わせてご覧ください。 https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview
RAGとファインチューニングの違いは?学習手法としてどっちを選ぶべき?
ここでは、よく比較されるRAGとファインチューニングの違いについて、学習の観点から詳しく比較します。
- 機能やコストの違い
- 正確性とリスクの比較
- 更新頻度による使い分け
これらを比較表なども交えて整理することで、自社の目的にどちらが適しているのかを判断できるようになります。
それでは、詳細を見ていきましょう。
【比較表】RAG・ファインチューニング・プロンプトエンジニアリングの使い分け
自社データをAIに活用させる手法には、主に「RAG」「ファインチューニング」「プロンプトエンジニアリング」の3つがあります。これらはそれぞれ得意とする領域が異なります。
まず、RAGは「知識の参照」が得意です。社内マニュアルや製品データなど、具体的な事実に基づいた回答が必要な場合に適しています。AI自体はいじらないため、導入のハードルは比較的低いです。
次に、ファインチューニングは「振る舞いの矯正」が得意です。特定の業界用語を多用する文章スタイルや、特殊な形式での出力など、AIの「話し方」や「思考パターン」をカスタマイズしたい場合に適しています。ただし、新しい知識を正確に覚えさせる用途には、実はあまり向いていません。
最後に、プロンプトエンジニアリングは、指示の工夫だけで結果を変える手法です。コストは最も低いですが、扱えるデータ量に限界があります。一般的には、まずプロンプトで試し、次にRAGを検討し、それでも解決できない特殊なニーズがある場合にファインチューニングを行う、という順序で検討するのが定石です。
こちらはRAGとファインチューニングの違いについて詳しく比較解説した記事です。企業戦略としての使い分けについてさらに知りたい方は合わせてご覧ください。 https://www.oracle.com/artificial-intelligence/generative-ai/retrieval-augmented-generation-rag/rag-fine-tuning/
コストと導入スピードの比較
コストとスピードの面では、RAGの方に大きな分があります。ファインチューニングを行う場合、高品質な学習データセットを大量に作成する必要があり、これには多大な人的リソースと時間がかかります。また、GPUなどの計算リソースにも高額な費用が発生します。
一方、RAGは既存のドキュメント(PDFやWordなど)をデータベース化するだけで済むため、データ準備の工数が大幅に削減できます。システム構築も、現在はAzure OpenAI ServiceやAWSなどのクラウドサービスでRAGの機能が標準提供されており、数日から数週間での導入が可能です。
さらに、運用コストの面でも差が出ます。ファインチューニングしたモデルを利用する場合、ホスティング費用が高額になるケースが多いですが、RAGであれば標準的なAPI利用料とデータベースの維持費で済むため、スモールスタートしやすいのが特徴です。特にGPT-5-miniのような低コストかつ高性能なモデルが登場している現在、RAGのコストパフォーマンスは非常に高まっています。
回答の正確性とハルシネーション(嘘)のリスク比較
業務利用において最も懸念されるのが、AIが嘘をつく「ハルシネーション」です。この点においても、事実関係を問うタスクではRAGの方が優れています。
ファインチューニングで知識を学習させた場合、AIはその知識を「あやふやな記憶」として保持します。そのため、似たような用語を混同したり、数値の桁を間違えたりするリスクが排除できません。学習データに含まれていないことを聞かれた際に、無理やり答えようとして嘘をつくこともあります。
対してRAGは、回答の際に必ず参照ドキュメントを確認します。「ドキュメントに書かれていないことは答えない」という制御もしやすいため、根拠のない回答を抑制できます。また、回答と一緒に「参照元」を提示できるため、ユーザー自身が情報の真偽を確認することも容易です。正確性が求められるビジネスシーンでは、この「検証可能性」がRAGの大きな強みとなります。
こちらは大規模言語モデルにおけるRAG技術の動向をまとめた調査論文です。ハルシネーション対策を含む技術的な詳細について深く知りたい方は合わせてご覧ください。 https://arxiv.org/abs/2401.00396

情報の更新頻度による使い分けの基準
情報の鮮度がどれくらい重要かという点も、選択の重要な基準になります。日々の業務日報、在庫情報、頻繁に変更される社内規定など、情報が毎日や毎週更新されるようなケースでは、RAG一択と言っても過言ではありません。
RAGであれば、参照元のデータベース内のファイルを差し替えるだけで、AIの回答に即座に最新情報が反映されます。これにかかる時間は数分程度です。
一方、ファインチューニングで最新情報を反映させるには、その都度モデルの再学習(追加学習)を行う必要があります。これには数時間から数日かかり、コストも毎回発生するため、頻繁に情報が変わる用途には現実的ではありません。ファインチューニングは、法律用語の言い回しや、ブランド固有のトーン&マナーなど、長期間変わらない「スタイル」を学習させるのに適しています。
企業がRAG導入で社内データを学習させずに活用するメリット
ここでは、企業がRAGを導入する具体的なメリットについて解説します。
- セキュリティの確保
- 即時性の高い情報反映
- 根拠の明示
RAGを導入することで、単なる業務効率化だけでなく、ガバナンスの強化や信頼性の向上にもつながります。
それでは、それぞれのメリットを詳しく見ていきましょう。
セキュリティを保ったまま自社独自の情報を扱える
企業が生成AIを導入する際、最大の懸念事項となるのが情報漏洩のリスクです。「社内の機密データをAIに入力すると、それが学習されてしまい、他社への回答で流出してしまうのではないか」という不安を持つ担当者は多いでしょう。
RAGの仕組みを利用する場合、特に法人向けのセキュアな環境(例えばAzure OpenAIや、OpenAIのEnterpriseプランなど)を構築すれば、入力されたデータがAIモデルの学習に使われることはありません。RAGはあくまで、検索したデータを一時的にプロンプトとしてAIに見せているだけだからです。
2025年現在、セキュリティ機能はさらに強化されており、「ChatSense」のような法人向けサービスを利用することで、外部へのデータ通信を遮断したり、アクセス権限に基づいた検索制御を行ったりすることが可能です。これにより、人事情報や技術機密などのセンシティブな情報であっても、安全に社内ネットワーク内だけで活用する仕組みを構築できます。
こちらはRAGワークフローにおけるセキュリティ確保の方法について解説したドキュメントです。エンタープライズレベルの安全対策について詳しく知りたい方は合わせてご覧ください。 https://learn.microsoft.com/en-us/azure/machine-learning/how-to-secure-rag-workflows?view=azureml-api-2
AIの再学習なしで最新情報を即座に反映できる
ビジネスのスピードが加速する現代において、情報は常に変化しています。新製品の仕様変更、組織改編による担当部署の変更、新しい規制への対応など、社内ナレッジは日々更新されていきます。
もしAI自体に知識を学習させていた場合、こうした変更があるたびに再学習が必要となり、運用が追いつかなくなります。しかしRAGであれば、データベースに保存されているファイルを更新するだけで作業は完了します。
例えば、朝に発表された新しい就業規則のPDFをフォルダにアップロードすれば、その直後からAIチャットボットは新しい規則に基づいて従業員の質問に答えられるようになります。この「リアルタイム性」は、変化の激しいビジネス環境において非常に大きなメリットとなります。常に最新の正しい情報を従業員に提供できる環境が、システム管理者による複雑な操作なしに実現できるのです。
根拠となるドキュメント(ソース)を提示できる
AIが生成した文章が本当に正しいのかどうか、不安に感じることはよくあります。特に業務上の意思決定や顧客への回答にAIを利用する場合、その情報の出所が不明確なままでは利用をためらってしまいます。
RAGシステムの優れた点は、回答とセットで「参照元ドキュメント」へのリンクを提示できることです。「この回答は、社内規定マニュアルの15ページと、2025年10月の通達文書に基づいています」といった形でソースが表示されます。
これにより、ユーザーは気になった箇所を原文で確認することができます。万が一AIが解釈を間違えていたとしても、原文を確認すればすぐに気づくことができるため、業務におけるリスク管理として機能します。AIを「ブラックボックス」にせず、あくまで人間を支援する「透明性の高いツール」として運用するためには、このソース提示機能が不可欠です。
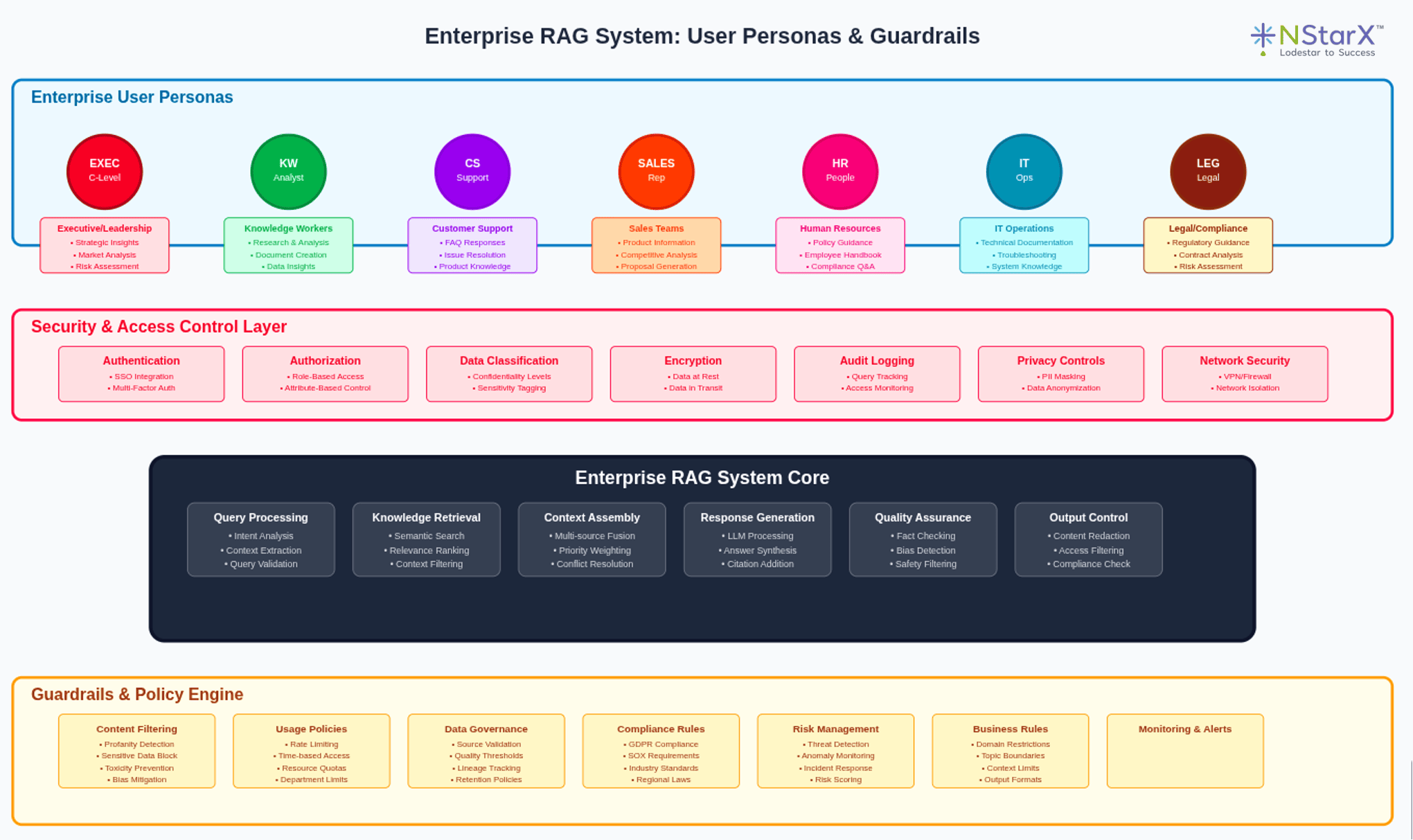
RAGを活用して社内データを学習なしで検索・生成させる具体的な4ステップ
ここでは、実際にRAGのシステムがどのように動いているのか、その裏側の処理フローを4つのステップに分けて解説します。
- データの選定と準備
- 質問のベクトル化
- 検索結果の統合
- 回答の生成
このプロセスを知ることで、RAG導入時にどのような準備が必要になるかが具体的にイメージできるようになります。
それでは、各ステップを順を追って解説します。
ステップ1:社内データ(ナレッジ)の選定とデータベース化
最初のステップは、AIに参照させたいデータを集め、検索可能な状態にすることです。社内に散らばっているPDFのマニュアル、Excelの商品リスト、Wordの報告書、社内Wikiのテキストデータなどを収集します。
単にファイルを集めるだけでなく、AIが読み取りやすいようにデータを加工する作業も重要です。例えば、画像として保存されているPDFならOCR(文字認識)やマルチモーダル機能での解析を行ったり、長すぎる文章を適切な長さ(チャンク)に分割したりします。
加工されたデータは、「ベクトルデータベース」と呼ばれる特殊なデータベースに格納されるのが一般的です。ここでは、文章の意味を数値(ベクトル)に変換して保存します。これにより、単なるキーワードの一致だけでなく、「意味が近い文書」を探し出せるようになります。この準備段階が、最終的な回答精度を大きく左右します。
ステップ2:ユーザーの質問をベクトル化して検索
準備が整ったら、実際にユーザーが質問を行います。例えば「今月の交通費精算の締め切りはいつ?」とチャットに入力したとします。
システムは、この質問文をAIを使って数値(ベクトル)に変換します。そして、ステップ1で作成したベクトルデータベースに対して検索をかけます。この時、キーワード検索のように「交通費」という単語が含まれているかだけでなく、質問の「意図」や「文脈」が近いデータを計算して探し出します。
ベクトル検索の利点は、表記ゆれに強いことです。「交通費」と「旅費」のような言葉の違いがあっても、意味が近ければ関連する経費精算のマニュアルを見つけ出すことができます。システムは、関連度が高い上位のドキュメントをいくつか抽出します。
ステップ3:検索結果と質問を合わせてAIに指示
検索によって、質問に関連する社内ドキュメントの断片が見つかりました。次のステップでは、これらをAIへの命令文(プロンプト)として組み立てます。
具体的には、以下のようなプロンプトをシステム内部で生成します。
「あなたは社内のヘルプデスク担当です。以下の【参考情報】のみに基づいて、ユーザーの【質問】に答えてください。
【参考情報】:(検索で見つかった経費精算マニュアルの抜粋テキスト)
【質問】:今月の交通費精算の締め切りはいつ?」
このように、ユーザーの質問だけでなく、カンニングペーパーとなる情報をセットにしてAIに渡すのです。このプロセスは完全に自動化されており、ユーザーの目には見えません。
ステップ4:回答の生成と参照元の提示
最後のステップで、AI(LLM)がプロンプトを受け取り、回答を生成します。AIは渡された【参考情報】を読み込み、「マニュアルによると、今月の締め切りは25日です」というような回答を作成します。
この時、GPT-5などの高性能なモデルであれば、複数のドキュメントにまたがる情報を整理し、高度な推論を用いて文脈を深く理解した上で答えることも可能です。また、事前に「参照元を明記すること」と指示しておけば、「(出典:経費精算規定 第3条)」のような注釈を付けることもできます。
生成された回答はチャット画面に表示され、ユーザーは社内データに基づいた正確な答えを得ることができます。これら4つのステップが、わずか数秒の間に行われるのがRAGの仕組みです。
ビジネスにおけるRAGの活用事例と学習させない利点
ここでは、実際のビジネス現場でRAGがどのように使われているのか、代表的な3つの事例を紹介します。
- ヘルプデスクの自動化
- 技術文書検索
- コールセンター支援
どのような業務課題がRAGによって解決されるのか、具体的なシーンを想像しながらご覧ください。
それでは、事例を一つずつ見ていきましょう。
社内ヘルプデスク・問い合わせ対応の自動化
最も導入が進んでいるのが、総務・人事・IT部門などへの社内問い合わせ対応です。「パスワードを忘れた」「有給休暇の申請方法は?」「年末調整の書き方がわからない」といった、定型的な質問は日々大量に発生し、担当者の時間を奪っています。
RAGを導入したチャットボットを設置することで、従業員は24時間いつでも即座に回答を得られるようになります。就業規則やITマニュアル、過去のFAQなどをデータベース化しておけば、AIが自動で該当箇所を探して回答してくれます。
これにより、管理部門の問い合わせ対応工数が大幅に削減され、より付加価値の高い業務に集中できるようになります。また、質問する側の従業員も、担当者の顔色を伺うことなく気軽に質問できるため、社内ルールの浸透や手続きの遅延防止にも効果を発揮しています。
こちらはChatGPTで問い合わせ対応を自動化する方法について解説した記事です。 合わせてご覧ください。
膨大なマニュアルや技術文書からの情報検索
製造業や建設業、システム開発などの現場では、過去の技術資料や膨大な仕様書、設計図面に関するドキュメントが存在します。トラブルが発生した際、過去の事例やマニュアルから解決策を探し出すのに、ベテラン社員でも数時間かかるというケースは珍しくありません。
RAGを活用すれば、数万ページに及ぶ技術文書の中から、必要な情報を瞬時にピンポイントで抽出できます。「過去に〇〇というエラーが出た際の対処法は?」と聞けば、関連する過去の報告書やマニュアルの該当ページを要約して提示してくれます。
特に、熟練技術者の退職に伴う「技能継承」が課題となっている企業では、ベテランのノウハウを形式知化してRAGに読み込ませることで、若手社員でも高度な情報検索が可能になり、組織全体の技術力底上げにつながっています。
顧客対応(コールセンター)におけるオペレーター支援
コールセンターやカスタマーサポートの現場でも、RAGは強力な武器になります。オペレーターは、顧客からの多様な質問に対して、即座に正確な回答をしなければなりません。しかし、製品数が多い場合やサービス内容が複雑な場合、すべてを暗記するのは不可能です。
RAGを導入したオペレーター支援システムでは、顧客との通話内容をリアルタイムで音声認識し、その会話内容に基づいて、AIが必要なマニュアルやFAQを自動的に画面に表示します。
例えば、顧客が「新プランの解約金について知りたい」と言った瞬間、AIが解約規定のドキュメントを表示し、回答案を提示します。これにより、オペレーターの保留時間が減少し、顧客満足度が向上します。また、新人オペレーターの教育期間を短縮できるというメリットもあり、採用難の解消にも寄与しています。
RAGの精度を高めるために必要な「学習(チューニング)」とは
ここでは、RAGの回答精度をさらに高めるためのポイントについて解説します。
- データの質と検索精度
- データの前処理(チャンキング)
- ドキュメント作成のコツ
「RAGを導入したけれど、思ったような回答が返ってこない」という失敗を防ぐために、非常に重要な内容です。RAGはモデルの学習は不要ですが、データの「整備」という学習のような工程が必要です。
それでは、精度の鍵となる要素を見ていきましょう。
回答精度は「データの質」と「検索精度」で決まる
「Garbage In, Garbage Out(ゴミを入れればゴミが出てくる)」という言葉がある通り、RAGの精度は、参照させるデータの品質に依存します。AIモデルがいかに高性能でも、検索されたドキュメントの内容が古かったり、矛盾していたり、読み取りにくい形式だったりすれば、まともな回答は生成できません。
また、検索エンジンの性能も重要です。ユーザーの質問意図を正しく汲み取れなければ、見当違いのドキュメントをAIに渡してしまいます。単純なキーワード一致だけでなく、意味の近さを測るベクトル検索のチューニングや、キーワード検索とベクトル検索を組み合わせる「ハイブリッド検索」の導入などが、精度の向上には不可欠です。RAGは導入して終わりではなく、どのような質問で検索ミスが起きているかを分析し、検索ロジックを調整していく運用が求められます。
こちらはテキスト埋め込みモデルの評価指標(MTEB)について解説した記事です。検索精度の世界的な評価基準について詳しく知りたい方は合わせてご覧ください。 https://huggingface.co/blog/mteb

データを読み込ませる際の前処理(チャンキング)の重要性
RAGにおいて最も技術的な工夫が必要なのが、データの「チャンキング(分割)」です。長いドキュメントをそのままデータベースに入れるのではなく、意味のまとまりごとに適切なサイズに分割して保存する必要があります。
例えば、100ページのPDFを1つのデータとして扱うと、情報が多すぎて検索の精度が落ちたり、AIが読み込むデータ量の上限を超えてしまったりします。逆に、短く切りすぎると文脈が失われてしまいます。
「章ごとに分ける」「500文字ごとに分ける」など、ドキュメントの性質に合わせて最適な分割ルールを決めることが重要です。また、図表やグラフが含まれる資料の場合、その内容をテキストで補足説明として付記するなどの前処理を行うことで、AIの理解度が格段に向上します。この地道なデータ整備作業こそが、RAG成功の秘訣です。
こちらはエンタープライズRAGシステムにおけるデータ品質の重要性について解説した記事です。実用的なデータ運用のヒントとして合わせてご覧ください。 https://nstarxinc.com/blog/the-2-5-million-question-why-data-quality-makes-or-breaks-your-enterprise-rag-system/
RAGに適したドキュメント作成のコツ
これから作成する社内ドキュメントに関しては、「AIが読みやすい形式」を意識することで、将来的なRAGの精度を高めることができます。
具体的には、主語を省略せずに明確に書くことや、「それ」「あれ」などの指示語を避けることが有効です。人間は前後の文脈から指示語の内容を補完できますが、分割されたデータの一部だけを検索された場合、AIには「それ」が何を指しているのか判断できません。
また、Q&A形式でドキュメントを作成しておくのも非常に効果的です。質問と回答がセットになっているデータは、ユーザーの質問とのマッチング精度が高く、AIにとっても回答の生成が容易になります。「AIフレンドリー」な文書作成ルールを社内で共有することが、AI活用時代の新しい業務スキルとなるでしょう。
RAG導入時によくある質問:学習データの扱いやセキュリティ
最後に、RAG導入を検討している企業から頻繁に寄せられる質問に回答します。
- 情報漏洩のリスク
- プログラミングの必要性
- 対応ファイル形式
これらの疑問を解消し、安心して導入検討を進めていただけるように整理しました。
それでは、よくある質問とその回答を見ていきましょう。
RAGを使えば社内データが外部に漏れることはありませんか?
適切なサービス選定と設定を行えば、外部に漏れることはありません。
Azure OpenAI ServiceやOpenAIのEnterpriseプランなど、企業向けに提供されているサービスでは、「入力データ(プロンプトおよびアップロードしたファイル)をAIモデルの学習に使用しない」という規約が明記されています。
また、RAGのシステム構築においても、社内のプライベートネットワーク内にデータベースを構築することで、データがインターネット上の一般公開領域に出ることを防げます。ただし、無料版の個人向けChatGPTなどに社内データをコピー&ペーストしてしまうと学習されるリスクがあるため、従業員に対して「会社が認可したRAG環境以外では社内データを使わない」というガイドラインを徹底することが重要です。
プログラミング知識がなくてもRAGは構築できますか?
はい、現在はノーコードまたはローコードでRAGを構築できるツールが増えています。
以前はPythonなどのプログラミング言語を使って一から開発する必要がありましたが、現在はMicrosoftの「Copilot Studio」や、国産のRAG構築SaaSなどが多数登場しており、ブラウザ上の操作だけでファイルをアップロードし、チャットボットを作成できるようになっています。
ただし、より回答精度を高めたい場合や、社内の複雑な基幹システムと連携させたい場合は、エンジニアによるカスタマイズが必要になることもあります。まずは手軽なツールでPoC(概念実証)を行い、効果を確認してから本格的な開発に進むというアプローチがおすすめです。
PDFやExcelなどのデータも読み込めますか?
はい、主要なビジネス文書形式のほとんどに対応可能です。
PDF、Word、Excel、PowerPoint、テキストファイル、CSVなどは、一般的なRAGツールであれば標準で読み込むことができます。
ただし、注意点として「画像化されたPDF(スキャンデータ)」や「複雑なレイアウトのExcel」は、AIが正しく文字を認識できない場合があります。最新モデルは画像認識も可能ですが、精度を安定させるにはOCRツールを使ってテキストデータに変換したり、AIが理解しやすいようにデータを整形(CSV化など)したりする工夫が必要です。特にExcelの巨大な表などは、そのまま読み込ませるよりも、データベース形式に変換するか、重要な数字を文章化して読み込ませる方が精度が出やすい傾向にあります。
社員は1日の20%を「探し物」に費やしている?RAGが解消する「見えないコスト」の正体
「社内のあの資料、どこにあったっけ?」「このエラーの対処法、以前誰かがチャットで共有していたはずなのに見つからない……」
あなたの会社でも、このような光景は日常茶飯事ではないでしょうか。実は、私たちは想像以上に多くの時間を「情報の検索」という、直接的な利益を生まない作業に費やしています。
マッキンゼー・グローバル・インスティテュートの調査によると、ナレッジワーカー(知的労働者)は、週の労働時間の約20%を社内情報の検索や収集に費やしていることが明らかになっています。これは、週5日勤務の場合、丸1日は「探し物」だけで終わっている計算になります。
RAG(検索拡張生成)の導入は、単にAIが質問に答えてくれるという便利さ以上の経済的価値を秘めています。それは、この膨大な「探索コスト」をほぼゼロにし、社員が本来の業務である「意思決定」や「創造的な作業」に充てる時間を劇的に増やすことができるからです。
「探す」という行為をなくし、必要な情報が向こうからやってくる環境を構築することこそが、生成AI活用における最大のROI(投資対効果)と言えるでしょう。
引用元:
McKinsey Global Institute. “The social economy: Unlocking value and productivity through social technologies” (2012) によると、ナレッジワーカーは労働時間の19%を情報の検索と収集に費やしていると報告されています。
まとめ
社内独自のデータをAIに活用させたいというニーズは急速に高まっていますが、記事で解説したようなRAGの環境構築や、セキュリティを考慮した運用ルールの策定には、専門的な知識と多くのリソースが必要です。
「RAGに興味はあるが、社内にエンジニアがいない」「セキュリティ面が不安で導入に踏み切れない」という企業も多いのが実情です。
そこでおすすめしたいのが、Taskhub です。
Taskhubは、日本初のアプリ型インターフェースを採用した生成AI活用プラットフォームであり、RAGのような高度なデータ活用も、驚くほど簡単に実現できる環境を提供しています。
社内ドキュメントを活用した業務はもちろん、メール作成や議事録の要約、データ分析など、200種類以上の実用的なAIタスクがあらかじめパッケージ化されており、アプリを選ぶ感覚で直感的に業務へ導入できます。
セキュリティ面においても、Azure OpenAI Serviceを基盤とした堅牢な環境に加え、PマークやISMS認証を取得しており、機密性の高い社内データも安心して扱える設計となっています。
さらに、導入企業には専任のAIコンサルタントが伴走し、RAGを活用した具体的な業務フローの構築までサポートするため、ノウハウがない企業でも最短距離で成果を出すことが可能です。
技術的なハードルを一切感じることなく、高度な生成AI活用をスタートさせたい方は、ぜひTaskhubの機能や成功事例をまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで社内の「知」を最大限に活用し、御社の生産性を次なるステージへと引き上げましょう。






