

「社内データを活用したRAGシステムを作りたいけれど、コストはかけられない」
「無料ツールを使って構築してみたものの、回答の精度が低くて実用化できない」
このような課題に直面している開発者や担当者の方も多いのではないでしょうか?
RAG(検索拡張生成)は、生成AIに外部知識を与える強力な技術ですが、有料のデータベースやAPIを利用すると維持費が高額になりがちです。しかし、近年のオープンソース技術や各社の無料プランをうまく組み合わせることで、コストをかけずに高性能なRAGを構築することは十分に可能です。
本記事では、無料で使えるおすすめのRAGツール5選と、実際にノーコードおよびローカル環境で構築するための具体的な手順を解説します。
生成AIを活用したシステム開発支援を行っている弊社の知見をもとに、実務で使えるレベルのノウハウを厳選しました。
コストを抑えつつ、精度の高いRAGシステムを構築したい方は、ぜひ最後までご覧ください。
そもそもRAGは無料でどこまでできる?有料版との違いと限界
ここからは、RAGを無料で構築する場合の可能性と、有料版との具体的な違いについて解説します。
- 個人の検証レベルであれば無料でも十分な機能
- エンタープライズ版と無料版のスペック差
- セキュリティ面での留意点
無料といっても、完全に機能が制限されるわけではありません。適切なツール選定と構成を行えば、実用的なプロトタイプを作成することは十分に可能です。
それでは、一つずつ順に解説します。
個人開発や検証レベルなら無料ツールで十分可能
RAGを無料で構築する場合でも、個人の学習用や社内での概念実証(PoC)レベルであれば、十分実用的なシステムを作ることが可能です。
最近では、Meta社のLlama 3.2や、GoogleのGemma 2といった高性能なオープンソースLLM(大規模言語モデル)が無料で公開されており、これらをローカル環境で動作させることで、LLMの利用料をゼロにできます。また、2025年8月にOpenAIからリリースされたGPT-5のような最新モデルも、APIの無料枠や低コストモデル(gpt-5-miniなど)を活用することで、初期費用を抑えて検証できます。
特にGPT-5は、複雑な質問に対して自動的に「長考(Thinking)」モードに切り替わる機能を持っており、RAGにおいて重要な「検索した情報を正しく解釈して回答する能力」が飛躍的に向上しています。このような最新技術も、使用量に注意すれば無料で試すことができるため、スモールスタートには最適な環境が整っています。
こちらはGPT-5のリリース日、機能、料金、GPT-4との違いを詳細に解説した記事です。 合わせてご覧ください。
【比較表】無料版RAGとエンタープライズ版(有料)の決定的な違い
無料で構築したRAGと、有料のエンタープライズ版RAGには、主に運用面と性能面で明確な違いがあります。無料版はあくまで「リソースに制限がある状態」で動くことが前提です。
まず、処理速度と容量が大きく異なります。無料のベクトルデータベースやAPIには、保存できるドキュメント数や1分間あたりのリクエスト数(RPM)に厳しい制限が設けられています。たとえば、数百ページのPDFを読み込ませる程度なら問題ありませんが、全社マニュアル数万件を検索対象にするような大規模運用は無料枠では困難です。
また、可用性とサポート体制も決定的な違いです。有料版ではSLA(サービス品質保証)が設定され、サーバーダウン時のサポートも受けられますが、無料ツールやローカル環境での自作RAGでは、エラーが発生した際のトラブルシューティングをすべて自力で行う必要があります。ビジネスで停止が許されないシステムを構築する場合は、この点を考慮する必要があります。
こちらは生成AIを企業で活用する際のメリットや導入の注意点を網羅的に解説したガイド記事です。 合わせてご覧ください。
セキュリティやデータプライバシーで注意すべき点
RAGを無料で構築する際に最も注意しなければならないのが、データの取り扱いです。特にクラウド型の無料サービスを利用する場合、入力したデータがAIの学習に利用される可能性があるかを確認する必要があります。
多くの無料チャットUIやWebサービスでは、ユーザーが入力したプロンプトやアップロードしたドキュメントの内容が、サービス改善やモデルの再学習に使われる規約になっていることがあります。社外秘の情報や個人情報を含むドキュメントをRAGに読み込ませる場合、これは重大なセキュリティリスクとなります。
一方で、ローカル環境で完結するオープンソースソフトウェア(OSS)を使用する場合や、OpenAIのAPI利用(学習利用オプトアウト設定済み)であれば、データが外部に漏れるリスクは最小限に抑えられます。無料でRAGを作る際は「データがどこに保存され、何に使われるか」を利用規約で必ずチェックし、機密情報の扱いは慎重に行うようにしてください。
こちらは生成AIを企業利用する際のリスクと対策について詳細に解説した記事です。 合わせてご覧ください。
RAGを無料で構築できるおすすめツール・サービス5選
ここからは、無料でRAGの構築や実験が可能なツール・サービスを5つ紹介します。
- Dify
- Pinecone
- Weaviate
- Google Cloud Vertex AI
- NVIDIA LaunchPad
プログラミング不要で使えるものから、高度なカスタマイズが可能な開発者向けプラットフォームまで幅広くピックアップしました。
それぞれの特徴を見ていきましょう。
Dify|ローカル環境でも使える高機能なオープンソースツール
Difyは、RAGを含む生成AIアプリをノーコードまたはローコードで開発できる、現在最も注目されているオープンソースプラットフォームです。
最大の特徴は、直感的なUIでワークフローを組める点です。ドキュメントのアップロードから、テキストの分割(チャンク化)、ベクトル化、そしてLLMへの回答指示までを、画面上の操作だけで完結できます。クラウド版には無料プランがあり、手軽に試すことができますが、Dockerを使って自分のPC(ローカル環境)にインストールすれば、すべての機能を完全無料で使い倒すことができます。ソースコードやインストール手順はGitHubで公開されています。 https://github.com/langgenius/dify
また、Difyは多くのLLMやベクトルデータベースと連携可能です。OpenAIやAnthropicなどのAPIはもちろん、Ollamaと連携してローカルLLMを使用する設定もスムーズに行えます。RAGの精度を高めるための「リランク機能」なども標準でサポートしており、初心者から上級者まで幅広くおすすめできるツールです。
Pinecone|ベクトルデータベースの定番(無料枠あり)
Pineconeは、RAG構築に欠かせない「ベクトルデータベース」の代表的なマネージドサービスです。
RAGでは、テキストデータを数値(ベクトル)に変換して保存し、類似検索を行う必要があります。Pineconeはこのベクトル検索に特化したクラウドデータベースであり、サーバーの構築や管理が不要で、APIキーを取得するだけですぐに利用を開始できます。
無料プラン(Starterプラン)が用意されており、1つのインデックス(データベースの単位)を作成して、小規模なプロジェクトや検証を行うのに十分な容量を提供しています。最新の料金体系や仕様については公式サイトをご確認ください。 https://www.pinecone.io/pricing/
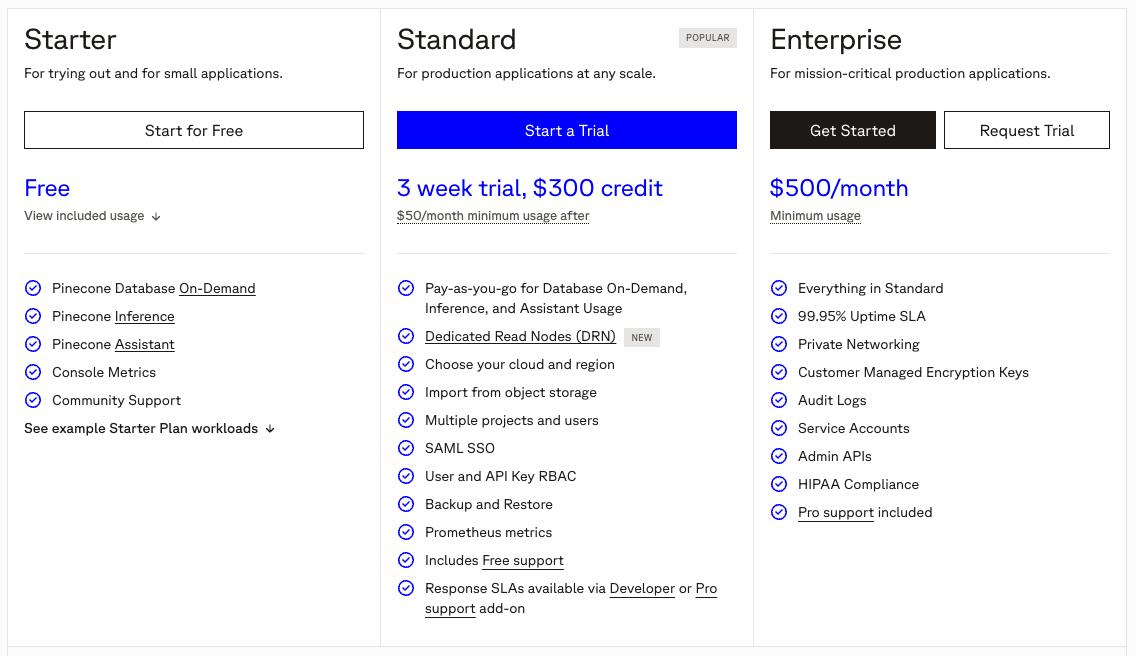
Pythonなどのプログラミング言語から簡単に操作できるライブラリが充実しており、ドキュメントも豊富です。まずは手軽にベクトル検索の仕組みを理解したい、サーバー管理の手間を省いてRAGを試作したいという場合に最適な選択肢です。
Weaviate|画像や音声も扱えるマルチモーダル対応DB
Weaviateは、テキストだけでなく画像や音声などのデータも扱える、マルチモーダル対応のオープンソース・ベクトルデータベースです。
文章の検索だけでなく、画像検索や、画像とテキストを組み合わせた複合的なRAGシステムを構築したい場合に強みを発揮します。また、キーワード検索とベクトル検索を組み合わせた「ハイブリッド検索」の機能が強力で、単なる意味検索だけでは拾いきれない専門用語の検索精度を向上させることができます。
WeaviateもPineconeと同様にクラウド版の無料トライアルがありますが、Dockerコンテナとして提供されているため、ローカル環境や自社のサーバーにデプロイすれば、制限なく無料で使用し続けることが可能です。 https://weaviate.io/pricing
データの機密性を保持しながら、高度な検索機能を実装したい開発者に向いています。
Google Cloud Vertex AI|高度なRAG機能を試せるクラウド基盤
Google CloudのVertex AIは、Googleの最新AIモデルや検索技術を利用できる統合プラットフォームです。
Google検索の技術を応用した「Vertex AI Search」を利用することで、非常に精度の高いRAGシステムを構築できます。特に、Googleの基盤モデルであるGeminiなどを活用し、大量のドキュメントから正確な回答を生成する能力に長けています。
通常は従量課金のサービスですが、Google Cloudの新規登録時に付与される300ドル分の無料クレジットや、一部のプロダクトに用意されている無料枠を活用することで、実質無料で検証を行うことができます。エンタープライズレベルのインフラやセキュリティ機能が整っているため、将来的に本格的なビジネス利用を視野に入れている場合の検証環境として推奨されます。
NVIDIA LaunchPad|GPUリソースを使ってRAG実験が可能
NVIDIA LaunchPadは、NVIDIAのハードウェアとソフトウェアスタックを無料で体験できるプログラムです。
RAGやLLMの実験には高性能なGPUが必要不可欠ですが、個人で高価なGPUを用意するのはハードルが高いものです。LaunchPadに申請して承認されると、短期間ですがNVIDIAのサーバー上のリソースにアクセスし、用意されたラボ(ハンズオン形式のチュートリアル)を通じて、エンタープライズ向けのRAG構築を体験できます。
特に「NVIDIA AI Enterprise」というソフトウェアスイートを使ったRAGの最適化や、高速な推論エンジンの動作確認が可能です。自作するというよりは、最先端のハードウェア環境でRAGがどのように動作するのかを学びたい、あるいは導入前の性能検証を行いたいというエンジニア向けのサービスと言えます。
【ノーコード】完全無料でローカル環境にRAGを構築・検証する手順
ここでは、プログラミングコードを書かずに、完全無料で自分のPC内にRAG環境を構築する手順を紹介します。
- LM StudioとXinferenceでローカルLLMを動かす準備
- Difyを使ってローカルLLMと知識データを連携させる
- テスト用ドキュメントの読み込みとベクトル化
- 実際の回答精度を検証する
この手順通りに進めれば、外部にデータを送信することなく、セキュアなRAGシステムが完成します。
具体的なステップを見ていきましょう。
LM StudioとXinferenceでローカルLLMを動かす準備
まずは、RAGの頭脳となるLLMを自分のPC上で動かす環境を整えます。これには「LM Studio」や「Xinference」といったツールが便利です。
LM Studioは、Hugging Faceなどで公開されているオープンソースのLLM(Llama 3やMistralなど)を簡単にダウンロードし、チャット形式で実行できるアプリケーションです。商用利用時のライセンス形態については公式ブログなどで確認しておくと安心です。 https://lmstudio.ai/blog/free-for-work
特筆すべきは、ローカルサーバー機能を持っている点です。ボタン一つでOpenAI互換のAPIエンドポイントを立ち上げることができ、後述するDifyなどの外部ツールから、まるでOpenAIのAPIを使っているかのようにローカルLLMを操作できるようになります。
インストール後、自分のPCのスペック(特にGPUメモリやメインメモリ)に合ったモデルを選んでダウンロードし、Local Serverを開始すれば準備完了です。これにより、インターネット接続がなくてもAIが動く土台ができあがります。
Difyを使ってローカルLLMと知識データを連携させる
次に、RAGのアプリケーション部分を担うDifyをインストールします。公式サイトからDocker Composeなどの設定ファイルをダウンロードし、Docker Desktopを使って起動します。
Difyが起動したら、設定画面の「モデルプロバイダー」から、先ほどLM Studioなどで立ち上げたローカルLLMを登録します。「OpenAI-API-compatible」という項目を選び、LM Studioが表示しているIPアドレスとポート番号(例:http://host.docker.internal:1234/v1)を入力します。これで、DifyからローカルのAIモデルを呼び出せるようになります。
続いて「ナレッジ」を作成します。これがRAGのデータベース部分になります。Difyはデフォルトで、テキストをベクトル化するための埋め込みモデル(Embedding Model)も必要とします。これもローカルで動かすか、あるいはHugging FaceのAPIなどを設定して利用可能な状態にします。
テスト用ドキュメントの読み込みとベクトル化
環境が繋がったら、実際にRAGで検索させたいドキュメントを読み込ませます。
Difyのナレッジ作成画面で「ドキュメントのアップロード」を選択し、PDFやWord、テキストファイルなどをドラッグ&ドロップします。ここで重要なのが「チャンク化(分割設定)」です。AIは一度に読める文字数に限りがあるため、長い文章を適切な長さに区切る必要があります。Difyでは「自動」設定でも動きますが、精度を上げたい場合は「500文字区切り」など手動で設定することも可能です。
設定を完了して「保存して処理」ボタンを押すと、ドキュメント内のテキストが自動的に抽出され、AIが理解できる数値データ(ベクトル)に変換されてデータベースに保存されます。この処理時間はドキュメントの量とPCのスペックに依存しますが、数ファイル程度なら数分で完了します。
実際の回答精度を検証する(ハルシネーションの確認)
最後に、チャット画面を作成して動作確認を行います。
Difyの「スタジオ」から「チャットボット」アプリを新規作成し、先ほど作成したナレッジを「コンテキスト」として関連付けます。これで、チャットボットはユーザーの質問に対して、ナレッジ内の情報を検索してから回答するようになります。
検証時は、ドキュメントに書かれている具体的な内容について質問してみましょう。例えば「社内規定の第5条について教えて」といった質問に対し、正確に引用できているかを確認します。この際、AIが事実に基づかない嘘をつく「ハルシネーション」が起きていないかチェックすることが重要です。もし回答がおかしい場合は、読み込ませるデータの区切り方を変えたり、プロンプト(指示文)で「ナレッジにある情報のみを使って回答してください」と制約を加えたりして調整します。
こちらはAIのハルシネーションを防ぐ方法について解説した記事です。 合わせてご覧ください。
【Python】ライブラリを使ってRAGを自作開発する実装ステップ
ここからは、エンジニア向けにPythonを使ってRAGをスクラッチで開発する手順を解説します。
- 開発環境の構築(LangChainなどのライブラリインストール)
- Webデータの収集とテキスト分割(チャンク化)の実装
- 文章のベクトル化とベクトルストア(DB)への保存
- 検索エンジン(Retriever)と生成AIの統合
- StreamlitなどでチャットUIを作成してブラウザで動かす
ライブラリを活用することで、柔軟で拡張性の高いシステムを構築できます。
順を追って解説します。
開発環境の構築(LangChainなどのライブラリインストール)
PythonでRAGを開発する場合、事実上の標準ライブラリとなっているのが「LangChain」や「LlamaIndex」です。これらはLLM、ベクトルデータベース、ドキュメントローダーなどを繋ぎ合わせるための便利な機能が詰まっています。
まずはPythonの仮想環境を作成し、必要なライブラリをpipコマンドでインストールします。最低限必要なのは、langchain、langchain-openai(または使用するLLM用のパッケージ)、そしてベクトル計算のためのライブラリです。実装の際は、公式のRAGガイドなども参考にしながら進めてください。 https://docs.langchain.com/oss/python/langchain/rag
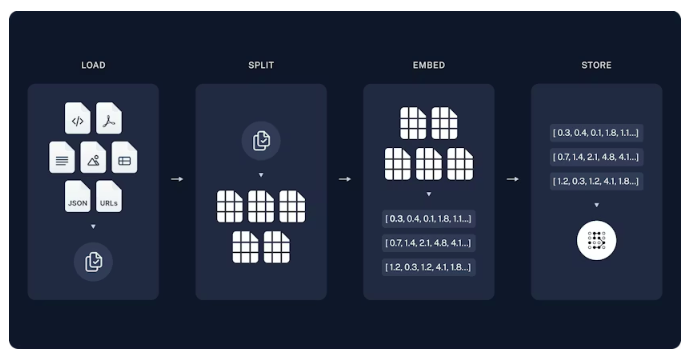
また、最新のGPT-5などを使用する場合は、OpenAIのSDKも最新版にアップデートしておきましょう。APIキーを環境変数(.envファイルなど)に設定し、プログラムから呼び出せるように準備します。この段階で、シンプルなAPIコールが通るかテストコードを書いて確認しておくと、後のデバッグがスムーズになります。
Webデータの収集とテキスト分割(チャンク化)の実装
RAGの回答ソースとなるデータを準備します。社内ドキュメントだけでなく、特定のWebサイトの情報を元に回答させたい場合は、WebスクレイピングやWebローダーを使用します。
LangChainにはWebBaseLoaderなどの便利なローダーが含まれており、URLを指定するだけでHTMLからテキストを抽出できます。取得したテキストはそのままでは長すぎるため、RecursiveCharacterTextSplitterなどのクラスを使って分割(チャンク化)します。
この分割サイズ(Chunk Size)と、分割の重なり(Chunk Overlap)の設定はRAGの精度に直結します。一般的には500〜1000トークン程度で分割し、文脈が途切れないように10〜20%程度のオーバーラップを持たせることが推奨されます。日本語の場合は、句読点や改行で区切られるように設定を調整するのがコツです。
文章のベクトル化とベクトルストア(DB)への保存
分割したテキストを、AIが検索しやすい形式(ベクトル)に変換して保存します。これを「Embedding(埋め込み)」と呼びます。
無料かつローカルで実装する場合、ベクトルデータベースには「ChromaDB」や「FAISS」がよく使われます。これらはライブラリとしてインストールでき、ファイルベースでデータを保存できるため、別途サーバーを立てる必要がありません。
プログラム上では、先ほど分割したテキストリストと、埋め込みモデル(OpenAIのtext-embedding-3-smallや、Hugging Faceの無料モデルなど)を渡して、データベースを作成する関数を実行します。これにより、テキストの意味が数値化され、類似性の高い文章を高速に検索できるインデックスが作成されます。
検索エンジン(Retriever)と生成AIの統合
データベースの準備ができたら、いよいよ検索と生成を組み合わせます。ここがRAG(Retrieval-Augmented Generation)の核となる部分です。
LangChainでは、作成したベクトルストアをRetriever(検索器)として定義します。ユーザーからの質問文を受け取り、Retrieverがデータベースから関連度の高いテキストチャンクを数個ピックアップします。
次に、この「ピックアップされた情報」と「ユーザーの質問」をセットにして、LLMへのプロンプトに埋め込みます。「以下の参考情報を元に、ユーザーの質問に答えてください」という指示文を作成するわけです。これをcreate_retrieval_chainやLangGraphなどで実装することで、検索から回答生成までの一連の流れが自動化されます。GPT-5などの高度なモデルを使えば、検索された情報の矛盾点を指摘したり、統合して推論したりする処理も可能です。
StreamlitなどでチャットUIを作成してブラウザで動かす
Pythonスクリプトとして動くだけでは使い勝手が悪いため、ブラウザから操作できるチャット画面を作成します。PythonだけでWebアプリが作れる「Streamlit」が非常に便利です。
Streamlitを使えば、わずか数十行のコードでチャットボットのUIを実装できます。st.chat_inputで入力欄を作り、st.chat_messageで会話履歴を表示させる機能を組み合わせます。
バックエンドの処理として、先ほど作ったRAGのチェーンを呼び出し、ユーザーの入力を渡して回答を表示させるように繋ぎ込みます。これにより、見た目はChatGPTと同じようなチャットツールでありながら、裏側では独自のデータを参照して回答するオリジナルアプリが完成します。
Streamlit Community Cloudを使えば、作成したアプリを無料でWeb上に公開することも可能です(ただし公開データになるため注意)。チャットアプリの構築チュートリアルも公式に用意されています。 https://docs.streamlit.io/develop/tutorials/chat-and-llm-apps/build-conversational-apps
無料RAGの回答精度を上げるためのチューニングポイント
ここまで紹介した手順でRAGは動きますが、さらに精度を高めるためのテクニックを紹介します。
- ハイブリッド検索(キーワード+ベクトル)を導入する
- Rerank(リランク)モデルを使って検索結果を並び替える
- プロンプトエンジニアリングで回答の形式を制御する
これらの工夫を取り入れることで、無料ツールであっても実用レベルの回答精度に近づけることができます。
それぞれの詳細を解説します。
ハイブリッド検索(キーワード+ベクトル)を導入する
一般的なRAGで使われる「ベクトル検索」は、文章の意味や文脈を理解するのが得意ですが、特定の製品型番や固有名詞、完全一致が必要なキーワードの検索には弱いという側面があります。
これを補うために推奨されるのが「ハイブリッド検索」です。これは、従来の「キーワード検索(BM25など)」と「ベクトル検索」の両方を行い、それぞれの結果を統合する方法です。
例えば、「エラーコード E-1234 の対処法」という質問に対して、ベクトル検索では「エラーの一般的な対処法」という曖昧な類似結果を拾ってしまう可能性がありますが、キーワード検索を併用すれば「E-1234」という文字列が含まれるドキュメントをピンポイントでヒットさせることができます。多くのベクトルデータベースやRAGツールがこの機能に対応し始めており、検索漏れを劇的に減らすことができます。
Rerank(リランク)モデルを使って検索結果を並び替える
RAGの精度が低い原因の一つに、「検索でヒットはしたが、本当に重要な情報が下位に埋もれてしまい、LLMに渡されていない」というケースがあります。これを解決するのが「Rerank(リランク)」です。
Rerankは、一次検索(ベクトル検索など)で抽出された上位数十件のドキュメントに対して、別の高精度なモデルを使って「質問に対する関連度」を再採点し、並び替えを行うプロセスです。
CohereなどのAPIが有名ですが、ローカル環境で動かせるBGE-Rerankerなどのオープンモデルも存在します。Hugging Faceなどでモデルの仕様やダウンロード方法を確認できます。 https://huggingface.co/BAAI/bge-reranker-v2-m3
検索と生成の間にこのRerank処理を挟むことで、LLMには「本当に最も関連性の高い情報」だけを渡すことができるようになり、結果としてハルシネーション(嘘の回答)の抑制や、回答の的確さが大幅に向上します。
プロンプトエンジニアリングで回答の形式を制御する
システム側の仕組みだけでなく、LLMへの指示出し(プロンプト)を工夫することも、無料で精度を上げる重要な要素です。
RAG特有のプロンプトとして、「System Prompt」に明確な役割と制約を与えます。「あなたは社内のITヘルプデスク担当です」「提供されたコンテキスト(参考情報)のみに基づいて回答してください」「情報がない場合は『分かりません』と答えてください」といった指示を徹底させます。
また、2025年以降のモデル(GPT-5など)では、思考プロセスを含めたプロンプトが有効です。「まず提供された情報を分析し、次に質問との関連性を評価し、最後に回答を生成してください」といったステップバイステップの指示を与えることで、複雑な質問に対しても論理破綻の少ない回答を引き出すことができます。これは追加コストゼロで実践できる最も効果的なチューニングの一つです。
こちらはAIへの指示出しの基本となるプロンプトの概念や、すぐに使える日本語のプロンプト例を紹介した記事です。 合わせてご覧ください。
RAGを無料で運用する際によくある質問(FAQ)
最後に、RAGを無料で運用する際によく寄せられる疑問に回答します。
- 日本語のドキュメントでも精度は出ますか?
- APIの無料枠(OpenAIなど)を超えたらどうなりますか?
- 社内情報を読み込ませても情報漏洩しませんか?
導入前にこれらの懸念点を解消しておきましょう。
日本語のドキュメントでも精度は出ますか?
はい、日本語のドキュメントでも十分な精度が出ます。ただし、使用する「埋め込みモデル(Embedding Model)」と「LLM」の選定が重要です。
海外製の古いモデルでは日本語の処理が苦手な場合がありますが、OpenAIのtext-embedding-3シリーズや、多言語対応の最新オープンソースモデル(BGE-M3やmultilingual-e5など)を使用すれば、日本語の意味を正しくベクトル化できます。また、生成を行うLLM自体も、GPT-4oやGPT-5、あるいは日本語データで追加学習された国産LLMなどを使用することで、自然で正確な日本語回答を得ることが可能です。
APIの無料枠(OpenAIなど)を超えたらどうなりますか?
OpenAIなどの商用APIには、最初の数ヶ月間使える無料クレジット(5ドル分など)が付与されていることがありますが、これを使い切るか有効期限が切れると、APIリクエストがエラーとなりRAGシステムが動かなくなります。
継続的に無料運用したい場合は、API課金が発生しない「ローカルLLM(OllamaやLM Studio)」に切り替えるか、Google Cloud Vertex AIなどの別の無料トライアル枠を活用して乗り換える必要があります。APIを利用する場合は、ダッシュボードで常に使用量を確認し、予算上限(Budget Limit)を設定して、意図しない課金や停止を防ぐ運用管理が必要です。
社内情報を読み込ませても情報漏洩しませんか?
この点が最も重要です。無料のWebサービス(ChatGPTの無料版チャット画面など)に直接社内データを貼り付けると、そのデータがAIの学習に使われ、他社への回答として流出するリスクがゼロではありません。
しかし、API経由での利用(OpenAI APIなど)や、本記事で紹介した「ローカル環境(自分のPC内)で完結するRAG」であれば、データは外部に送信されない、または学習利用されないポリシーになっているため、情報漏洩のリスクは極めて低くなります。企業で導入する場合は、必ず「APIデータプライバシーポリシー」を確認するか、外部通信を遮断したローカルネットワーク内での運用を推奨します。
【警告】「とりあえず無料で作ってみる」が招く、見えないコストとセキュリティリスク
「無料でRAGが構築できるなら、まずは試してみよう」——。その判断は正しいですが、もしそれをそのまま実業務に適用しようと考えているなら、一度立ち止まる必要があります。ガートナーの予測によると、生成AIプロジェクトの多くは、概念実証(PoC)の段階で停滞し、本番運用に至らないケースが非常に多いとされています。その最大の要因の一つが、運用フェーズにおける「見えないコスト」と「リスク管理」の甘さです。
無料ツールやローカル環境での構築は、初期費用こそゼロですが、その後のメンテナンスコストは指数関数的に増大する傾向があります。
- 検索精度の維持: 日々増え続ける社内データに合わせて、ベクトルデータベースを常に最新の状態に保つためのパイプライン構築が必要です。
- 依存ライブラリの管理: オープンソースソフトウェアは更新頻度が高く、ある日突然バージョンアップで動かなくなるリスクと隣り合わせです。
- シャドーAIのリスク: 個人のPC内で完結しているうちは安全ですが、便利だからとネットワーク経由で他者に公開した瞬間、適切なアクセス制御がなされていないと、機密情報が全社員に見えてしまう事故につながります。
「タダより高いものはない」という言葉通り、安易な自作RAGの運用は、結果として高額なエンジニア人件費やセキュリティ事故という代償を払うことになりかねません。
引用元:
ガートナーは、生成AIの導入において、多くの企業がリスク管理とデータガバナンスの複雑さを過小評価しており、これがプロジェクトの失敗や遅延の主要因になると警告しています。(Gartner, “Hype Cycle for Generative AI, 2023” および関連するプレスリリースより)
【実践】プロはこう見る!RAGの精度を左右する「データの前処理」の極意
記事ではツールの使い方が解説されていますが、実はRAGの回答精度を決定づけるのは、ツールの性能以上に「読み込ませるデータの質」です。プロフェッショナルな開発現場では、単にPDFをアップロードするだけでなく、以下のような泥臭い「データの前処理」に多くの時間を割いています。
- ノイズの除去: ヘッダー、フッター、ページ番号、意味のない記号列などをプログラムで削除してからベクトル化します。これらが残っていると、検索時にノイズとなり、AIが混乱する原因になります。
- メタデータの付与: 文章の塊(チャンク)ごとに、「作成日時」「部門名」「ドキュメントの種類」などのタグ情報を付与します。これにより、検索時に「2024年の営業部の資料のみ」といったフィルタリングが可能になり、精度が劇的に向上します。
- 構造化データの活用: 表形式のデータやグラフの数値は、そのままテキスト化してもAIは理解しにくいものです。これらをCSVやMarkdown形式に整形し直す、あるいは要約テキストを別途作成して付与するといった工夫が、回答の正確性を大きく左右します。
ツール選びも大切ですが、まずは「AIが読みやすいデータ」を用意することこそが、成功への近道です。
まとめ
企業はコスト削減や業務効率化の課題を抱える中で、自社データを活用したRAGシステムの構築がDX推進の鍵として注目されています。
しかし、本記事で解説したように、無料ツールでの構築には高度な技術力と継続的なメンテナンスが必要であり、「セキュリティの担保」や「運用リソースの確保」が大きな壁となって、導入を断念する企業も少なくありません。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
たとえば、社内ドキュメントの要約や分析、議事録からのネクストアクション抽出、レポート自動生成など、RAGシステムで実現したい業務効率化の多くを、「アプリ」として選ぶだけで、誰でも直感的にAIを活用できます。
しかも、Azure OpenAI Serviceを基盤にしているため、金融機関レベルのデータセキュリティが万全で、自作システムで懸念される情報漏えいの心配もありません。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「技術的なことはわからないが、安全にAIを使いたい」という企業でも安心してスタートできます。
導入後すぐに効果を実感できる設計なので、複雑な環境構築や終わりのないメンテナンス作業に疲弊することなく、すぐに本質的な業務改善が図れる点が大きな魅力です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“安全かつ最速の生成AI活用”を体験し、御社のDXを一気に加速させましょう。






