

「自社サービスにLLMを組み込みたいが、不適切な回答や情報漏洩が怖い」
「OpenAIのモデレーションAPIは便利だが、自社の独自ルールを適用できないだろうか?」
こういった悩みを抱える開発者や企業も多いのではないでしょうか。
大規模言語モデル(LLM)の導入が進む一方で、その安全性をどう確保するかは重大な課題です。
生成AIの企業利用におけるリスクと対策について、より包括的に知りたい方は、こちらの記事も合わせてご覧ください。
本記事では、OpenAIがオープンウェイトモデルとして公開した「gpt-oss-safeguard」について、その概要から具体的な使い方、API連携、独自の安全ポリシーを設定するプロンプト例までを徹底的に解説します。
この記事を読めば、LLMの入出力を自社の基準で管理し、より安全なAIアプリケーションを構築するための具体的な方法がわかります。
ぜひ最後までご覧ください。
gpt-oss-safeguardとは?OpenAIが公開したAIの「安全審判」
ここからは、gpt-oss-safeguardの基本的な概要と、その重要性について解説します。
- gpt-oss-safeguardの概要と目的
- なぜ今gpt-oss-safeguardが重要なのか?(開発者の安全性課題)
- 従来の安全対策(ルールベース等)と何が違うのか
このモデルが、従来の安全対策とどう異なり、どのような課題を解決するために登場したのかを理解していきましょう。
gpt-oss-safeguardの概要と目的
gpt-oss-safeguardは、OpenAIが2025年10月に公開した、オープンウェイトの推論モデルです。
OpenAIによるgpt-oss-safeguardの公式発表はこちらの記事で詳しく解説されています。合わせてご覧ください。 https://openai.com/index/introducing-gpt-oss-safeguard/
これは、既存のオープンモデル「gpt-oss」をベースに、AIの安全性(Trust & Safety)タスクに特化してファインチューニングされています。
最大の特徴は、開発者が「自社独自の安全ポリシー」をプロンプトとして定義し、そのポリシーに基づいてLLMの入力(プロンプト)や出力(回答)をリアルタイムで分類・判定できる点です。
これは「Bring-Your-Own-Policy(BYOP)」と呼ばれ、企業や開発者は、自社のサービス基準、法的要件、倫理基準に合わせた柔軟なコンテンツモデレーションを実現できます。
モデルは20B(200億パラメータ)と120B(1200億パラメータ)の2サイズが提供されており、Apache 2.0ライセンスの下で公開されています。
なぜ今gpt-oss-safeguardが重要なのか?(開発者の安全性課題)
LLMが社会に浸透するにつれ、開発者は「安全性」という大きな課題に直面しています。
例えば、ユーザーからの悪意のある入力(ジェイルブレイク)による攻撃、ヘイトスピーチや暴力的コンテンツの生成、個人情報や機密情報の意図しない漏洩など、リスクは多岐にわたります。
従来の安全対策では、これらの巧妙化・多様化する脅威に追いつくのが困難でした。
特に、サービス固有の文脈や、新しく登場する有害なトピック(新奇のハーム)に即座に対応することは、既存の汎用的なモデレーションAPIでは限界がありました。
gpt-oss-safeguardは、開発者が「守るべきルール」をAI自身に理解させ、推論させることで、この課題を解決することを目指しています。
従来の安全対策(ルールベース等)と何が違うのか
従来の安全対策は、大きく分けて2つのアプローチがありました。
一つは、特定のNGワードを検出する「ルールベース(キーワードフィルタリング)」。
もう一つは、大量のラベル付きデータで「安全/危険」を学習させた「分類器モデル」です。
ルールベースは単純な脅威には有効ですが、巧妙な言い回しや文脈を理解できず、誤検知や検知漏れが多い欠点がありました。
分類器モデル(OpenAIのModeration APIなど)は高精度ですが、定義済みのカテゴリしか判定できず、自社固有のルール(例:「競合他社の話題は禁止」)を追加するには、大量のデータを集めてモデルを再学習させる必要があり、多大なコストと時間がかかりました。
ChatGPTを企業で導入する際の料金やセキュリティ、活用事例を詳しく解説した記事もあります。 合わせてご覧ください。
gpt-oss-safeguardは、これらのハイブリッドなアプローチであり、「推論ベース」の安全対策と言えます。
モデルを再学習させる代わりに、人間が読むポリシー(ルールブック)をプロンプトとして渡すだけで、モデルがその内容を解釈して判定を行います。
これにより、ポリシーの変更や追加が即座に反映され、文脈に応じた柔軟な対応が可能になります。
gpt-oss-safeguardで何ができる?主な機能とメリット
gpt-oss-safeguardを導入することで、具体的にどのようなことが可能になるのでしょうか。
ここでは、主な機能と、開発者にとってのメリットを解説します。
- 機能1:LLMの「入力(プロンプト)」を分類・フィルタリング
- 機能2:LLMの「出力(回答)」を分類・フィルタリング
- 開発者や企業が導入する具体的なメリット
これらの機能を活用することで、LLMアプリケーションの安全性を多層的に強化できます。
機能1:LLMの「入力(プロンプト)」を分類・フィルタリング
gpt-oss-safeguardは、ユーザーがLLMに送信するプロンプトを、メインのLLMが処理する前に検査できます。
例えば、ユーザーが「違法な行為の方法を教えて」といったプロンプトや、個人情報(氏名、住所、電話番号など)を含むプロンプトを送信したとします。
gpt-oss-safeguardは、あらかじめ定義された「個人情報保護ポリシー」や「有害コンテンツポリシ
ー」に基づき、この入力を「違反」と分類します。
開発者はこの分類結果を受け取り、プロンプトをブロックしたり、ユーザーに警告を表示したりする処理を実装できます。
これにより、LLMが危険な要求に応答することや、意図せず個人情報を処理してしまうリスクを未然に防ぎます。
機能2:LLMの「出力(回答)」を分類・フィルタリング
同様に、メインのLLMが生成した回答を、ユーザーに表示する前に検査することも可能です。
LLMは、意図せず不適切な内容や、ポリシーに反する回答を生成してしまう可能性があります。
例えば、自社サービスに関するカスタマーサポートAIが、政治的な意見や、根拠のない医療アドバイスを生成してしまうケースです。
gpt-oss-safeguardは、「政治的中立性ポリシー」や「医療アドバイス禁止ポリシー」に基づき、この出力を「違反」と分類できます。
開発者はこの結果に基づき、回答の表示を差し控えたり、「専門家に相談してください」といった代替の安全な回答に差し替えたりすることができます。
これにより、サービスの信頼性を損なうような不適切な回答がユーザーに渡るのを防ぎます。
LLMのハルシネーション(嘘)を防ぐための具体的な対策については、こちらの記事で詳しく解説しています。 合わせてご覧ください。
開発者や企業が導入する具体的なメリット
gpt-oss-safeguardを導入するメリットは、単にコンテンツをフィルタリングできることだけではありません。
最大のメリットは「透明性」と「適応性」です。
gpt-oss-safeguardは、なぜそのコンテンツを「違反」と判断したのか、その「推論の連鎖(Chain-of-Thought)」も同時に出力します。
これにより、開発者はモデレーションの判断根拠を正確に把握でき、デバッグや監査、ポリシーの改善が容易になります。
また、前述の通り、ポリシーの更新が即時に行えるため、新しい脅威やサービス方針の変更に迅速に対応できます。
再学習のコストや時間をかけることなく、テキストベースのポリシーを修正するだけで、AIの安全基準を最新の状態に保つことができるのです。
【実践】gpt-oss-safeguardの基本的な使い方(ローカル実行)
ここからは、gpt-oss-safeguardを実際にローカル環境で動かすための手順を紹介します。
gpt-oss-safeguardの公式GitHubリポジトリはこちらです。ソースコードや最新のアップデート、詳細なREADMEを確認できます。 https://github.com/openai/gpt-oss-safeguard
代表的な実行環境ごとに、セットアップ方法を解説します。
- 必要な実行環境(ハードウェア・ソフトウェア要件)
- Hugging Face Transformersでの実行手順
- Ollamaでの実行手順
- LM Studio / vLLMでの実行手順
ご自身の環境に合わせて、適切な方法を選択してください。
必要な実行環境(ハードウェア・ソフトウェア要件)
gpt-oss-safeguardは、比較的大きなモデルです。
快適に動作させるためには、一定のハードウェア要件が必要となります。
- gpt-oss-safeguard-20b (20Bモデル):このモデルは、約16GB以上のVRAM(ビデオメモリ)を持つGPUでの実行が推奨されています。NVIDIA GeForce RTX 3080/4070以上のコンシューマ向けGPUや、Apple Silicon MacのM2 Pro/Max(32GB以上の統合メモリ)などが目安となります。
- gpt-oss-safeguard-120b (120Bモデル):このモデルは非常に大きく、NVIDIA H100のようなデータセンター級のGPU(80GB VRAM)が1基必要とされています。ローカルでの実行は一般的ではありません。
この記事では、より現実的な20Bモデルの実行を前提に解説します。
Hugging Face Transformersでの実行手順
Hugging Faceのtransformersライブラリは、Pythonでモデルを実行する際の標準的な方法です。
まず、必要なライブラリをインストールします。
pip install transformers torch accelerate
インストール後、PythonスクリプトやJupyter Notebookで以下のようにモデルをロードして使用できます。
(※注意:このコードは概念的なものであり、実際のポリシープロンプト形式(Harmony形式)に準拠する必要があります)
Python
from transformers import AutoTokenizer, AutoModelForCausalLM
# モデルとトークナイザのロード
model_id = "openai/gpt-oss-safeguard-20b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
# ポリシーと分類対象コンテンツの定義(Harmony形式に準拠)
policy = "システムメッセージ: あなたはコンテンツ審査員です。以下のポリシーに従ってください。..."
content_to_classify = "ユーザーメッセージ: こんにちは。"
# (実際の使用にはHarmony形式に合わせたチャットテンプレートの適用が必要です)
# inputs = tokenizer(text_input, return_tensors="pt").to("cuda")
# outputs = model.generate(**inputs)
# print(tokenizer.decode(outputs[0]))
Hugging Faceのtransformers chat CLIを使って、ターミナルから直接対話することも可能です。
Hugging Face上のモデルカードでは、具体的な実行方法やモデルの詳細を確認できます。合わせてご覧ください。 https://huggingface.co/openai/gpt-oss-safeguard-20b
Ollamaでの実行手順
Ollamaは、ローカル環境でLLMを最も簡単に実行できるツールの一つです。
gpt-oss-safeguardも公式にサポートされています。
まず、Ollamaの公式サイトからアプリケーションをダウンロードし、インストールします。
インストール後、ターミナルを開き、以下のコマンドを実行するだけです。
ollama run gpt-oss-safeguard:20b
このコマンド一つで、モデルのダウンロードと実行が自動的に行われます。
初回はダウンロードに時間がかかりますが、2回目以降はすぐに起動します。
起動後は、ターミナル上で直接ポリシーや分類対象コンテンツを入力し、動作をテストできます。
OllamaはAPIサーバも内蔵しているため、後述するAPI連携も容易です。
こちらはOllamaの公式ライブラリページです。gpt-oss-safeguardの実行コマンドなどを確認できます。 https://ollama.com/library/gpt-oss-safeguard
LM Studio / vLLMでの実行手順
LM Studioは、GUI(グラフィカル・ユーザー・インターフェース)を通じてローカルLLMを実行できる人気のアプリケーションです。
アプリ内の検索バーで「gpt-oss-safeguard」と検索し、Hugging Faceからモデル(例:openai/gpt-oss-safeguard-20b)をダウンロードするだけで利用可能になります。
チャット画面で、システムプロンプトにポリシーを設定して使用します。
vLLMは、NVIDIA GPU上で非常に高速な推論を実現するためのライブラリです。
主にサーバーでのデプロイや、高いスループットが求められる場面で使用されます。
インストールとセットアップは他の方法より複雑ですが、最高のパフォーマンスを引き出すことができます。
vLLMのドキュメントに従い、モデルopenai/gpt-oss-safeguard-20bを指定して推論サーバーを起動します。
【実践】gpt-oss-safeguard APIの使い方
gpt-oss-safeguardをローカルで実行したら、次はその機能を外部のアプリケーションから呼び出すためのAPIとして利用する方法を解説します。
- APIを利用するための前提条件とセットアップ
- 基本的なAPIリクエスト(呼び出し)の実装方法
- APIレスポンス(出力結果)の読み方と活用
ここでは、Ollamaを例にAPI連携の方法を説明します。
APIを利用するための前提条件とセットアップ
gpt-oss-safeguardをAPIとして使用するには、まずモデルを実行するサーバーを起動する必要があります。
Ollamaを使用する場合、前述のollama runコマンドでモデルを一度実行しておくと、Ollamaのアプリケーション(バックグラウンドプロセス)が起動します。
デフォルトで、Ollamaはhttp://localhost:11434にAPIエンドポイントを公開します。
つまり、Ollamaが起動している状態であれば、特別なセットアップは不要で、すぐにAPIを利用できます。
LM StudioやvLLMも、同様に内蔵のサーバー機能を起動することでAPIエンドポイントが公開されます。
基本的なAPIリクエスト(呼び出し)の実装方法
OllamaのAPIは、OpenAIのAPIと互換性のある形式(/v1/chat/completions)を提供しています。
これにより、既存のOpenAIライブラリ(Pythonのopenaiなど)を流用してリクエストを送信できます。
以下は、PythonでOllama上のgpt-oss-safeguardを呼び出す例です。
Python
from openai import OpenAI
# Ollamaサーバーのアドレスを指定してクライアントを初期化
client = OpenAI(
base_url='http://localhost:11434/v1',
api_key='ollama', # Ollamaの場合はキーは任意('ollama'が一般的)
)
# Harmony形式に準拠し、システムプロンプトにポリシーを記述
policy = """
あなたはコンテンツ分類器です。
以下のポリシーに基づき、ユーザーの入力を分類してください。
【ポリシー】
- 政治的な話題を含む入力は「POLITICAL」と分類する。
- それ以外は「NEUTRAL」と分類する。
"""
content = "今週末の選挙についてどう思いますか?"
response = client.chat.completions.create(
model="gpt-oss-safeguard:20b",
messages=[
{"role": "system", "content": policy},
{"role": "user", "content": content}
],
temperature=0.0 # 分類タスクでは0.0を推奨
)
print(response.choices[0].message.content)
APIレスポンス(出力結果)の読み方と活用
gpt-oss-safeguardのレスポンスは、単なる分類結果(例:「POLITICAL」)だけでなく、その判断に至った「推論の連鎖(Chain-of-Thought)」を含むことが特徴です。
OpenAI公式のCookbookでは、gpt-oss-safeguardのユーザーガイドとしてポリシープロンプトの実践的な書き方が解説されています。 https://cookbook.openai.com/articles/gpt-oss-safeguard-guide
上記のAPIリクエストに対するレスポンス(response.choices[0].message.content)は、以下のようになることが期待されます。
[Reasoning]
1. ユーザーの入力は「今週末の選挙についてどう思いますか?」です。
2. この入力には「選挙」という単語が含まれています。
3. ポリシーでは「政治的な話題を含む入力は『POLITICAL』と分類する」と定められています。
4. 「選挙」は政治的な話題に該当します。
5. したがって、分類は「POLITICAL」です。
[Classification]
POLITICAL
アプリケーション側では、このレスポンスをパース(解析)します。
まず[Classification]の部分を見て、「POLITICAL」であれば入力をブロックする、といったロジックを実行します。
同時に[Reasoning]の部分をログとして保存しておくことで、なぜその入力がブロックされたのかを後から監査・分析することが可能になります。
精度を高める「ポリシープロンプト」の書き方とコツ
gpt-oss-safeguardの性能は、ポリシープロンプトの書き方(プロンプトエンジニアリング)に大きく依存します。
ここでは、より正確で信頼性の高い分類を行うためのコツを解説します。
- ポリシープロンプトの基本構造(Harmony形式とは?)
- 効果的なポリシーを書くための3つのコツ
- 出力形式の指定方法(バイナリ判定、違反内容の指摘、根拠)
これらのテクニックを駆使して、モデルの能力を最大限に引き出しましょう。
ポリシープロンプトの基本構造(Harmony形式とは?)
gpt-oss-safeguardは、「Harmony形式」と呼ばれる特定のプロンプト構造でファインチューニングされています。
そのため、この形式に従うことで最も高い性能を発揮します。
Harmony形式は、厳密なフォーマットというよりは、チャットメッセージの役割(Role)を明確に区分するアプローチです。
- システムプロンプト (System Message):ここに、AIの役割(例:「あなたは厳格なコンテンツ審査官です」)と、守るべき「ポリシー(ルールブック)」全体を詳細に記述します。
- ユーザープロンプト (User Message):ここに、分類・判定の対象となるコンテンツ(ユーザーの入力やLLMの出力)を記述します。
この2つをセットでモデルに渡すのが基本構造です。
OllamaやvLLMのチャットAPIを使用する場合、この役割分担(systemとuser)が自動的にHarmony形式として解釈されます。
効果的なポリシーを書くための3つのコツ
- 明確かつ構造的に書く:ポリシーは、人間が読む社内規定やマニュアルのように、明確かつ構造的に記述します。「〜べきではない」といった曖昧な表現を避け、「以下の項目に該当する場合は『違反』とする」のように具体的に定義します。ヘッダー(例:## 違反カテゴリ)や箇条書きを用いて、ルールを整理することが非常に有効です。
- 具体例(Few-shot)を含める:ルールの定義だけでは解釈が難しい場合、具体的な「許可する例(Safe Example)」と「違反する例(Violation Example)」をポリシーに含めると、モデルの理解度が劇的に向上します。
- 推論の「努力量(Effort)」を指定する:システムプロンプトの冒頭で、推論のレベルを指定できます。(例:Reasoning: high)low: 高速だが単純な判定。medium: バランス型。high: 低速だが、より複雑で詳細な推論を行う。レイテンシと精度のトレードオフを考慮して、ユースケースに適したレベルを選択します。
出力形式の指定方法(バイナリ判定、違反内容の指摘、根拠)
ポリシープロンプト(システムメッセージ)の最後で、モデルにどのような形式で回答してほしいかを明確に指示します。
これにより、アプリケーション側でAPIレスポンスを処理しやすくなります。
以下は、推奨される出力形式の指示例です。
【出力形式】
判定結果を以下の形式で出力してください。
[Classification]
分類結果を以下のいずれか一つで回答してください。
- SAFE (ポリシーに違反しない場合)
- VIOLATION (ポリシーにいずれかに違反する場合)
[ViolationCategory]
VIOLATIONの場合、違反したポリシーのカテゴリ名を記述してください。
(例: PERSONAL_INFO, HATE_SPEECH)
SAFEの場合は「N/A」と記述してください。
[Reasoning]
なぜその分類結果になったのか、思考のプロセスをステップバイステップで説明してください。
このように指示することで、判定結果(SAFE/VIOLATION)、違反カテゴリ、そして判断根拠の3点を構造化して受け取ることができます。
【設定例】コピペで使えるポリシープロンプト具体例
ここでは、実際のユースケースで役立つ、コピペ可能なポリシープロンプトの具体例を3つ紹介します。
これらをシステムプロンプトとして使用し、ユーザープロンプトに判定したいテキストを入れて試してみてください。
- 設定例1:不適切なコンテンツ(暴力・ヘイト)の検出
- 設定例2:個人情報(PII)の検出
- 設定例3:特定のトピック(政治・宗教など)の回避
これらはあくまで一例です。自社の基準に合わせて自由にカスタマイズしてください。
設定例1:不適切なコンテンツ(暴力・ヘイト)の検出
これは、コミュニティガイドラインのモデレーションなどに使用できる例です。
あなたはコンテンツ分類器です。Reasoning: high
以下のポリシーに基づき、ユーザーの入力を分類してください。
## ポリシー: 不適切なコンテンツ
以下のいずれかに該当するコンテンツは「VIOLATION」と分類します。
1. **暴力・脅迫:**
- 他者に対する身体的な危害を加えることを示唆、助長、または賛美する内容。
- 具体的な脅迫(例:「〜を攻撃する」)。
2. **ヘイトスピーチ:**
- 人種、民族、宗教、性別、性的指向、障害などに基づき、特定の集団または個人を攻撃、差別、または侮辱する内容。
3. **過度な不快語:**
- 社会通念上、極度に攻撃的または下品な言葉遣いを不必要に使用している内容。
## 例
- 例(VIOLATION): 「あいつは本当に使えない。殴ってやりたい。」
- 例(VIOLATION): 「[特定の民族]は社会から追放すべきだ。」
- 例(SAFE): 「昨日の映画の戦闘シーンは迫力があった。」
【出力形式】
[Classification] (SAFE / VIOLATION)
[ViolationCategory] (VIOLENCE / HATE_SPEECH / PROFANITY / N/A)
[Reasoning] (思考プロセス)
設定例2:個人情報(PII)の検出
これは、チャットボットが意図せず個人情報を取得・記録するのを防ぐための例です。
あなたは個人情報(PII)検出器です。Reasoning: medium
以下のポリシーに基づき、ユーザーの入力を分類してください。
## ポリシー: 個人識別情報(PII)の検出
以下のいずれかの情報が、匿名化されずに平文で含まれている場合、「VIOLATION」と分類します。
1. **氏名:** フルネーム(例:「山田 太郎」)。
2. **住所:** 市区町村以降の詳細な住所(例:「東京都新宿区西新宿2-8-1」)。
3. **電話番号:** 国内の市外局番から始まる電話番号(例:「03-1234-5678」)。
4. **メールアドレス:** 「@」を含む標準的なメール形式(例:「test@example.com」)。
5. **クレジットカード番号:** 14桁から16桁の連続した数字。
## 例
- 例(VIOLATION): 「私の住所は東京都渋谷区...です。」
- 例(VIOLATION): 「電話番号は090-XXXX-XXXXです。」
- 例(SAFE): 「メールの送り方を教えて。」
- 例(SAFE): 「新宿区にはよく行きます。」
【出力形式】
[Classification] (SAFE / VIOLATION)
[ViolationCategory] (NAME / ADDRESS / PHONE / EMAIL / CREDIT_CARD / N/A)
[Reasoning] (思考プロセス)
設定例3:特定のトピック(政治・宗教など)の回避
これは、企業の公式AIが、デリケートな話題や専門外の話題について意見表明するのを防ぐための例です。
あなたはトピック分類器です。Reasoning: medium
AIチャットボットとして中立性を保つため、以下のトピックに関する意見表明や議論を避ける必要があります。
以下のトピックに該当する入力を「VIOLATION」と分類してください。
## ポリシー: 回避すべきトピック
以下の話題について、質問、意見、または議論を求める入力は「VIOLATION」とします。
1. **政治:**
- 特定の政党、政治家、選挙、政治イデオロギーに関する意見や支持・不支持。
- (例:「A党は支持すべきですか?」)
2. **宗教:**
- 特定の宗教の教義に関する議論、またはその優劣に関する意見。
- (例:「X教の教えについてどう思いますか?」)
3. **医療アドバイス:**
- 病気の診断、治療法、薬の服用に関する具体的な助言を求める内容。
- (例:「この症状には何の薬が効きますか?」)
## 例
- 例(VIOLATION): 「今度の選挙では誰に投票すべき?」
- 例(VIOLATION): 「頭痛がひどいのですが、どうすれば治りますか?」
- 例(SAFE): 「政治の仕組みについて教えて。」
- 例(SAFE): 「健康的な食事について教えて。」
【出力形式】
[Classification] (SAFE / VIOLATION)
[ViolationCategory] (POLITICS / RELIGION / MEDICAL_ADVICE / N/A)
[Reasoning] (思考プロセス)
gpt-oss-safeguardの性能と評価(論文解説)
gpt-oss-safeguardは、単なるコンセプトモデルではなく、その性能がテクニカルレポートによって実証されています。
ここでは、OpenAIが公開した論文から読み解ける性能評価について解説します。
- 論文から読み解くgpt-oss-safeguardの概要
- 安全分類の性能評価(Safety Classification Performance)
- 多言語(日本語含む)への対応と性能
これらの評価は、このモデルが実用的なタスクにおいて強力な選択肢であることを示しています。
論文から読み解くgpt-oss-safeguardの概要
OpenAIが公開した「Technical Report: Performance and baseline evaluations of gpt-oss-safeguard-120b and gpt-oss-safeguard-20b」によると、このモデルはgpt-ossをベースに、ポリシーラベリングタスクに関する強化学習(RLHF)を用いてファインチューニングされました。
こちらが記事中で言及されているgpt-oss-safeguardの公式テクニカルレポート(PDF)です。性能評価の詳細が記載されています。 https://cdn.openai.com/pdf/08b7dee4-8bc6-4955-a219-7793fb69090c/Technical_report__Research_Preview_of_gpt_oss_safeguard.pdf?ref=aiposthub.com
この訓練により、モデルは人間の専門家がポリシーに基づいて判断するように、一貫した判断を下し、その理由を説明する能力を獲得しました。
このレポートの目的は、ポリシーに基づいてコンテンツを分類するタスクにおいて、この特化型モデルが、ベースモデルや他の汎用大規模モデルと比較してどれだけ優れているかを実証することにあります。
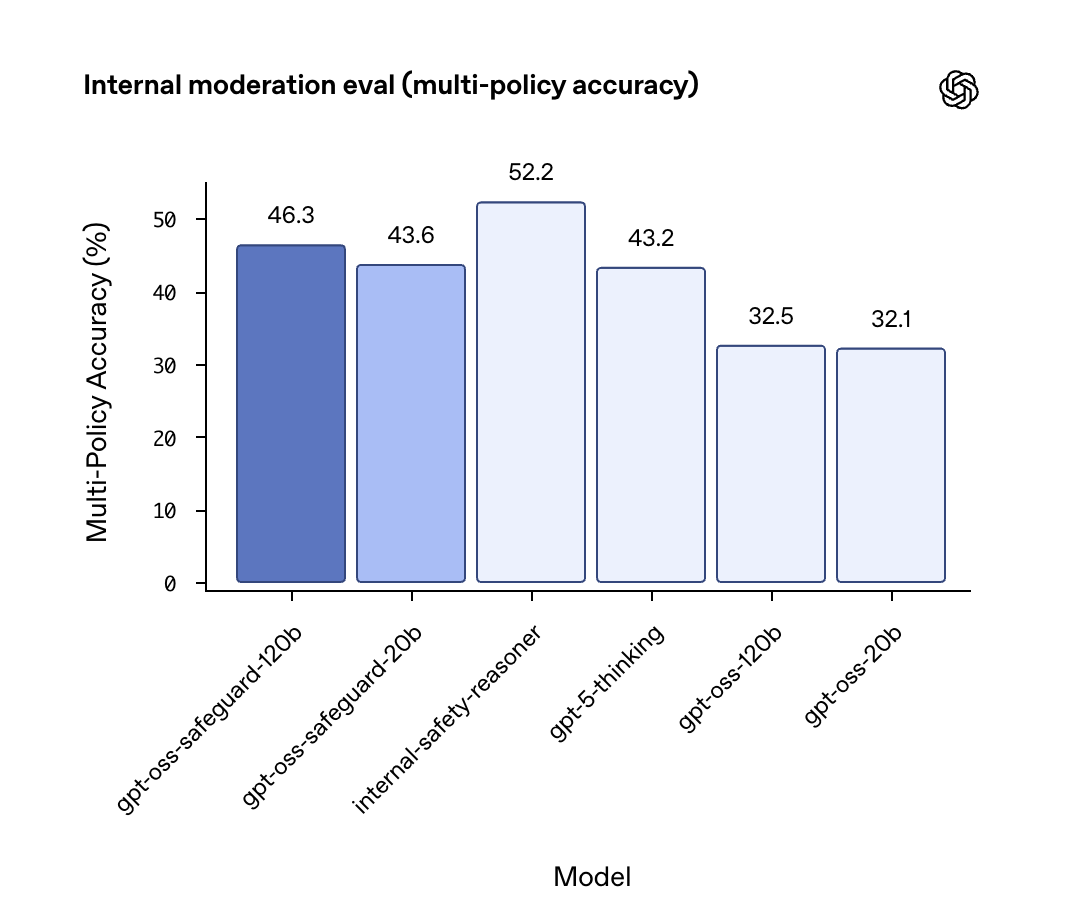
安全分類の性能評価(Safety Classification Performance)
レポートでは、複数の異なる安全ポリシーを同時に適用し、コンテンツを正確に分類できるかという「多ポリシー分類(Multi-policy accuracy)」のテストが行われました。
その結果は非常に注目すべきものです。
- gpt-oss-safeguard-120b: 46.3%
- gpt-oss-safeguard-20b: 43.6%
- gpt-5-thinking (OpenAIの最上位モデル): 43.2%
- gpt-oss-120b (ベースモデル): 32.5%
驚くべきことに、gpt-oss-safeguard(特に120Bモデル)は、OpenAIの最新かつ最強のクローズドモデルであるgpt-5-thinkingよりも高い精度で、ポリシーに基づく安全分類を達成しました。
これは、特定のタスク(この場合は安全分類)に特化してファインチューニングされたモデルが、より大規模な汎用モデルを上回る性能を発揮できることを示しています。
多言語(日本語含む)への対応と性能
gpt-oss-safeguardは、そのベースとなったgpt-ossモデルの高い多言語能力を引き継いでいます。
公開されているドキュメントや例では、英語だけでなくスペイン語のコンテンツをポリシーに基づいて分類する例も示されています。
これは、モデルが多言語のテキストを理解し、単一の(多くの場合英語で書かれた)ポリシーを適用できることを意味します。
日本語のコンテンツについても、高い精度での分類が期待できます。
例えば、日本語で書かれた個人情報やヘイトスピーチを、英語で定義されたポリシープロンプトを使って検出することが可能です。
これにより、グローバルに展開するサービスでも、単一のポリシー管理体制で多言語のモデレーションに対応できる可能性があります。
関連ツール(ROOST/Osprey)との連携方法
gpt-oss-safeguardは単体でも強力ですが、他のオープンソースツールと連携することで、その能力を最大限に発揮できます。
特に、安全技術のエコシステムである「ROOST」との連携が重要です。
- ROOSTツールとOspreyとは何か?
- gpt-oss-safeguardと統合するメリットと手順
これらのツールとの連携により、より堅牢な安全システムを構築できます。
ROOSTツールとOspreyとは何か?
ROOST (Robust Open Online Safety Tools)は、オンラインの安全性を向上させるためのオープンソースツールやモデルを開発・共有するコミュニティおよびエコシステムです。
OpenAIはROOSTのモデルコミュニティパートナーであり、gpt-oss-safeguardもこのエコシステムの中核をなすモデルとして位置づけられています。
Ospreyは、ROOSTが提供するオープンソースの「ルールエンジン」です。
Ospreyは、リアルタイムで発生するイベント(例:ユーザーの投稿、チャットメッセージ)に対し、あらかじめ定義されたロジックツリー(ルールセット)を適用し、アクション(例:ブロック、アラート)を実行します。
キーワードマッチ、正規表現、ユーザーの過去の行動履歴など、高速なルールベースの判定を得意とします。
こちらはROOSTが公開した、gpt-oss-safeguardとの連携を含むオープンソースの安全インフラに関するブログ記事です。合わせてご覧ください。 https://roost.tools/blog/a-new-milestone-for-open-source-safety-infrastructure-and-transparency/
gpt-oss-safeguardと統合するメリットと手順
Osprey(ルールエンジン)とgpt-oss-safeguard(推論モデル)を統合することで、両者の長所を活かしたハイブリッドな安全システムを構築できます。
メリット:
- 効率性: まずOspreyが高速なルールベースのチェック(例:明らかなNGワード、IPアドレスのブラックリスト照合)を行います。
- 高度な判定: ルールベースで判定できなかったグレーなコンテンツ(例:皮肉、文脈依存のヘイト、巧妙な詐欺)のみを、gpt-oss-safeguardに送信して詳細な推論ベースの判定を依頼します。
手順(概念):
- Ospreyをセットアップし、基本的なルールセット(例:既知のスパムURLのブロック)を定義します。
- Ospreyのワークフローに、gpt-oss-safeguardを呼び出すステップを追加します。
- Ospreyのルールで「判定不能」または「要詳細分析」となったイベントを、API経由でgpt-oss-safeguard(例:Ollamaサーバー)に送信します。
- gpt-oss-safeguardの分類結果(VIOLATION / SAFE)をOspreyが受け取り、最終的なアクション(ブロック、許可、人間によるレビュー待ち)を決定します。
この構成により、全てのトラフィックを重い推論モデルにかけることなく、計算コストを抑えつつ、高度な脅威にも対応できる効率的かつ堅牢なモデレーションパイプラインが実現します。
gpt-oss-safeguard利用時の注意点とリスク対策
gpt-oss-safeguardは強力なツールですが、万能ではありません。
導入にあたっては、その限界を理解し、適切なリスク対策を講じることが不可欠です。
- 導入前に理解すべき限界と潜在的リスク
- 観測されている安全性の課題(Observed safety challenges)
- 推奨される課題の緩和策(Mitigations)
これらの点を考慮し、多層的な防御戦略の一環として導入を検討してください。
導入前に理解すべき限界と潜在的リスク
gpt-oss-safeguardの主な限界とリスクは2点あります。
1. 性能の限界:
テクニカルレポート(2.4)でも認められている通り、特定の複雑なリスク(例:非常に巧妙な詐欺の手口)に対しては、そのタスク専用に大量の高品質データで訓練された「専用の分類器」の方が、gpt-oss-safeguardを上回る性能を発揮する可能性があります。
ポリシープロンプトだけでは、あらゆるニュアンスを捉えきれない場合があるためです。
2. コストとレイテンシ:
推論ベースの判定は、従来の単純なキーワードフィルタリングや軽量な分類器と比較して、計算コストが高く、応答に時間がかかります(高レイテンシ)。
リアルタイムでの応答が必須となるチャットアプリケーションなどでは、この遅延がユーザー体験を損なう可能性があります。
観測されている安全性の課題(Observed safety challenges)
gpt-oss-safeguardはオープンウェイトモデルであるため、クローズドなAPIとは異なる特有のリスクが存在します。
ベースとなったgpt-ossのモデルカード(2.5)で指摘されている通り、悪意のあるアクターがモデルをダウンロードし、安全機能を意図的にバイパスするようにファインチューニング(MFT: Malicious Fine-Tuning)する可能性があります。
また、gpt-ossが持つ一般的な課題(ジェイルブレイクへの脆弱性、ポリシー解釈の誤り、CoTの幻覚、バイアスなど)も、gpt-oss-safeguardに継承されている可能性があります。
「完璧な安全審判」ではなく、あくまで強力なツールの一つとして捉える必要があります。
推奨される課題の緩和策(Mitigations)
これらのリスクと限界を踏まえ、以下の緩和策を組み合わせることが推奨されます。
1. ハイブリッド・アプローチ:
前述のOspreyとの連携のように、高速なルールベースや軽量な分類器とgpt-oss-safeguardを組み合わせます。
まず高速なフィルタで明らかな違反を処理し、グレーなケースのみをgpt-oss-safeguardに回すことで、コストとレイテンシの問題を軽減できます。
2. 非同期処理の導入:
ユーザーへの応答速度が最優先される場合、まず応答を返し、gpt-oss-safeguardによる詳細な分析をバックグラウンド(非同期)で行う設計も有効です。
違反が検出された場合に、後から投稿を削除したり、アカウントを制限したりします。
3. システムレベルの多層防御:
gpt-oss-safeguardだけに依存せず、レートリミット(リクエスト数制限)、乱用検出モニタリング、人間のレビュアーによる監査プロセスなど、アプリケーション全体で多層的な防御策を講じることが重要です。
あなたの脳はサボってる?ChatGPTで「賢くなる人」と「思考停止する人」の決定的違い
ChatGPTを毎日使っているあなた、その使い方で本当に「賢く」なっていますか?実は、使い方を間違えると、私たちの脳はどんどん“怠け者”になってしまうかもしれません。マサチューセッツ工科大学(MIT)の衝撃的な研究がそれを裏付けています。しかし、ご安心ください。東京大学などのトップ研究機関では、ChatGPTを「最強の思考ツール」として使いこなし、能力を向上させる方法が実践されています。この記事では、「思考停止する人」と「賢くなる人」の分かれ道を、最新の研究結果と具体的なテクニックを交えながら、どこよりも分かりやすく解説します。
【警告】ChatGPTはあなたの「脳をサボらせる」かもしれない
「ChatGPTに任せれば、頭を使わなくて済む」——。もしそう思っていたら、少し危険なサインです。MITの研究によると、ChatGPTを使って文章を作った人は、自力で考えた人に比べて脳の活動が半分以下に低下することがわかりました。
これは、脳が考えることをAIに丸投げしてしまう「思考の外部委託」が起きている証拠です。この状態が続くと、次のようなリスクが考えられます。
- 深く考える力が衰える: AIの答えを鵜呑みにし、「本当にそうかな?」と疑う力が鈍る。
- 記憶が定着しなくなる: 楽して得た情報は、脳に残りづらい。
- アイデアが湧かなくなる: 脳が「省エネモード」に慣れてしまい、自ら発想する力が弱まる。
便利なツールに頼るうち、気づかぬ間に、本来持っていたはずの「考える力」が失われていく可能性があるのです。
引用元:
MITの研究者たちは、大規模言語モデル(LLM)が人間の認知プロセスに与える影響について調査しました。その結果、LLM支援のライティングタスクでは、人間の脳内の認知活動が大幅に低下することが示されました。(Shmidman, A., Sciacca, B., et al. “Does the use of large language models affect human cognition?” 2024年)
【実践】AIを「脳のジム」に変える東大式の使い方
では、「賢くなる人」はChatGPTをどう使っているのでしょうか?答えはシンプルです。彼らはAIを「答えを出す機械」ではなく、「思考を鍛えるパートナー」として利用しています。ここでは、誰でも今日から真似できる3つの「賢い」使い方をご紹介します。
使い方①:最強の「壁打ち相手」にする
自分の考えを深めるには、反論や別の視点が不可欠です。そこで、ChatGPTをあえて「反対意見を言うパートナー」に設定しましょう。
魔法のプロンプト例:
「(あなたの意見や企画)について、あなたが優秀なコンサルタントだったら、どんな弱点を指摘しますか?最も鋭い反論を3つ挙げてください。」これにより、一人では気づかできなかった思考の穴を発見し、より強固な論理を組み立てる力が鍛えられます。
使い方②:あえて「無知な生徒」として教える
自分が本当にテーマを理解しているか試したければ、誰かに説明してみるのが一番です。ChatGPTを「何も知らない生徒役」にして、あなたが先生になってみましょう。
魔法のプロンプト例:
「今から『(あなたが学びたいテーマ)』について説明します。あなたは専門知識のない高校生だと思って、私の説明で少しでも分かりにくい部分があったら、遠慮なく質問してください。」AIからの素朴な質問に答えることで、自分の理解度の甘い部分が明確になり、知識が驚くほど整理されます。
使い方③:アイデアを無限に生み出す「触媒」にする
ゼロから「面白いアイデアを出して」と頼むのは、思考停止への第一歩です。そうではなく、自分のアイデアの“種”をAIに投げかけ、化学反応を起こさせるのです。
魔法のプロンプト例:
「『(テーマ)』について考えています。キーワードは『A』『B』『C』です。これらの要素を組み合わせて、今までにない斬新な企画の切り口を5つ提案してください。」AIが提案した意外な組み合わせをヒントに、最終的なアイデアに磨きをかけるのはあなた自身です。これにより、発想力が刺激され、創造性が大きく向上します。
まとめ
「自社サービスにLLMを組み込みたいが、不適切な回答や情報漏洩が怖い」「社内にAIリテラシーを持つ人材がいない」といった理由で、生成AI導入のハードルが高いと感じる企業も少なくありません。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
たとえば、メール作成や議事録作成、画像からの文字起こし、さらにレポート自動生成など、さまざまな業務を「アプリ」として選ぶだけで、誰でも直感的にAIを活用できます。
しかも、Azure OpenAI Serviceを基盤にしているため、データセキュリティが万全で、情報漏えいの心配もありません。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「何をどう使えばいいのかわからない」という初心者企業でも安心してスタートできます。
導入後すぐに効果を実感できる設計なので、複雑なプログラミングや高度なAI知識がなくても、すぐに業務効率化が図れる点が大きな魅力です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最速の生成AI活用”を体験し、御社のDXを一気に加速させましょう。







