

「伝票の数字をOCRで読み取らせても、誤認識ばかりで修正作業が終わらない」
「手書きの数字や桁数が多いと、どうしても精度が落ちてしまう」
業務効率化のためにOCRを導入したはずが、逆に確認作業に追われているという担当者様も多いのではないでしょうか。
本記事では、OCRにおける「数字」読み取りの精度を劇的に向上させるための具体的な設定テクニックや、読み取りやすい帳票設計のポイントについて解説しました。
長年OCRシステムの導入支援を行い、現場の課題解決に携わってきた弊社が実践しているノウハウのみを凝縮してご紹介します。
数字データの入力業務を自動化し、本当の意味での業務効率化を実現するために、ぜひ最後までご覧ください。
業務効率化とDX推進の全体像については、こちらの記事でも詳しく解説しています。ぜひ併せてご覧ください。
なぜOCRで「数字」の読み取りは難しいのか?
まずは、なぜOCRにおいて文字よりも数字の読み取りでエラーが起きやすいのか、その根本的な原因を理解しましょう。
主な理由は以下の3点です。
- 似た形状の文字や記号との区別がつきにくい
- デジタル特有のフォントや表示形式の影響
- 手書き文字の自由度の高さによる認識阻害
これらの原因を知ることで、適切な対策を打つことができます。
それでは、1つずつ順に解説します。
アルファベットや記号との混同(0とO、1とIなど)
OCRソフトにとって最も判断が難しいのが、形状が酷似している英数字の識別です。
特に代表的なのが、数字の「0(ゼロ)」とアルファベットの「O(オー)」、数字の「1(イチ)」とアルファベットの「I(アイ)」や小文字の「l(エル)」です。
人間であれば前後の文脈から「ここは金額欄だから数字のはずだ」と無意識に判断できますが、従来のOCRエンジンは一文字ごとの形状で判断する傾向があります。
そのため、フォントによっては全く同じ形に見えてしまい、誤変換が頻発します。
また、数字の「8」とアルファベットの「B」、数字の「5」とアルファベットの「S」、数字の「2」と「Z」なども誤読の定番です。
型番や品番のように、英字と数字がランダムに混在している文字列の場合、この問題はさらに深刻化します。
単純な形状の一致だけでなく、印刷のかすれや汚れが付着することで、「3」が「8」に見えたり、「6」が「8」に見えたりすることも珍しくありません。
このように、数字の読み取りはわずかな形状の差異を見極める必要があり、非常に繊細な処理が求められるのです。
文字の形状類似による誤認識の実態については、こちらの研究レポートで詳しく分析されています。 https://oasis.library.unlv.edu/cgi/viewcontent.cgi?article=2895&context=rtds
7セグメント(デジタル表示)やドット文字の特殊性
工場や倉庫などの現場でよく利用される、デジタルメーターや計測器の数値読み取りにおいても課題があります。
これらは「7セグメント」と呼ばれる、カクカクとした独特のデジタルフォントで表示されていることが一般的です。
7セグメントディスプレイは、7つの棒状のライトの組み合わせで数字を表現します。
この形式は、一般的な明朝体やゴシック体のような連続した線で描かれるフォントとは形状のロジックが大きく異なります。
たとえば、数字のつながり部分(セグメント間の隙間)をOCRが「文字の切れ目」や「ノイズ」として認識してしまうことがあります。
また、ドット(点)の集合で文字を表現するドットインパクトプリンターの文字も同様に、点と点の間が繋がっていないため、OCRが一つの文字として認識できずにバラバラのノイズとして処理してしまうケースが多いのです。
さらに、液晶画面自体に光の反射(映り込み)があったり、バックライトの輝度によって文字が白飛びしたりすることも、認識率を下げる大きな要因となります。
一般的な書類用のOCRエンジンでは、こうした特殊なフォントや環境に対応していないことが多く、専用のチューニングが必要になる場合がほとんどです。
深層学習を用いた7セグメントやドット文字の最新認識技術については、以下の論文で高い精度が報告されています。 https://www.itm-conferences.org/articles/itmconf/pdf/2024/06/itmconf_amict2023_01007.pdf
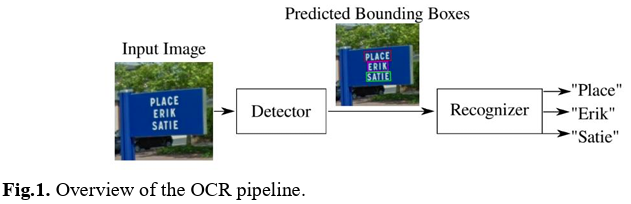
手書き数字特有の「くずし」や「枠はみ出し」による誤認識
手書き文字の読み取り、いわゆる手書きOCRにおいては、書き手の癖が最大の障壁となります。
丁寧に書かれた文字であれば認識率は高いですが、業務の現場で急いで書かれた数字は、崩れていたり、傾いていたりと千差万別です。
例えば、「7」の書き始めに縦線が入っていないと「1」と誤認されたり、「9」の丸が閉じていないと「7」や「4」に見えたりすることがあります。
また、記入枠が設けられている帳票であっても、勢い余って隣の枠に線がはみ出してしまうと、隣の数字の一部として誤認識され、桁数がずれる原因になります。
訂正印や二重線による修正も、OCRにとってはノイズとなります。
人間なら訂正後の数字だけを読み取ることができますが、OCRは訂正線自体を「1」や「ー(マイナス)」と認識してしまうことがあるのです。
このように、手書き数字は活字に比べて情報の揺らぎが非常に大きく、ルールベースの従来型OCRでは対応しきれないケースが多々あります。
そのため、手書き帳票を扱う場合は、後述するAI-OCRのような高度な認識技術が必要不可欠となります。
数字認識の精度を劇的に高める設定とテクニック
ここからは、既存のOCRソフトの設定や運用を少し工夫するだけで、数字の認識率を飛躍的に高めるテクニックを紹介します。
- 読み取る文字の種類を制限する
- 桁数やルールで正誤判定を行う
- 読み取り範囲を正確に指定する
- 画像自体をきれいに加工する
これらの設定を行うことで、OCRエンジンの迷いを減らし、正答率を上げることが可能です。
それでは順に解説します。
読み取り文字種を「数字のみ」に限定する
最も効果的かつ即効性のある対策は、読み取りフィールドに対して「ここは数字しか入らない」という定義を行うことです。
多くのOCRソフトには、読み取りエリアごとに「属性」や「文字種」を指定する機能が備わっています。
例えば、金額欄や電話番号欄の読み取り設定において、認識対象文字を「数字(0-9)」と一部の「記号(¥, -, .)」のみに制限します。
こうすることで、OCRエンジンは最初からアルファベットや漢字を候補から除外して解析を行います。
もし「0」か「O」か判別がつかない形状の文字があったとしても、辞書が「数字のみ」に限定されていれば、迷わず「0」として出力してくれます。
これにより、先ほど挙げたような「O」と「0」、「I」と「1」といった誤認識を強制的に防ぐことができるのです。
品番などで英字が含まれる場合でも、「英字のみ」のエリアと「数字のみ」のエリアを細かく分けて設定することで、同様の効果が得られます。
不要な選択肢を減らしてあげることは、AIやプログラムにとって最大の支援となります。
桁数指定やチェックデジットを活用してエラーを検知する
読み取った結果が正しいかどうかを、論理的に検証する設定も有効です。
郵便番号なら「7桁」、電話番号なら「10桁または11桁」といったように、あらかじめ決まっている桁数を設定しておきます。
もしノイズなどを誤って文字として認識し、桁数が増減してしまった場合、システム側で「エラー(要確認)」としてアラートを出すことができます。
これにより、目視チェックの対象を「エラーが出たものだけ」に絞り込めるため、作業効率が向上します。
また、バーコード下の数字や会員番号などには、入力ミスを防ぐための「チェックデジット」という仕組みが組み込まれていることがあります。
これは、数字の列に特定の計算式を当てはめると、最後の1桁が算出されるというロジックです。
高機能なOCRソフトであれば、このチェックデジット計算機能を備えているものがあります。
読み取った数字に対して自動で計算を行い、論理的に矛盾があれば誤認識として弾くことができるため、データの信頼性をほぼ100%近くまで高めることが可能になります。
読み取り範囲(座標)をピンポイントで指定する
OCRが誤認識を起こす原因の一つに、読み取りたくない余計な情報まで拾ってしまっているケースがあります。
例えば、金額欄の隣にある「円」という文字や、罫線、隣の項目の文字などが範囲に含まれている場合です。
これを防ぐためには、読み取り範囲(ROI:Region of Interest)の設定をできる限りタイトに、ピンポイントで行うことが重要です。
文字の上下左右に余白を持たせすぎると、そこにゴミや影が入った時に誤読の原因になります。
特に、スキャン時のズレを考慮して範囲を広めに取っている場合は注意が必要です。
最近のOCRソフトには、多少の位置ズレを自動補正する機能がついているものが多いので、それを活用しつつ、定義枠自体は数字ギリギリまで絞るのがコツです。
また、桁数が変動する項目(1桁の場合もあれば7桁の場合もある金額欄など)の場合は、右寄せや左寄せといった文字の配置ルールに合わせて、基準点を設定することも大切です。
座標定義を丁寧に行うだけで、読み取り精度は大きく変わります。なお、現在は座標設定が不要な「定義レス(非定型)」対応の最新AI-OCRも普及しているため、設定の手間を省きたい場合はそちらの導入も検討しましょう。
画像の前処理(二値化・ノイズ除去)で数字をくっきりさせる
OCRにかける前の「画像そのもの」の品質を上げることも、テクニックの一つです。
スキャンした画像やカメラで撮影した画像には、背景の模様、紙の裏写り、照明の影など、OCRにとって邪魔なノイズがたくさん含まれています。
これらを取り除くために、画像処理機能(プリプロセス)を活用します。
代表的な処理が「二値化」です。
これは、画像をグレーやカラーではなく、完全に「白」と「黒」の2色だけに変換する処理です。
中途半端な色の濃淡を飛ばすことで、文字の輪郭をくっきりと浮かび上がらせることができます。
また、「ドロップアウトカラー」機能を使って、帳票の枠線(赤や青など)を消し去り、文字(黒)だけを残す処理も有効です。
さらに、傾き補正やノイズ除去フィルターを組み合わせることで、OCRエンジンが解釈しやすいクリーンな画像データを作成します。
最近のOCR製品には、これらの前処理を自動で最適化してくれる機能も搭載されていますが、手動で調整できる場合は、コントラストを強めにするなどの調整を試してみると良いでしょう。
OCR精度における二値化や前処理の影響については、以下の実験結果も参考になります。 https://mirror.dlib.org/dlib/march09/powell/03powell.html
数字を読みやすくする「帳票レイアウト」作成のポイント
OCRの精度を上げるには、ソフト側の設定だけでなく、読み取られる側である「帳票のデザイン」を最適化することも非常に重要です。
- 文字同士の間隔とガイド枠の設置
- OCRに干渉しない色の選定
- OCRに適したフォントの使用
これから帳票を新しく作成したり、改訂したりできる場合には、ぜひ以下のポイントを取り入れてみてください。
順に解説します。
数字同士の間隔を空け、記入枠(ガイド)を設ける
手書き帳票において、数字が連続して書かれていると、OCRはどこで文字が区切れているのか判断できなくなります。
「1」と「2」が接触してしまうと、「12」ではなく「H」のような別の文字として認識される恐れがあります。
これを防ぐためには、1文字ごとに記入枠(マス目)を設けるのが鉄則です。
また、枠と枠の間には十分なスペースを空けるようにデザインします。
記入者が無意識に枠内に文字を収めようとする心理的効果(ナッジ)を利用することで、文字同士の接触や重なりを防ぐことができます。
フリーハンドで書く欄であっても、下部に小さな目盛り(ティックマーク)を入れたり、薄いガイド線を引いたりして、文字を書く位置と大きさをある程度指定してあげることが有効です。
文字の間隔が一定であれば、OCRエンジンは文字の切り出し(セグメンテーション)を正確に行えるようになり、認識率が向上します。
背景色や罫線を消える色(ドロップアウトカラー)にする
前述の画像処理テクニックでも触れましたが、OCRにとって罫線や枠線は、文字と重なると誤認識の原因になる厄介な存在です。
特に記入者が枠線に重ねて数字を書いてしまった場合、線と数字が一体化して読み取れなくなってしまいます。
この問題を根本から解決するのが「ドロップアウトカラー」に対応した帳票作成です。
一般的な業務スキャナは、特定の波長の色(赤、緑、青などのドロップアウトカラー)をスキャン時に自動的に消去する機能を持っています。
そのため、記入枠や罫線、説明書きなどを、スキャナで消える色(例えば薄い赤色や緑色)で印刷しておきます。
そして記入者には、スキャナで残る色(黒や濃い青)のペンで記入してもらいます。
そうすると、スキャンされた画像データには、邪魔な枠線は一切なく、手書きされた数字だけが空中に浮いているような状態で保存されます。
これにより、枠へのはみ出しや接触といった問題を気にする必要がなくなり、OCRの認識精度は劇的に安定します。
認識しやすい推奨フォントを使用する
活字帳票(プリンタで印刷された文字)を読み取る場合、使用するフォント選びも重要です。
デザイン性を重視したフォントや、線が細すぎるフォント、文字同士の間隔が極端に狭いフォントはOCRには不向きです。
一般的に、OCRに適しているとされるのは「OCR-B」フォントのような、OCR読み取り専用に開発されたフォントです。
これは、数字やアルファベットの形状が明確に区別できるように設計されており、パスポートや公共料金の払込票などでも採用されています。
専用フォントが使えない場合でも、「Arial」や「メイリオ」、「MSゴシック」などのサンセリフ体(線の端に飾りのないフォント)で、太さが一定のものは比較的認識精度が高い傾向にあります。
逆に、明朝体のような線の強弱が激しいフォントや、イタリック体(斜体)は避けたほうが無難です。
また、文字サイズも重要です。小さすぎると潰れてしまい、大きすぎても読み取り範囲からはみ出すリスクがあるため、10ポイント〜12ポイント程度のサイズが推奨されます。
従来型OCRとAI-OCR、数字読み取りに強いのはどっち?
OCR導入を検討する際、従来のOCR製品にするか、最新のAI-OCRにするかで迷う方も多いでしょう。
結論から言うと、読み取る対象によって適したツールは異なります。
- 定型的な活字なら従来型でも十分
- 手書きや非定型ならAI-OCRが必須
- 特殊なメーターなどは専用機能が必要
それぞれの特徴と、数字読み取りにおける優位性について解説します。
印字された活字(活字OCR)なら従来型でも対応可能
パソコンで作成し、プリンタで印刷された請求書や納品書などの「活字」のみを読み取るのであれば、従来のOCRソフトでも十分高い精度が出せることが多いです。
従来型OCRは、あらかじめ登録されたフォントパターンとのマッチングを行うことで文字を認識します。
フォーマットが決まっていて、文字のかすれや汚れが少ないきれいな書類であれば、99%以上の精度で数字を読み取ることも可能です。
AI-OCRに比べて導入コストやランニングコストが安価な場合が多いため、用途が限定されているのであれば、コストパフォーマンスの良い選択肢となります。
特に、前述した「OCR-Bフォント」などが使われている帳票であれば、あえて高価なAI-OCRを導入しなくとも、従来型で完璧に近い読み取りができるでしょう。
手書き数字や非定型帳票ならAI-OCRが圧倒的に有利
一方で、手書きの申込書やアンケート、あるいは取引先ごとにレイアウトが異なる請求書などを扱う場合は、AI-OCRの独壇場です。
AI-OCRは、ディープラーニング(深層学習)を用いて膨大なパターンの手書き文字を学習しています。
そのため、崩れた文字、薄い文字、訂正印がある文字など、人間でも判読に迷うような数字であっても、前後の文脈や特徴量から推測して正しく読み取ることができます。
特に2025年現在は、生成AI(LLM)技術を搭載したOCRが登場し、文字の認識だけでなく文脈理解による推論能力が飛躍的に強化されています。
例えば、日付欄であれば「202X年」の可能性が高い、金額欄であれば桁区切りがあるはずだ、といった情報を総合的に判断するため、単なる形状マッチングを超えた認識が可能です。
手書き業務の自動化を目指すなら、迷わずAI-OCRを選択すべきです。
AI-OCRと従来型OCRの具体的な精度比較ベンチマークについては、こちらの記事で詳しく解説されています。 https://sparkco.ai/blog/ocr-accuracy-comparison-2025-benchmark-analysis
メーターなどの7セグメント認識に特化した機能の有無
工場のアナログメーターやデジタルパネルの数値を読み取る場合、一般的な文書用OCR(AI-OCR含む)ではうまく読み取れないことがあります。
文書用のOCRは「紙に書かれた文字」を学習しているため、液晶画面の光沢や、ドットで構成された数字を「文字」として認識しないことがあるからです。
このような用途には、現場の画像認識に特化した専用のAI-OCRソリューションが存在します。
これらは7セグメント表示やドット文字、回転式メーターの針の位置などを専門に学習させています。
もし用途が「現場の数値データの自動取得」であるならば、汎用的なクラウドAI-OCRサービスではなく、エッジAIや専用検針アプリのような特化型ツールを選ぶのが正解です。
このように、数字と一口に言っても「何に表示されている数字か」によって、最強のツールは変わってきます。
OCRによる数字データ化の具体的な活用事例
最後に、OCRを活用して数字データの入力を自動化している具体的な成功事例をいくつか紹介します。
自社の業務に当てはまるものがないか、イメージしながらご覧ください。
- 経理業務での請求書処理
- インフラ・設備点検の自動化
- 製造現場での検品作業
- 物流倉庫での棚卸し
これらの現場では、OCR導入によって劇的な工数削減が実現されています。
順に解説します。
請求書や伝票の「金額・日付」入力の完全自動化
最も導入が進んでいるのが、経理部門における請求書処理です。
取引先から送られてくる請求書の「合計金額」「請求日」「登録番号」などをAI-OCRで読み取り、会計システムや全銀協フォーマットの振込データに自動変換します。
従来は担当者が一枚ずつ目視で入力し、さらに別の担当者がダブルチェックを行っていましたが、OCR導入後は「AIが読み取ったデータを確認するだけ」の作業に変わります。
特にインボイス制度の開始以降、登録番号の照合など数字の確認作業が増大しましたが、OCRとRPA(自動化ロボット)を組み合わせることで、これらの照合業務まで無人化することに成功している企業も増えています。
OCR導入による具体的な人員削減や処理時間短縮の事例については、以下のケーススタディをご覧ください。 https://static1.abbyy.com/abbyycommedia/6104/2007e_cs_flexicapture_trendset_usa.pdf
メーターや計測器の数値を自動検針して記録
ガス、水道、電気などのインフラ業界や、大規模な工場を持つ製造業では、点検員が日々メーターを目視して数値を手帳に記録していました。
この業務にスマホやタブレットで使えるメーター読み取りOCRアプリを導入する事例が増えています。
点検員はメーターにカメラをかざすだけで、瞬時に数値がデジタルデータとして記録されます。
読み間違いや書き間違いといったヒューマンエラーがゼロになるだけでなく、データがリアルタイムでサーバーに送信されるため、報告書作成の手間もなくなります。
暗所や高所にある読み取りにくいメーターでも、画像補正機能により正確に記録できるため、安全性の向上にも寄与しています。
電力公社における大規模なOCR検針導入プロジェクトとその成果については、こちらの論文で紹介されています。 https://www.mdpi.com/2673-4591/20/1/25
製造現場における製品番号(シリアル)の照合・ポカよけ
製造ラインや出荷場において、製品に刻印されたシリアルナンバーやロット番号をOCRで読み取り、生産管理システムと照合する活用法です。
例えば、部品の組み付け時に、正しい部品かどうかの型番チェックをハンディタイプのOCRで行います。
目視確認ではどうしても見逃し(ポカ)が発生してしまいますが、OCRであれば「読み取った番号が指示書の番号と一致しているか」をシステムが瞬時に判定し、間違っていればアラートを鳴らすことができます。
これにより、誤出荷や不良品の流出を未然に防ぐ品質管理の仕組みとして定着しています。
ハンディターミナルを活用した在庫数の読み取り
物流倉庫での棚卸し作業においても、OCRは活躍しています。
従来はバーコードスキャンが主流でしたが、バーコードがない商品や、段ボールに直接数字が書かれているケースでは手入力が必要でした。
ここにOCR機能を搭載したハンディターミナルやスマートフォンを導入することで、段ボールに印字された「入数」や「賞味期限」の数字を直接読み取ることが可能になります。
特に賞味期限(日付数字)の管理は食品業界において重要ですが、手入力によるミスが許されない領域であるため、OCRによる正確なデータ化が高い効果を発揮しています。
OCRで数字を扱う際によくある質問
OCR導入にあたって、現場担当者からよく寄せられる質問とその回答をまとめました。
- 手書き認識の実力
- 記号を含んだ数値の扱い
これらの疑問を解消しておきましょう。
手書き数字の認識率は実用レベルですか?
結論から言うと、最新のAI-OCRであれば実用レベルに達しています。
一般的に、AI-OCRの手書き数字認識率は96%〜99%程度と言われています。
もちろん、人間でも読めないようなあまりに乱雑な文字は認識できませんが、丁寧な文字であればほぼ正確に読み取ります。
ただし、「100%ではない」という点は理解しておく必要があります。
業務フローには必ず「人間による最終確認」のプロセスを組み込むか、生成AIによる論理チェックや修正提案機能を併用することで、実業務に耐えうる信頼性を担保するのが現在の一般的な運用方法です。
手書き数字認識における高精度モデルの競技結果(ICDAR)については、以下の資料が参考になります。 https://cvl.tuwien.ac.at/wp-content/uploads/2014/12/hdrc-icdar13.pdf
小数点やカンマ(桁区切り)も正確に認識できますか?
はい、認識可能ですが、設定には注意が必要です。
OCRにとって「.(ピリオド)」と「,(カンマ)」は非常に小さく、ゴミやノイズと区別がつきにくい要素です。
また、手書きの場合は点の位置が曖昧だったり、薄かったりすることがあります。
精度を上げるためには、「この項目は金額なので3桁ごとにカンマが入る」「この項目は小数点以下2桁まである」といったフォーマット指定(マスク処理)を行うことが有効です。
また、AI-OCRの中には、文脈からカンマとピリオドを自動で補正して判断する機能を持つものもあります。
重要な数値データの場合は、カンマやピリオドを除去して数字列として読み取り、システム側で後から桁区切りを付与するという運用で回避することもあります。
【盲点】なぜあなたのOCRは「数字」を読み間違えるのか?精度99%を目指すプロの設定術
「最新のOCRを導入したのに、結局人間が修正している」「数字の誤認識が多くて、かえって時間がかかる」
もしそう感じているなら、それはOCRエンジンの性能不足ではなく、設定や帳票設計の「ほんの少しのボタンの掛け違い」が原因かもしれません。
実は、数字の読み取り精度を劇的に向上させるには、AI任せにするのではなく、人間側が「AIが迷わない環境」を整えてあげることが不可欠なのです。
OCRにとって「数字」は、アルファベットや記号と混同しやすい非常に厄介なデータです。「0」と「O」、「1」と「I」、「8」と「B」など、形状が酷似した文字は、前後の文脈を理解できない従来型エンジンにとって最大の鬼門となります。
さらに、現場でよくある「7セグメント(デジタル表示)」や「ドット文字」は、文字の線が途切れているため、ノイズとして処理されがちです。手書きに至っては、枠からのはみ出しや傾きが、誤認識の連鎖を引き起こします。
しかし、諦める必要はありません。専門家は以下のテクニックで、これらの課題をクリアしています。
- 読み取り文字種の限定読み取りエリアに対して「数字のみ」という制約を設けます。これにより、AIの選択肢からアルファベットや漢字を排除し、「O」か「0」か迷う余地を物理的に消滅させます。
- 画像の前処理(プリプロセス)の徹底スキャン画像の「二値化(白黒変換)」や「ノイズ除去」を行い、文字の輪郭をくっきりさせます。また、帳票の枠線をスキャナで消える色(ドロップアウトカラー)で印刷することで、文字と枠線の干渉を防ぎ、数字だけを浮き上がらせる工夫も極めて有効です。
- 桁数指定とチェックデジット「郵便番号は7桁」「電話番号は10桁」といったルールや、チェックデジット(論理計算による検査)を組み合わせることで、誤読があった場合にシステム側で即座にエラー判定し、目視チェックの対象を絞り込むことができます。
これらの「AIへの気遣い」を行うだけで、認識率は嘘のように改善します。高価なシステムを買い替える前に、まずは設定と運用の見直しから始めてみてはいかがでしょうか。
引用元:
画像認識技術およびOCR導入現場における実証データより。OCRエンジンの認識精度は、画像品質(DPIや二値化処理)と定義設定(ROIの最適化、文字種制限)に強く依存することが知られています。特に手書き帳票においては、ドロップアウトカラーの活用により認識率が有意に向上することが確認されています。(OCR導入支援・技術解説資料に基づく)
まとめ
企業は労働力不足や業務効率化の課題を抱える中で、OCRや生成AIの活用がDX推進の切り札として注目されています。
しかし、本記事で解説したように、OCRの精度を維持するためには専門的なチューニングや細かい設定が必要不可欠であり、「社内にそこまで詳しい人材がいない」「調整に時間をかけられない」といった理由で、導入のハードルが高いと感じる企業も少なくありません。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
面倒な設定やチューニングを必要とせず、請求書の読み取りやデータ化、メール作成、議事録作成など、さまざまな業務を「アプリ」として選ぶだけで、誰でも直感的にAIを活用できます。
今回解説したような高度な文字認識技術も、Taskhubなら裏側で最新のAIが処理してくれるため、ユーザーは難しいことを考える必要がありません。
しかも、Azure OpenAI Serviceを基盤にしているため、データセキュリティが万全で、情報漏えいの心配もありません。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「何をどう使えばいいのかわからない」という初心者企業でも安心してスタートできます。
導入後すぐに効果を実感できる設計なので、複雑なプログラミングや高度なAI知識がなくても、すぐに業務効率化が図れる点が大きな魅力です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最速の生成AI活用”を体験し、御社のDXを一気に加速させましょう。







