

「RAGを実装したいけれど、読むべき論文が多すぎてどこから手をつければいいかわからない」
「最新のGraphRAGやSelf-RAGといった技術用語をよく耳にするが、具体的な仕組みやメリットが把握できていない」
生成AIの開発や導入が進む中で、こういった情報のキャッチアップに関する悩みを抱えているエンジニアや研究者の方も多いのではないでしょうか?
RAG(Retrieval-Augmented Generation)の分野は日進月歩で進化しており、毎週のように新しい手法や改善案が発表されています。すべてを精読するのは現実的ではありません。
本記事では、RAGの基礎となる必読論文から、2025年の最新トレンドであるGraphRAGやエージェンティックRAGに至るまで、実務に役立つ30本の論文を厳選して体系的に解説しました。
生成AIを活用したシステム開発をメインに手掛ける弊社が、実際に技術選定の参考にしている信頼性の高い論文のみをピックアップしています。
この記事を読めば、RAGの進化の歴史と最新技術の全体像を掴むことができ、自社のシステムに最適なアーキテクチャを選定するヒントが得られるはずです。ぜひ最後までご覧ください。
まずはここから!RAGの全体像を掴むためのサーベイ論文
RAG技術を深く理解するためには、個別の手法に飛びつく前に、まずは全体像を俯瞰することが重要です。
ここでは、RAGの基本概念を定義した原典から、派生技術を体系化したサーベイ論文、そして実装時に避けるべき失敗パターンをまとめた論文を紹介します。
これらを押さえることで、後のセクションで紹介する最新技術が「どの課題を解決するためのものか」が明確になります。
RAGの進化と体系を網羅した『Retrieval-Augmented Generation for LLMs』
この論文は、RAG(検索拡張生成)という概念がどのように生まれ、どのように発展してきたかを包括的にまとめた、まさにRAGの教科書とも言えるサーベイ論文です。
初期の「Naive RAG(単純な検索)」から、検索精度や生成品質を向上させるための「Advanced RAG(高度なRAG)」、そして複数のモジュールを組み合わせる「Modular RAG(モジュール式RAG)」へと至る進化の過程が詳細に解説されています。
特に重要なのは、RAGを構成する「検索(Retrieval)」「生成(Generation)」「強化(Augmentation)」という3つのフェーズにおける技術的課題と、それに対する既存の解決策が整理されている点です。
これからRAGの研究や開発を始める人が、現在地を把握するために最初に読むべき一冊として広く認知されています。
また、RAGとファインチューニングの比較や、評価指標についても言及されており、この分野の地図として機能します。
こちらはRAGの研究動向や将来の課題について網羅されたサーベイ論文です。 合わせてご覧ください。 https://arxiv.org/html/2511.17689v1
モジュール式RAG(Modular RAG)へのパラダイムシフト
RAGシステムを単なる「検索して回答する」だけのパイプラインとしてではなく、独立した機能を持つモジュールの集合体として捉え直す「Modular RAG」の概念を提唱した重要な論文です。
従来のRAGは、インデックス作成、検索、生成という固定されたフローで動作していましたが、この論文では、必要に応じてモジュールを入れ替えたり、再構成したりできる柔軟なアーキテクチャを提案しています。
例えば、検索クエリを書き換えるモジュール、検索結果をリランク(再順位付け)するモジュール、あるいは検索を行わずにLLMの知識だけで回答するルーティングモジュールなどを組み合わせることで、より複雑なタスクに対応可能になります。
この考え方は、現在のAgentic RAG(エージェント型RAG)や、LangChainなどのフレームワークにおける実装思想の基盤となっており、システム設計の自由度を飛躍的に高めました。
固定的なフローからの脱却は、精度の向上だけでなく、システムの保守性や拡張性においても大きなメリットをもたらします。
こちらはModular RAGの概念とアーキテクチャについて提唱している論文です。 合わせてご覧ください。 https://arxiv.org/abs/2407.21059
RAGシステムの構築で直面する7つの失敗点(Seven Failure Points)
理論上は完璧に見えるRAGシステムでも、実際に構築してみると期待通りの精度が出ないことは多々あります。
この論文は、RAGシステムの実装時によく遭遇する7つの失敗ポイント(Failure Points)を具体的に特定し、それぞれの解決策を提示した実践的なガイドです。
具体的には、「検索漏れ」「検索結果の誤り」「コンテキストの不整合」「生成時のハルシネーション」などが挙げられています。
著者は、これらの失敗がプロセスのどの段階(インデックス時、クエリ作成時、検索時、生成時)で発生するかを分析し、それに対する具体的な対策を示しています。
例えば、回答に必要な情報がドキュメントに含まれていない場合や、検索されたドキュメントが正しいにもかかわらずLLMが誤った回答を生成する場合など、現場のエンジニアが直面する「あるある」が網羅されています。
トラブルシューティングの際のチェックリストとして非常に有用であり、開発の手戻りを防ぐために必読の内容です。
こちらはRAG運用における失敗事例と対策について分析した論文です。 合わせてご覧ください。 https://arxiv.org/abs/2401.05856
RAG論文から学ぶ回答精度を飛躍的に高める「検索・生成」改善の手法
基本的なRAGシステムを構築した後、次に直面するのは「回答精度の壁」です。
検索した情報が的外れだったり、LLMが情報を正しく使えなかったりする問題に対処するために、多くの研究者が改善手法を提案しています。
ここでは、自己評価、クエリ修正、リランクなど、RAGの各プロセスを強化するための重要な論文を紹介します。
検索結果を自己評価して質を高める『Self-RAG』の仕組み
Self-RAG(Self-Reflective Retrieval-Augmented Generation)は、LLMが自身の生成プロセスを批判的に評価(自己省察)しながら回答を作成する画期的なフレームワークです。
従来のRAGは、検索したドキュメントを盲目的に信じて回答を生成していましたが、Self-RAGでは「検索が必要か?」「検索結果は適切か?」「生成された回答は有用か?」といった判断を、特殊なトークンを用いて自律的に行います。
具体的には、検索した情報がクエリに関連しているかを評価する「IsREL」、生成された文章がドキュメントに基づいているかを確認する「IsSUP」、そして回答がユーザーの意図を満たしているかを判定する「IsUSE」などの指標を用います。
これにより、不要な検索を抑制して推論速度を上げたり、質の低い検索結果を破棄してハルシネーションを低減したりすることが可能になります。
LLM自体に判断能力を持たせるこのアプローチは、後のAIエージェントの発展にも大きな影響を与えました。
こちらはSelf-RAGの自己省察フレームワークについて解説した論文です。 合わせてご覧ください。 https://arxiv.org/abs/2310.11511
検索の要否判断と修正を行う『CRAG(Corrective RAG)』
CRAG(Corrective Retrieval-Augmented Generation)は、検索結果の品質が低い場合に、それを修正するためのメカニズムを組み込んだ手法です。
検索結果が不正確なまま生成を行うと、誤った情報(ハルシネーション)が出力されるリスクがあります。
CRAGでは、軽量な評価モデル(Evaluator)を導入し、検索されたドキュメントの信頼性を「Correct(正確)」「Ambiguous(曖昧)」「Incorrect(不正確)」の3段階で判定します。
判定結果が「Correct」であればそのまま生成に進みますが、「Incorrect」の場合はWeb検索などの外部知識を利用して情報を補完します。「Ambiguous」の場合は、内部知識と外部知識を組み合わせて回答を精査します。
このように、検索結果の質に応じて動的にプロセスを分岐させることで、ノイズの多いデータセットや難易度の高い質問に対しても、頑健で正確な回答を生成できるようになります。
エラーを自動修正するこの仕組みは、実運用における安定性を大きく向上させます。
こちらは生成AIを企業で利用する際のリスクと具体的な対策について解説した記事です。 合わせてご覧ください。
クエリを仮想的な回答に変換して検索する『HyDE』
HyDE(Hypothetical Document Embeddings)は、ユーザーの質問(クエリ)と検索対象のドキュメント(チャンク)の間の「意味的なギャップ」を埋めるための手法です。
通常、質問文は短く抽象的であるのに対し、回答を含むドキュメントは具体的で長文であることが多いため、単純なベクトル検索ではマッチング精度が落ちることがあります。
HyDEでは、検索を行う前に、LLMを使ってクエリに対する「仮想的な回答(Hypothetical Document)」を生成させます。
この仮想回答は、事実は不正確かもしれませんが、回答に必要なキーワードや文脈を含んでいるはずです。
この仮想回答をベクトル化して検索を行うことで、質問文そのもので検索するよりも、実際の回答ドキュメントに近いベクトル空間を探すことが可能になります。
学習済みのリトリーバー(検索器)をそのまま使用でき、追加の学習コストをかけずに検索精度(特にRecall)を向上させることができるため、即効性のある改善策として多くのシステムで採用されています。
こちらはAIへの効果的な指示(プロンプト)のテンプレート集です。 合わせてご覧ください。
検索結果の順位を再考して精度を上げる「リランク(Re-ranking)」関連論文
ベクトル検索(Dense Retrieval)は意味的な近さを捉えるのに優れていますが、必ずしもユーザーの意図に最も適した文書が上位に来るとは限りません。
そこで登場するのが、検索された上位のドキュメント群(例えばトップ50件)に対して、より高精度なモデルで再度スコアリングを行い、順位を並べ替える「リランク(Re-ranking)」技術です。
この分野の論文では、Cross-Encoderを用いた手法や、LLM自体をリランカーとして使用する手法などが提案されています。
特に「Lost in the Middle」現象(LLMはコンテキストの中間にある情報を忘却しやすい)への対策として、最も重要なドキュメントをコンテキストの先頭や末尾に配置する並べ替え戦略も研究されています。
リランクを導入することで、最初の検索(Retrieval)は広めに拾い、その後のフィルタリングで精度を高めるという「漏れがなく、かつ正確な」システム構築が可能になります。
計算コストとのトレードオフはありますが、最終的な回答品質への寄与度は非常に高い技術です。
ノイズデータがRAGに与える影響を分析した『The Power of Noise』
RAGシステムにおいて、検索されたドキュメントの中に、回答とは無関係な「ノイズ」が含まれている場合、LLMの生成精度にどのような影響を与えるのかを分析した論文です。
直感的にはノイズは排除すべきものと考えられますが、この研究では、適度なノイズや関連性の低い情報が含まれていることが、逆にLLMの推論能力や頑健性(Robustness)を高める可能性があることを示唆しています。
もちろん、完全に誤った情報は有害ですが、ある程度の「Distractor(注意を逸らす文書)」が存在する状況下で正解を導き出す訓練をすることで、モデルは文脈をより深く理解し、情報の取捨選択能力を向上させることができます。
この知見は、検索精度の目標設定や、学習データの作成方針に新たな視点を与えました。
単にノイズをゼロにするのではなく、ノイズに強い生成モデルやプロンプト設計を考えることの重要性を説いています。
構造化データで推論能力を強化する「GraphRAG」関連の論文
従来のRAGは、テキストをチャンク(断片)化してベクトル検索を行うのが一般的でしたが、これだけでは情報の「つながり」や「全体像」を把握するのが困難でした。
そこで注目されているのが、ナレッジグラフ(知識グラフ)を活用したGraphRAGです。
ここでは、Microsoftが提唱したGraphRAGをはじめ、構造化データを活用して複雑な推論を可能にする最新論文を紹介します。
ナレッジグラフとLLMを融合させた『GraphRAG』の衝撃
2024年にMicrosoft Researchから発表され、大きな話題となったGraphRAGは、従来のベクトル検索ベースのRAGが苦手としていた「データセット全体の要約」や「点と点を結ぶ複雑な質問」に対応するための手法です。
この手法では、LLMを用いてドキュメント群からエンティティ(人、場所、組織など)とそれらの関係性を抽出し、ナレッジグラフを構築します。
さらに、グラフ上のコミュニティ(関連性の強いグループ)ごとに要約を生成しておくことで、階層的な情報探索を可能にします。
例えば、「この文書全体で語られている主なテーマは何か?」といった包括的な質問(Global Query)に対して、GraphRAGは個別のチャンク検索では得られない、全体を俯瞰した回答を提供できます。
単純なキーワード一致やベクトル類似度を超えて、情報の構造的なつながりを理解して回答を生成するため、分析業務や複雑なドメイン知識を扱うタスクにおいて圧倒的な性能を発揮します。
RAGの新たなスタンダードとして、現在最も注目されている技術の一つです。
こちらはMicrosoft ResearchによるGraphRAGのアプローチについて解説した論文です。 合わせてご覧ください。 https://arxiv.org/abs/2404.16130
テキストデータとグラフ構造を組み合わせて推論する『GNN-RAG』
GNN-RAGは、Graph Neural Networks(グラフニューラルネットワーク)の力を借りて、RAGの推論能力を強化するアプローチです。
ナレッジグラフ上のエンティティや関係性を、GNNを用いて高密度なベクトル表現に変換し、それをLLMの入力として統合します。
これにより、テキスト情報だけでは捉えきれない、エンティティ間の隠れた関係性や多層的なつながりを考慮した回答生成が可能になります。
従来のGraphRAGが「構造化されたテキスト」をLLMに読ませるアプローチだとすれば、GNN-RAGは「構造情報そのもの」を数学的な表現としてモデルに組み込むアプローチと言えます。
特に、創薬や金融分析など、データ間の関係性が答えの鍵を握る分野でその有効性が示されています。
テキストの流暢さと、グラフ構造の論理的な強さを兼ね備えたハイブリッドなRAGシステムの実現に向けた重要な研究です。
マルチホップ推論(複雑な問い)に強くなる『MultiHop-RAG』
「A社のCEOの出身大学がある州の知事は誰か?」のように、一つのドキュメントだけでは答えが出ず、複数の情報を連鎖的に辿る必要がある質問を「マルチホップ質問」と呼びます。
通常のRAGでは、最初の検索で関連文書が見つからなければそこで手詰まりになりますが、MultiHop-RAGに関連する研究では、一度検索した結果をもとに新たなクエリを生成し、段階的に情報を探索していく手法が提案されています。
ナレッジグラフを活用する場合、エンティティ間のリンクを辿る(ホップする)ことで、直接的なキーワードが含まれていない文書にも到達できます。
この論文群では、どのように効率的にグラフや文書間を移動し、推論のパス(経路)を構築するかが議論されています。
複雑な調査業務や、断片的な情報から真実を導き出す探偵のようなタスクにおいて、このマルチホップ推論能力は不可欠な要素となります。
RAG vs ファインチューニング vs 長文コンテキストの比較論文
「RAGとファインチューニング、どちらが良いのか?」
「コンテキストウィンドウが広がれば、RAGは不要になるのではないか?」
これらは、LLM開発の現場で常に議論されるテーマです。
ここでは、これらの手法の比較検証や、それぞれの強みを組み合わせたハイブリッドなアプローチに関する論文を解説します。
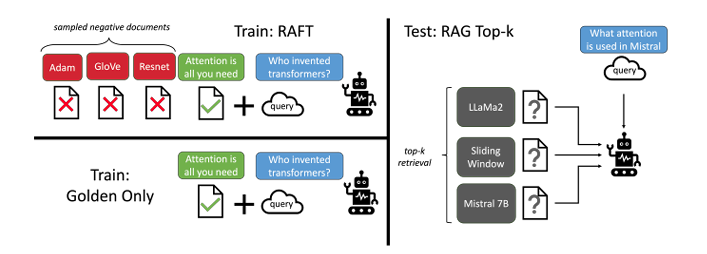
RAGとファインチューニングの使い分け・統合『RAFT』
RAFT(Retrieval Augmented FineTuning)は、RAGとファインチューニング(FT)を対立するものとしてではなく、相互補完的な技術として統合した手法です。
通常のFTは知識をモデルに焼き付けるために使われますが、RAFTでは「検索されたドキュメントを正しく読み解き、回答に使用する能力」を高めるためにFTを行います。
具体的には、質問に対して「正解ドキュメント」と「無関係なドキュメント(Distractor)」を混ぜた入力を与え、正解ドキュメントから情報を抽出して回答するようにモデルを訓練します。
これにより、モデルはドメイン固有の知識をある程度記憶しつつ、RAG特有の「与えられたコンテキストから答えを探す」スキルを飛躍的に向上させることができます。
「知識を覚えるFT」から「カンニングの仕方を覚えるFT」への転換とも言えるこのアプローチは、特定の専門分野(法律や医療など)でRAGシステムを構築する際に、精度を最大化するための現実解として非常に有効です。
こちらはRAGとファインチューニングを統合したRAFT手法に関する論文です。 合わせてご覧ください。 https://arxiv.org/abs/2403.10131
100万トークンの長文入力はRAGを不要にするか?(Long-Context LLMs Subsume RAG?)
Gemini 1.5 ProやGPT-4o、そして2025年8月にリリースされたGPT-5のように、LLMのコンテキストウィンドウ(扱える文字数)は爆発的に増加しています。
数冊の本を丸ごとプロンプトに入力できるようになった今、「わざわざ検索システム(RAG)を作る必要があるのか?」という疑問に答えるのがこの論文です。
結論として、長文コンテキストモデルは強力ですが、RAGを完全に置き換えるものではないと論じられています。
理由として、コンテキストが極端に長くなると「Lost in the Middle」現象により情報の取得漏れが発生することや、毎回膨大なテキストを入力することによるコストとレイテンシ(応答遅延)の問題が挙げられます。
また、企業のナレッジベース全体のようなテラバイト級のデータをすべてコンテキストに入れることは物理的に不可能です。
論文では、データの規模や更新頻度、コスト要件に応じて、RAGと長文コンテキストを使い分ける、あるいは併用することの重要性が示されています。
こちらはRAGの未来にも影響を与えるGPT-5の最新情報について解説した記事です。 合わせてご覧ください。
長文コンテキストと検索を組み合わせた『LongRAG』
LongRAGは、従来のRAGと長文コンテキストLLMの利点を組み合わせた新しいフレームワークです。
従来のRAGでは、ドキュメントを数百トークンの小さな「チャンク」に分割して検索していましたが、これでは文脈が分断され、全体的な意味が失われることがありました。
LongRAGでは、検索単位を大幅に拡大し、数千〜数万トークンの大きなブロック(あるいはドキュメント全体)を検索してLLMに渡します。
最新のLLMが持つ長いコンテキスト処理能力を活かすことで、細かいチャンク化による情報の欠落を防ぎ、よりリッチな文脈に基づいた回答生成を可能にします。
「検索は大まかに、読解は詳細に」というアプローチであり、検索システムの負担を減らしつつ、LLMの読解力でカバーする戦略です。
コンテキストウィンドウの拡大というハードウェア(モデル)の進化を、ソフトウェア(RAGアーキテクチャ)に最適化した例と言えます。
RAG論文に見るシステムの性能を正しく測る「評価指標(Evaluation)」
RAGシステムを改善するためには、その性能を定量的・定性的に評価する必要があります。
「なんとなく良くなった気がする」では、ビジネスでの導入は進みません。
ここでは、RAGの評価におけるデファクトスタンダードとなっているRAGASや、合成データを用いた自動評価システムについての論文を紹介します。
RAG評価のデファクトスタンダード『RAGAS』の評価観点
RAGAS(RAG Assessment)は、正解データ(Ground Truth)がなくてもRAGシステムを評価できるフレームワークとして提案された論文です。
LLMを用いて、以下の主要な指標を自動的にスコアリングします。
- Faithfulness(忠実性): 生成された回答が、検索されたコンテキストの内容に基づいているか(ハルシネーションがないか)。
- Answer Relevance(回答の関連性): 生成された回答が、ユーザーの質問に対して適切に答えているか。
- Context Precision(コンテキスト適合率): 検索されたドキュメントの中に、回答に必要な情報が含まれているか。
これらの指標を用いることで、RAGシステムのどの部分(検索器なのか、生成器なのか)に問題があるかを切り分けることができます。
人手による評価はコストと時間がかかりますが、RAGASを用いることで開発サイクルを高速化できるため、現在のRAG開発においてほぼ標準的なツールとして採用されています。
継続的な改善(CI/CD)のパイプラインに評価を組み込む際にも非常に重要です。
こちらはRAGの自動評価フレームワークであるRAGASについて解説した論文です。 合わせてご覧ください。 https://arxiv.org/abs/2309.15217
合成データを用いてRAGシステムを評価する『ARES』
ARES(Automated RAG Evaluation System)は、少数の手作業によるラベル付きデータを用いて、大規模なRAGシステムの評価を自動化する手法です。
RAGの評価には本来、大量の「質問・コンテキスト・回答」のペアが必要ですが、これを用意するのは大変な労力です。
ARESでは、LLMを用いて合成データ(Synthetic Data)を生成し、それを使って評価モデルを訓練します。
特徴的なのは、生成された合成データの品質を統計的に保証する仕組み(Prediction-Powered Inference)を取り入れている点です。
これにより、限られた正解データしかない状況でも、高い信頼区間でシステムの精度を推定することが可能になります。
ドメイン特化型のRAGを構築する際、評価データセットが不足しているケースは多いため、ARESのようなアプローチは実務的にも非常に価値があります。
包括的なベンチマークテスト『CRAG Benchmark』
Meta社などが発表したCRAG Benchmarkは、RAGシステムの包括的な性能を測るために設計された大規模なデータセットと評価基準です。
従来のベンチマークは、事実に基づいた単純な質問応答が中心でしたが、CRAG Benchmarkでは、情報が変化する動的な質問、回答が存在しない質問、複数の推論ステップが必要な質問など、より現実的で困難なタスクが含まれています。
Web検索の結果に含まれるノイズや、時間の経過による情報の陳腐化など、実世界でRAGが直面する課題を模しており、モデルの真の実力を測ることができます。
このベンチマークで高いスコアを出すことは、単に暗記力が良いだけでなく、情報の検索・選別・統合・推論というRAGの全プロセスが高いレベルにあることを意味します。
最新のRAGモデルの性能比較において、重要な指標となっています。
【目的・課題別】実装のヒントになるその他のRAG関連注目論文
ここまで紹介したカテゴリに当てはまらないものの、特定の実装課題や新しいユースケースにおいて重要な示唆を与えてくれる論文をピックアップしました。
コスト削減、画像対応、そして「そもそも検索しない」という選択肢まで、RAGの可能性を広げる研究です。
コスト最適化と応答速度に関する論文
RAGの実運用において避けて通れないのが、APIコストとレスポンス速度の問題です。
この分野の論文では、類似したクエリに対して過去の回答を再利用する「セマンティックキャッシュ」技術や、LLMを呼び出す前に軽量なモデルで回答可能かを判定する「アーリーイグジット」戦略などが提案されています。
また、ベクトルデータベースの検索速度を向上させるための量子化(Quantization)技術や、HNSWなどのインデックス手法に関する研究も重要です。
「高精度な回答」だけでなく、「経済的で高速なシステム」を作るためには、これらのエンジニアリング寄りの論文知識が不可欠です。
マルチモーダル(画像・テキスト)RAGの最新研究
テキストだけでなく、画像、図表、PDF内のレイアウト情報なども含めて検索・生成を行う「マルチモーダルRAG」の研究が急速に進んでいます。
例えば、製品のマニュアルに含まれる図を検索して回答したり、財務諸表のグラフを読み解いて数値を回答したりするシステムです。
関連論文では、CLIPのような画像とテキストを共通のベクトル空間に埋め込むモデルの活用や、画像からテキスト説明(キャプション)を生成してインデックス化する手法などが議論されています。
GPT-5などの最新モデルがマルチモーダルネイティブであることを踏まえると、今後のRAGは「文字を読む」だけでなく「資料を見る」能力が標準的に求められるようになります。
検索を行わない「生成のみ」の方が良いケースはあるか
「すべての質問に検索が必要なわけではない」という視点に立った研究です。
常識的な質問や、LLMが十分に学習している有名な事実については、RAGを使うとかえって検索ノイズが混じり、回答品質が下がることがあります。
この論文群では、質問の難易度や親密度(Familiarity)に応じて、RAGを使用するか、LLMの内部知識のみで回答するかを動的に切り替える「Adaptive RAG」のアプローチを提案しています。
無駄な検索を省くことは、コスト削減と速度向上に直結します。「RAG至上主義」にならず、適材適所で技術を使い分けるための判断基準を提供してくれます。
【時系列まとめ】RAG論文のトレンド変遷リスト(2020年〜現在)
最後に、RAG技術がどのように進化してきたかを時系列で整理します。
歴史を知ることで、現在の技術が「なぜ生まれたのか」という背景が理解でき、未来のトレンド予測にも役立ちます。
2020年〜2023年:RAGの黎明期と基礎理論
- 2020年: Facebook AI(現Meta)が『Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks』を発表。RAGという言葉が定着する。
- 2021-2022年: ベクトル検索エンジンの普及とともに、実務での導入実験が始まる。Dense Passage Retrieval (DPR) などの検索技術が洗練される。
- 2023年: ChatGPTの爆発的普及により、ハルシネーション対策としてRAGが一気に注目される。LangChainやLlamaIndexなどのライブラリが登場し、Naive RAGの実装が容易になる一方、精度不足の課題も浮き彫りになる。HyDEやRe-rankingなどの個別の改善手法が提案され始める。
2024年以降:Self-RAG・GraphRAG・Agentic RAGへの進化
- 2024年: 単純な検索では限界があることが認識され、Self-RAGやCRAGのような「考えてから検索する」「結果を評価する」手法が登場。また、GraphRAGにより構造化データの活用が進む。
- 2025年: GPT-5の登場(8月)により、モデル自体の推論能力が飛躍的に向上。これに伴い、RAGは単なる知識検索装置から、複雑なタスクを遂行する「AIエージェント」の記憶・調査モジュールへと進化。自律的にプランニングを行い、何度も検索と推論を繰り返す「Agentic RAG」が主流となりつつある。また、マルチモーダル対応や、エッジデバイスでの軽量RAGなども研究のホットトピックとなっている。
RAG論文を読む際によくある質問
最後に、これからRAG論文を読み進める方からよく寄せられる質問にお答えします。
最新の論文はどこで探すのが効率的ですか?
基本的には「arXiv(アーカイブ)」のCS(コンピュータサイエンス)カテゴリ、特に「Computation and Language (cs.CL)」をチェックするのが一番です。
しかし、毎日大量の論文が投稿されるため、すべてを追うのは困難です。
効率的なのは、X(旧Twitter)で著名なAI研究者(AK氏など)をフォローすることや、Hugging Faceの「Daily Papers」をチェックすることです。
また、RedditのLocalLLaMAコミュニティや、AI系のニュースレターを購読するのも、重要な論文を見逃さないための良い方法です。
論文の実装コード(GitHub)は公開されていますか?
多くの主要な論文は、GitHub上でコードが公開されています。
論文タイトルの横に「Code」リンクがある場合が多いですし、「Papers with Code」というサイトを使えば、論文に対応する実装リポジトリを簡単に探すことができます。
ただし、研究用のコードはそのまま本番環境で使える品質ではないことも多いため、LangChainやLlamaIndexなどのライブラリがその手法を公式にサポートしているかを確認し、ライブラリ経由で実装するのが一般的かつ安全です。
英語論文を効率よく読むためのツールはありますか?
最近では、AIを活用した論文読解支援ツールが非常に充実しています。
例えば、「ChatPDF」や「SciSpace (Typeset)」などのツールを使えば、PDFをアップロードして「この論文の要点は?」「提案手法の新規性は?」とチャット形式で質問することができます。
また、ブラウザ拡張機能の「Immersive Translate」を使えば、PDFのレイアウトを崩さずに日本語と英語を並列表示して読むことができます。
まずはAIに要約させて全体像を掴み、気になった部分だけ原文を精読するスタイルが、現代の効率的な論文の読み方と言えるでしょう。
開発現場の「手探り」を終わらせる!RAG論文こそが最短の攻略ルートだ
RAGの実装において、多くのエンジニアやプロジェクトマネージャーが「検索精度が上がらない」「ハルシネーションが消えない」といった壁にぶつかります。しかし、その悩みの多くは、実はすでに世界のどこかの研究者が解決策を提示しており、論文として公開されています。今回紹介したような論文群は、単なる学術的な読み物ではありません。実務におけるトラブルシューティングの「答え合わせ」ができる宝庫なのです。
例えば、「Seven Failure Points」を知らずにシステムを構築するのは、地図を持たずに迷宮に入るようなものです。事前に失敗パターンを知っていれば、開発の手戻りを防ぐことができます。また、最新の「GraphRAG」や「Self-RAG」の概念を理解していれば、古い手法に固執して無駄なリソースを費やすこともありません。
論文を読み解くことは、車輪の再発明を防ぎ、開発サイクルを劇的に加速させるための最も賢い投資と言えるでしょう。「動くものを作る」だけでなく「なぜ動くのか(あるいは動かないのか)」を理論から理解することが、変化の激しい生成AI時代を生き残る鍵となります。
引用元:
RAGシステムの構築時によくある失敗とその対策については、Barnettらの研究が詳細なガイドラインを提供しています。(Barnett, S., et al. “Seven Failure Points When Engineering a Retrieval Augmented Generation System” 2024年)
また、構造化データを活用した最新のアプローチについては、Microsoft ResearchによるGraphRAGの論文が重要な指針となります。(Edge, D., et al. “From Local to Global: A Graph RAG Approach to Query-Focused Summarization” 2024年)
まとめ
RAG技術は日進月歩で進化しており、Self-RAGやGraphRAGといった高度な手法を自社システムに組み込むには、高い技術力と継続的な情報収集が求められます。
しかし、多くの企業では「エンジニアのリソースが足りない」「最新技術を追いきれない」といった課題により、DXが進まないのが実情ではないでしょうか。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
複雑なRAGシステムの構築やプログラミングを行わなくても、メール作成や議事録作成、社内ドキュメントに基づいた回答生成など、業務に必要なAI機能を「アプリ」として選ぶだけですぐに使えます。
しかも、Azure OpenAI Serviceを基盤にしているため、データセキュリティが万全で、機密情報を扱う企業でも安心して導入可能です。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、技術的な知見がない企業でもスムーズに運用を開始できます。
高度な技術開発は専門家に任せ、成果だけを享受する賢い選択肢です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最速の生成AI活用”を体験し、御社のDXを一気に加速させましょう。







