

「RAGを導入したいが、種類が多くてどれを選べばいいかわからない」
「GraphRAGやAdvanced RAGなど、専門用語が難しくて違いが理解できない」
企業での生成AI活用が進む中、社内データをAIに参照させるRAG(検索拡張生成)技術に注目が集まっています。
しかし、ひとくちにRAGと言っても、基本的な手法から高度な検索技術、実装サービスの形態まで、その種類は多岐にわたります。
自社の課題に合わないRAGを選んでしまうと、期待した回答精度が出なかったり、開発コストが膨らんだりするリスクがあります。
本記事では、RAGの技術的なアーキテクチャの違いから、具体的な構築サービスの種類までを体系的に解説しました。
最新のRAGトレンドである「GraphRAG」や「Agentic RAG」についてもわかりやすく紹介しています。
自社に最適なRAGの形を見つけるための判断材料として、ぜひ最後までご覧ください。
RAG(検索拡張生成)とは?基本の仕組みと種類の違い
まずは、RAG(Retrieval-Augmented Generation)の基本的な仕組みと、なぜこれほど多くの種類が存在するのかという背景について解説します。
RAGは、AIが回答を生成する際に、外部のデータベースから関連情報を検索し、その情報を参考にして回答を作成する技術です。
単純にデータを検索するだけでなく、AIの生成能力を組み合わせることで、自然な文章での回答が可能になります。
この基本構造を理解することで、後に解説する様々な種類の違いがより明確になります。
それでは、基本的な構造と種類の多様性について見ていきましょう。
RAGの基本構造(検索フェーズと生成フェーズ)
RAGの仕組みは、大きく分けて「検索フェーズ(Retrieval)」と「生成フェーズ(Generation)」の2つのプロセスで構成されています。
この2つの工程が連携することで、AIは学習していない社内固有の情報に基づいた正確な回答を行うことができます。
まず検索フェーズでは、ユーザーからの質問に関連するドキュメントやデータを、あらかじめ用意したデータベースから探し出します。
一般的には、文書を数値ベクトルに変換して意味の近さを測る「ベクトル検索」などが用いられます。
ここで適切な情報が見つからなければ、AIは正しい回答を作ることができません。
次に生成フェーズでは、検索で見つかった情報をプロンプト(指示文)に組み込み、LLM(大規模言語モデル)に渡します。
LLMは渡された情報を「正解データ」として参照し、ユーザーの質問に対する回答を生成します。
つまり、RAGとは「カンニングペーパー付きのテスト」のようなものであり、検索フェーズでいかに優れたカンニングペーパーを用意できるかが重要です。
基本的なRAGはこのシンプルな構造ですが、実際のビジネス現場では、これだけでは回答精度が不十分なケースが多々あります。
そのため、各フェーズに工夫を凝らした様々な種類の手法が生まれているのです。
LLM(大規模言語モデル)の仕組みや主要なモデルについては、こちらの記事で詳しく解説しています。 合わせてご覧ください。
なぜ多様なRAGの種類・アーキテクチャが必要なのか
RAGに多くの種類やアーキテクチャが存在する理由は、ビジネス現場で求められる要件の複雑さと、LLM単体の限界にあります。
単純なRAGでは対応しきれない課題を解決するために、技術は進化し続けてきました。
初期のシンプルなRAGでは、検索した文書の中に無関係な情報が混ざっていたり、必要な情報が漏れていたりすると、AIが誤った回答(ハルシネーション)をすることがありました。
また、複雑な推論が必要な質問に対して、断片的な情報だけでは答えられないという問題もありました。
例えば、「A社の2023年の売上と2024年の見込みを比較して要約して」といった質問には、複数の文書から情報を集めて統合する能力が求められます。
こうした課題に対し、検索精度を上げるための工夫や、AIに回答を評価させる仕組み、あるいは複雑な質問を分解して処理する手法などが開発されました。
さらに、企業のセキュリティポリシーや開発リソースに応じて、システムの実装形態も多様化しています。
結果として、技術的なアプローチの違いと、製品としての提供形態の違いが絡み合い、多くの「RAGの種類」が存在することになったのです。
RAG技術の包括的な調査や、LLMにおける検索拡張生成の全体像については、こちらの論文で詳しく論じられています。技術的な背景をより深く知りたい方は合わせてご覧ください。 https://arxiv.org/abs/2312.10997
技術的な「手法の種類」と実装上の「製品の種類」
RAGの種類を整理する際には、大きく分けて「技術的な手法」と「実装上の製品」の2つの軸で考えると理解しやすくなります。
これらを混同してしまうと、議論が噛み合わなくなることがあるため注意が必要です。
技術的な手法の種類とは、RAGのシステム内部でどのようなアルゴリズムや処理フローを採用しているかという分類です。
例えば、後述する「Advanced RAG」や「GraphRAG」などがこれに当たります。
これらは、「どうやって精度を高めるか」というHowの部分に関わる話であり、エンジニアやデータサイエンティストが主に関心を持つ領域です。
一方、実装上の製品の種類とは、RAGシステムを構築するためにどのようなツールやサービスを使うかという分類です。
「Azure OpenAI Service」や「Dify」、「Glean」などがこれに該当します。
これらは、「どのサービスを使って導入するか」というWhereの部分に関わる話であり、プロジェクトマネージャーやIT担当者が選定する領域です。
本記事では、まず技術的な手法の違いについて解説し、その後に具体的な製品・サービスの種類を紹介します。
両方の側面を知ることで、自社の課題に対してどの技術を、どのツールで実現すべきかが明確になるはずです。
【進化段階別】RAGの主なアーキテクチャ(技術的な種類)
RAGの技術は日々進化しており、その複雑さや機能によっていくつかの段階に分類することができます。
ここでは、RAGの進化プロセスを理解するために、代表的な3つのアーキテクチャについて解説します。
最も基本的な形から、実用性を高めるための工夫が施されたもの、そして柔軟にカスタマイズ可能なものへと進化してきました。
それぞれの特徴を知ることで、自社が目指すべきRAGのレベル感を掴むことができます。
それでは、各段階のアーキテクチャについて詳しく見ていきましょう。
Naive RAG(標準RAG):最も基本的でシンプルな構造
Naive RAG(ナイーブRAG)は、RAGの最も初期かつ基本的な形態です。
「ナイーブ」とは「単純な」という意味合いで使われており、特別なひねりを加えず、検索と生成を直線的に繋げただけの構造を指します。
多くのRAG入門記事や簡単なデモアプリで解説されているのは、このタイプです。
処理の流れは非常にシンプルです。
ユーザーが質問をすると、システムはそのままデータベースを検索し、上位数件のドキュメントを取得します。
そして、取得したテキストをそのままLLMに渡し、「以下の情報を参考にして回答して」と指示を出します。
構築が容易でコストも低いため、PoC(概念実証)や個人的な利用ではよく使われます。
しかし、Naive RAGには実用上の課題が多く残されています。
検索精度が低いと、関係のない情報をAIに渡してしまい、混乱した回答や誤った情報を生成するリスクが高まります。
また、質問の意図が曖昧な場合でもそのまま検索してしまうため、ユーザーが求めている情報にヒットしないこともしばしばあります。
ビジネスで本格的に活用するには、次に紹介する発展的な手法が必要になるケースがほとんどです。
Advanced RAG(発展系RAG):検索前後の処理で精度を高める手法
Advanced RAG(アドバンスドRAG)は、Naive RAGの弱点を克服するために、検索の前後に様々な処理を追加した手法です。
現在、多くの企業向けRAGシステムで採用されているのが、このAdvanced RAGの考え方です。
単に検索するだけでなく、「前処理」と「後処理」を行うことで、回答の品質を大幅に向上させます。
検索前の処理(Pre-Retrieval)では、ユーザーの質問を最適化します。
例えば、曖昧な質問を具体的になるように書き換えたり、一つの質問を複数の検索クエリに分解したりします。
これにより、データベースからより的確な情報を引き出すことが可能になります。
検索後の処理(Post-Retrieval)では、取得した情報の選別や並び替え(リランク)を行います。
検索でヒットした文書の中には、ノイズとなる情報が含まれていることもあります。
そこで、AIに渡す前に本当に重要な情報だけを厳選したり、情報の優先順位を整理したりします。
Advanced RAGは、こうしたひと手間を加えることで、より正確で信頼性の高い回答を実現するアーキテクチャです。
Modular RAG(モジュール型RAG):各機能を部品化して組み合わせる手法
Modular RAG(モジュラーRAG)は、RAGの各機能を独立したモジュール(部品)として扱い、必要に応じて自由に組み合わせるアーキテクチャです。
Naive RAGやAdvanced RAGを含めた、より包括的で柔軟な概念と言えます。
固定されたフローではなく、状況に合わせて最適な処理ルートを選択できるのが特徴です。
このアーキテクチャでは、「検索」「記憶」「書き換え」「検証」などの機能がそれぞれ独立しています。
例えば、ある質問に対しては検索を行わずに自身の知識で答え、別の質問に対してはWeb検索と社内データベースの両方を使う、といった柔軟な制御が可能です。
また、新しい技術やモデルが登場した際に、その部分のモジュールだけを入れ替えることで、システム全体をアップデートしやすいという利点もあります。
Modular RAGは、高度なAIアプリケーションを開発するための基盤となります。
複雑な業務フローにRAGを組み込む場合や、将来的な拡張性を持たせたい場合には、このモジュール型の設計思想が非常に有効です。
システムが大規模になるほど、この柔軟な構造の価値が高まっていきます。
Azure OpenAI Serviceを含む、企業向けの主要なChatGPT関連サービスについては、こちらの導入ガイドで詳しく解説しています。 合わせてご覧ください。
【検索・生成手法別】回答精度を高める高度なRAGの種類
前述のアーキテクチャをベースにしつつ、さらに具体的な技術手法として、回答精度を高めるための様々なアプローチが登場しています。
これらは「どうやって賢く検索するか」「どうやって情報を理解するか」に焦点を当てた技術です。
単なるキーワード一致やベクトル検索だけでは拾いきれない情報を扱うために、ナレッジグラフやエージェント技術などが活用されています。
ここでは、現在注目されている5つの高度な手法について解説します。
それぞれの特徴を理解し、自社のデータの性質に合った手法を選ぶことが重要です。
GraphRAG:ナレッジグラフを活用して関係性を理解させる
GraphRAGは、従来のテキスト検索に加えて「ナレッジグラフ」という技術を組み合わせた最新の手法です。
ナレッジグラフとは、物事の関係性を「点(ノード)」と「線(エッジ)」でネットワーク状に表現したデータベースのことです。
これにより、AIは単語の意味だけでなく、情報同士の繋がりや全体像を理解できるようになります。
通常のベクトル検索では、「Aプロジェクトの課題は?」という質問に対し、直接的に「課題」という言葉が含まれる文書を探します。
しかし、情報が複数の文書に分散している場合、それらを繋ぎ合わせて全体像を把握するのは苦手です。
GraphRAGを利用すると、Aプロジェクトに関連する人物、部署、過去の経緯といった相関関係を辿り、網羅的な回答を生成できます。
特に、特定のキーワードが明記されていない抽象的な質問や、「データセット全体の傾向を教えて」といった全体要約を求めるタスクにおいて、GraphRAGは圧倒的な強さを発揮します。
マイクロソフトなどの主要ベンダーも力を入れており、複雑な社内データを扱う企業にとって、非常に有力な選択肢となっています。
GraphRAGの具体的な手法や、ローカルからグローバルへの情報検索アプローチについては、Microsoft Researchによるこちらの論文が参考になります。 https://arxiv.org/abs/2501.00309
Hybrid Search(ハイブリッド検索):キーワード検索とベクトル検索を併用する
Hybrid Search(ハイブリッド検索)は、従来の「キーワード検索」と、AIを用いた「ベクトル検索」の両方の長所を組み合わせた手法です。
現在の実用的なRAGシステムにおいては、事実上の標準(デファクトスタンダード)となっている検索方式です。
二つの手法を掛け合わせることで、互いの弱点を補完し合います。
ベクトル検索は、言葉の意味や文脈を理解するのが得意です。
例えば、「PCの調子が悪い」と検索して「パソコンの不具合」に関するドキュメントを見つけることができます。
一方で、製品型番や人名、専門用語などの「固有名詞」を正確に検索するのは苦手な場合があります。
そこで、完全一致に強いキーワード検索を併用します。
型番やIDなどの正確な検索はキーワード検索に任せ、概念的な検索はベクトル検索に任せることで、取りこぼしのない高精度な検索結果を実現します。
RAGの精度に悩んだ場合、まずはこのハイブリッド検索が適切に実装されているかを確認するのが第一歩となります。
ハイブリッド検索の仕組みや、キーワード検索とベクトル検索を組み合わせた際のベンチマーク結果については、Weaviateによる解説記事が非常に詳しく参考になります。 https://weaviate.io/blog/hybrid-search-explained
HyDE:仮想の回答を生成してから類似文書を検索する
HyDE(Hypothetical Document Embeddings)は、検索の仕方を工夫したユニークな手法です。
通常のRAGではユーザーの「質問文」を使って検索を行いますが、HyDEではまずLLMに「仮想的な回答」を作らせ、その回答を使って検索を行います。
質問と回答では使われる単語や文体が異なるため、質問文だけで検索するよりも、回答に近い文書を探したほうが精度が上がるという発想です。
例えば、「社内規定における交通費のルールは?」という質問に対し、AIはいったん「交通費の精算は月末までに行い、領収書が必要です」といった仮の回答(嘘が含まれていても良い)を生成します。
そして、この仮の回答と似た内容が書かれている実際の社内規定ドキュメントを検索しにいきます。
これにより、質問文とドキュメントの表現にギャップがある場合でも、関連性の高い情報を見つけやすくなります。
この手法は、ユーザーの質問が短すぎたり、曖昧だったりする場合に特に効果を発揮します。
検索クエリを豊かにするためのテクニックの一つとして、Advanced RAGのプロセスの中に組み込まれることが多い手法です。
HyDE(Hypothetical Document Embeddings)の正確なアルゴリズムや、ゼロショット検索における有効性については、こちらの原典論文で詳細に解説されています。 https://arxiv.org/abs/2212.10496
Self-RAG / CRAG:AIが自ら検索結果の品質を評価・修正する
Self-RAG(Self-Reflective RAG)やCRAG(Corrective RAG)は、AIが自分自身の思考や検索結果を評価・修正するメカニズムを取り入れた手法です。
これまでのRAGは、検索して出てきた情報を無条件に信じて回答していましたが、これらの手法では「本当にこの情報は正しいか?」「検索結果は十分か?」を自問自答します。
Self-RAGでは、生成した回答が検索した情報に基づいているか、質問に対して適切かをAI自身がスコアリングし、品質が低い場合は再生成を行います。
CRAGでは、検索結果の信頼性を評価し、もし情報が不正確だと判断したら、Web検索など別の手段を使って情報を補完しにいくアクションを取ります。
これにより、誤った情報をあたかも正解のように語るハルシネーションのリスクを大幅に低減できます。
AIに「メタ認知(自分の認知を認知する能力)」を持たせるようなアプローチであり、より人間に近い慎重な判断が可能になります。
信頼性が最優先される業務においては、こうした自己評価機能を持つRAGの導入が進んでいます。
AIが生成内容を自己批判し修正する「Self-RAG」のフレームワークについては、こちらの論文で学習プロセスや評価指標が詳しく紹介されています。 https://arxiv.org/abs/2310.11511
Agentic RAG(エージェント型):自律的に判断してタスクを実行する
Agentic RAG(エージェント型RAG)は、AIを単なる回答生成器としてではなく、自律的に行動する「エージェント」として振る舞わせる手法です。
従来のRAGが「検索して答える」だけだったのに対し、Agentic RAGはユーザーの目標を達成するために、自ら計画を立て、道具を使い分けます。
例えば、「競合A社の最新製品について調べて、自社製品との比較表をExcelで作って」という指示があったとします。
Agentic RAGは、まずWeb検索で情報を集め、次に社内データベースから自社製品情報を検索し、足りない情報があれば追加で検索を行い、最終的にコードを実行してExcelファイルを生成する、といった一連の流れを自律的に行います。
ここではRAG(検索)は、エージェントが持つ道具の一つという位置付けになります。
OpenAIの最新モデルや推論能力の高いLLMと組み合わせることで、複雑なビジネス課題を解決できる強力なシステムとなります。
RAGの最終形とも言えるこの形態は、業務自動化の文脈で大きな注目を集めています。
【実装アプローチ別】RAG構築サービスの主な種類(製品・サービス)
技術的な手法を理解したところで、次はそれらをどうやって形にするか、つまり実装アプローチとサービスの選び方について解説します。
RAGを構築するには、大きく分けて「フルスクラッチ」「クラウドベンダーのサービス」「SaaS製品」の3つの選択肢があります。
自社のエンジニアリソースや予算、導入までのスピード感によって、最適な選択肢は異なります。
それぞれのメリット・デメリットを比較し、自社の体制に合った方法を選定しましょう。
フルスクラッチ開発(LLM+ベクトルデータベース)
フルスクラッチ開発は、オープンソースのライブラリ(LangChainやLlamaIndexなど)とベクトルデータベースを組み合わせて、ゼロからRAGシステムを構築する方法です。
使用するLLMのモデルから、検索アルゴリズム、UI/UXに至るまで、全てを自社で自由に設計できるのが最大の特徴です。
メリットは、カスタマイズ性が無限大であることです。
前述したGraphRAGや独自の評価ロジックなど、最先端の技術をいち早く取り入れたり、社内システムと深く連携させたりすることが可能です。
また、データの保管場所やセキュリティ設計も自社のポリシーに合わせて完全にコントロールできます。
一方で、デメリットは開発と運用の難易度が高いことです。
専門的な知識を持ったエンジニアが必要であり、初期開発だけでなく、継続的なメンテナンスやモデルのアップデート対応にも工数がかかります。
AI技術をコアコンピタンスとする企業や、特殊な要件がある大規模プロジェクト向けの選択肢と言えます。
クラウドベンダーのマネージドサービス(Azure, AWS, Google Cloud)
主要なクラウドベンダー(Azure, AWS, Google Cloud)が提供している、RAG構築のためのマネージドサービスを利用する方法です。
インフラやセキュリティ基盤はクラウド事業者が用意してくれるため、フルスクラッチに比べて開発の手間を大幅に削減できます。
例えば、Azure OpenAI Serviceの「On Your Data」機能などを使えば、データをアップロードするだけで比較的簡単にRAG環境を構築できます。
また、各社の最新AIモデル(GPT-5等も含む最新シリーズなど)や、高性能な検索エンジンをすぐに利用できるのも大きな利点です。
セキュリティ面でも、企業のエンタープライズレベルの基準を満たしていることが多く、社内稟議が通りやすいという側面もあります。
ある程度のカスタマイズ性を残しつつ、インフラ管理の負担を減らしたい企業にとって、最もバランスの取れた選択肢です。
多くの大手企業が、まずはこのアプローチでRAGの導入を進めています。
RAG搭載済みのSaaS・AIチャットボット製品
すでにRAG機能が組み込まれているパッケージ型のSaaS製品や、AIチャットボットツールを導入する方法です。
開発というプロセス自体がほぼ不要で、契約してデータを連携すれば、その日からすぐに使い始めることができます。
このタイプの製品は、管理画面が使いやすく設計されており、エンジニアでなくてもデータの登録やプロンプトの調整ができるものが多いです。
特定の業界や用途(例:カスタマーサポート特化、社内ヘルプデスク特化)に最適化された製品もあり、自社の課題にマッチすれば非常に高い費用対効果を発揮します。
ただし、裏側の仕組みはブラックボックス化されていることが多く、検索ロジックを細かく調整したり、独自のアルゴリズムを組み込んだりすることは難しい場合があります。
「とにかく早く導入したい」「社内に開発リソースがない」という企業にとっては、最適な選択肢となります。
主要なRAG製品・生成AIサービスの種類と具体例
ここでは、実際に市場で利用されている代表的なサービスや製品を具体的に紹介します。
クラウドベンダーの提供する基盤サービスから、企業内検索に特化したSaaS、開発プラットフォームまで、それぞれ異なる特徴を持っています。
これらの名前を知っておくことで、ベンダー選定や情報収集がスムーズに進むはずです。
Azure OpenAI Service (On Your Data)
Microsoftが提供するAzure OpenAI Serviceの機能の一つです。
OpenAI社の強力なモデル(GPT-4oや、最新のGPT-5等も利用可能)を、Azureの堅牢なセキュリティ環境下で利用できます。
「On Your Data」機能を使えば、Azure AI Searchと連携して、コーディングなしで素早くRAGを試すことができます。
Office 365などのマイクロソフト製品との親和性が高く、多くの企業で標準的な選択肢となっています。
Azure OpenAI Serviceの「On Your Data」機能を使用して、独自のデータを安全にAIに接続する手順については、Microsoft Learnの公式ドキュメントをご確認ください。 https://learn.microsoft.com/ja-jp/azure/ai-services/openai/concepts/use-your-data
Amazon Bedrock (Knowledge Bases)
AWSが提供する生成AIのフルマネージドサービスです。
「Knowledge Bases for Amazon Bedrock」という機能を使うことで、S3上のデータソースと接続したRAGアプリケーションを簡単に構築できます。
Amazon TitanやClaude、Llamaなど、多様な基盤モデルから好きなものを選べるのが特徴です。
すでにAWS上にデータ基盤を持っている企業にとっては、データの移動コストがなく、非常にスムーズに導入できるサービスです。
Amazon BedrockのKnowledge Bases機能の仕組みや、RAGワークフローの構築方法については、AWSの公式ガイドで詳しく解説されています。 https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/kb-how-it-works.html
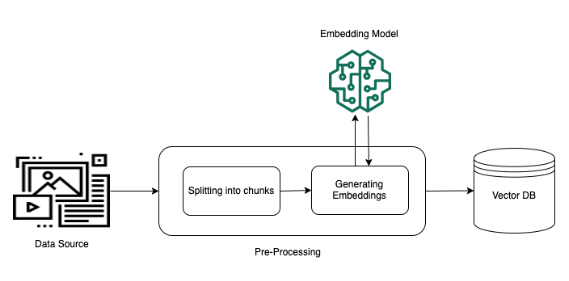
Vertex AI (Search and Conversation)
Google Cloudが提供するAI開発プラットフォームです。
Googleが長年培ってきた強力な検索技術(Google検索のセマンティック検索技術など)を、自社のデータに対して利用できるのが最大の強みです。
検索精度の高さに定評があり、特にPDFなどの非構造化データからの情報抽出能力が優れています。
GeminiなどのGoogle製高性能モデルと組み合わせることで、高品質なRAGシステムを構築できます。
Glean(企業内検索エンジン)
Gleanは、生成AI時代のために作られた企業向け検索エンジン(エンタープライズサーチ)です。
Google、Slack、Jira、Salesforceなど、社内で使っているあらゆるSaaSツールと連携し、横断的に情報を検索できます。
RAG機能が標準搭載されており、「社内の全情報を知っているAIアシスタント」として機能します。
開発不要で導入でき、検索精度の高さと使いやすいUIで、急速にシェアを伸ばしているSaaS製品です。
Dify(オープンソース開発プラットフォーム)
Difyは、生成AIアプリケーションを視覚的に作成できるオープンソースのプラットフォームです。
RAGの構築に必要な「データの分割」「ベクトル化」「検索」「プロンプト制御」といったフローを、画面上の操作だけで組み立てることができます。
エンジニアでなくても高度なRAGアプリを作れる点が評価され、個人開発から企業導入まで幅広く人気を集めています。
複数のLLMモデルを簡単に切り替えてテストできるため、PoC開発にも最適です。
自社に適したRAGの種類を選ぶ比較ポイント
これだけ多くの種類があると、結局どれを選べばいいのか迷ってしまうものです。
最適なRAGを選ぶためには、いくつかの比較軸を持って検討する必要があります。
ここでは、選定の際に重視すべき4つのポイントについて解説します。
これらの基準を社内で整理することで、迷いのない選定が可能になります。
回答精度とハルシネーション抑制の優先度
RAGを導入する業務において、どの程度の精度が求められるかを明確にしましょう。
例えば、社内FAQのような一般的な用途であれば、基本的なRAGやSaaS製品でも十分かもしれません。
しかし、契約書のチェックや医療情報の検索など、絶対に間違いが許されない業務であれば、GraphRAGやSelf-RAGのような高度な検証機能を持つアーキテクチャが必要です。
精度への要求レベルが高いほど、実装コストも高くなる傾向があるため、バランスの見極めが重要です。
社内データのセキュリティ要件と保管場所
扱うデータがどの程度の機密性を持っているかによって、選べるサービスが限定されます。
金融機関や官公庁など、データガバナンスが極めて厳しい場合は、データを外部に出さないフルスクラッチ開発や、閉域網で接続できるクラウドサービスが必須となります。
一般的な社内情報であれば、セキュリティ認定を受けたSaaS製品でも問題ない場合が多いです。
データが現在どこにあるか(オンプレミスかクラウドか)も含めて検討しましょう。
開発リソースと運用コスト(エンジニアの有無)
社内にAIに詳しいエンジニアがいるかどうかも大きな判断基準です。
エンジニアが不在の場合、メンテナンスが必要なフルスクラッチ開発やOSSの利用はリスクが高くなります。
その場合は、サポートが充実しているSaaS製品や、マネージドサービスを利用するのが現実的です。
RAGは作って終わりではなく、データ更新や精度調整などの運用が続くことを忘れてはいけません。
対応するデータ形式(PDF、Excel、画像など)
読み込ませたいデータがどのような形式で保存されているかも確認が必要です。
テキストデータだけでなく、図表を含んだPDFや、手書き文字のスキャン画像、複雑な数式が入ったExcelなどを参照させたい場合、OCR(光学文字認識)の精度やマルチモーダル対応が重要になります。
特定の製品はPDFの読み込みに強い、表形式のデータに強いといった特徴があるため、自社のデータ資産との相性を事前にテストすることをお勧めします。
RAGの種類に関わらず知っておくべき導入課題と対策
どの種類のRAGを選んだとしても、導入時に必ず直面する共通の課題があります。
これらを事前に知っておくことで、プロジェクトの失敗を防ぐことができます。
最後に、RAG導入の成功確率を高めるための対策について解説します。
回答精度の限界とファクトチェックの必要性
どんなに高度なRAGを使っても、回答精度が100%になることはありません。
最新のモデルでも、検索結果の解釈を間違えたり、微細な嘘をついたりする可能性は残ります。
そのため、RAGの回答をそのまま顧客に提示するような完全自動化は避け、必ず人間が最終確認(Human in the Loop)をするフローを設計することが重要です。
また、回答には必ず「参照元ドキュメント」へのリンクを表示させ、ユーザー自身が元データを確認できるようにするUI設計も必須です。
データクレンジング(前処理)の重要性
「Garbage In, Garbage Out(ゴミを入れればゴミが出てくる)」という言葉通り、検索対象となるデータの品質が低ければ、RAGの精度も上がりません。
古いマニュアル、重複したファイル、誤字脱字の多い議事録などが混ざっていると、AIは混乱します。
RAGを導入する前に、不要なデータを削除したり、ドキュメントのフォーマットを統一したりする「データクレンジング」の作業が、実は最も効果的な精度向上策となります。
処理速度(レイテンシ)とコストのバランス
高度なRAG手法(GraphRAGやAgentic RAGなど)を採用すると、処理が複雑になる分、回答が生成されるまでの待ち時間(レイテンシ)が長くなり、API利用コストも増加します。
ユーザーは回答に10秒以上かかるとストレスを感じて利用をやめてしまうかもしれません。
すべての質問にフルパワーで答えるのではなく、簡単な質問は即答し、複雑な質問だけ時間をかけて処理するなど、UX(ユーザー体験)とコストのバランスを考慮した設計が求められます。
RAGに関するよくある質問
RAGとファインチューニングの違いは何ですか?
RAGは「外部の辞書を引いて答える」仕組みで、ファインチューニングは「知識を脳内に暗記させる」仕組みです。
RAGはデータの更新が容易で、最新情報を反映させるのに適しており、出典の明記も可能です。
一方、ファインチューニングは特定の言い回しや専門用語を学習させるのに適していますが、知識の更新には再学習が必要でコストがかかります。
現在の主流は、知識はRAGで補い、口調や振る舞いはファインチューニングで調整するという使い分けです。
GraphRAGは従来のRAGと何が違いますか?
従来のRAGは、検索キーワードと類似した「部分」を探すのが得意ですが、全体像を把握するのは苦手です。
GraphRAGは、データ間のつながりをグラフ構造で理解しているため、「全体として何が言えるか」といった包括的な質問や、離れた情報同士の隠れた関係性を見つけ出すことができます。
特に、情報の網羅性が求められる調査業務などで、従来の手法よりも優れたパフォーマンスを発揮します。
社内Wikiやマニュアル検索に最適なRAGの種類は?
一般的な社内Wikiやマニュアル検索であれば、まずは「Hybrid Search(ハイブリッド検索)」と「Advanced RAG」の組み合わせから始めるのが最適です。
キーワード検索で用語を確実に拾いつつ、ベクトル検索で意味を汲み取れるため、多くのユースケースに対応できます。
実装ツールとしては、社内リソースが少なければ「Glean」のようなSaaS、Azure環境があれば「Azure OpenAI Service」が推奨されます。
社内文書検索に特化したChatGPTの導入メリットや具体的な事例について、こちらの記事で詳しく解説しています。 合わせてご覧ください。
あなたのRAGは「知ったかぶり」していませんか?生成AIの回答精度を劇的に変える「選び方」の真実
「RAGを導入すれば、社内データに基づいた完璧な回答が得られる」――。もしそう信じているなら、それは危険な誤解かもしれません。実は、安易なRAGの導入は、AIに嘘をつかせ、業務効率を下げる原因になりかねないのです。最新のトレンドでは、単なる検索だけでなく、AIに「自己評価」させたり、「関係性」を理解させたりする高度な手法がスタンダードになりつつあります。この記事では、失敗しないRAG選定のために知っておくべき技術の違いと、自社に最適な正解を見つけるための判断基準を解説します。
【警告】「とりあえずRAG」が招くハルシネーションの罠
最も基本的な「Naive RAG」は、検索して見つかったテキストをそのままAIに渡すだけの手法です。しかし、これには致命的な弱点があります。MITなどの研究でも指摘されるように、AIは渡された情報を鵜呑みにする傾向があるため、検索キーワードが少しズレただけで無関係な情報を拾ってしまい、AIがそれをもとに「もっともらしい嘘(ハルシネーション)」をついてしまうのです。ビジネスの現場、特に契約書やマニュアル参照などの正確性が求められる場面で、このミスは許されません。「検索したから大丈夫」という思い込みこそが、最大のリスクなのです。
引用元:
本記事は、生成AI活用におけるRAG(検索拡張生成)技術のアーキテクチャや製品種別について体系的に解説した内容(2025年時点の最新トレンド含む)を元に構成しています。
【実践】AIを「賢いエージェント」に進化させる最新アーキテクチャ
では、成功している企業はどのようなRAGを選んでいるのでしょうか。答えは「用途に合わせた高度化」です。ここでは、精度を劇的に高める注目の手法を3つ紹介します。
手法①:全体を俯瞰する「GraphRAG」
単語の一致だけでなく、情報のつながりをナレッジグラフで理解させることで、「全体的な傾向は?」といった抽象的な質問にも答えられるようになります。
手法②:取りこぼしを防ぐ「ハイブリッド検索」
キーワード検索の確実性と、ベクトル検索の文脈理解をいいとこ取りした手法です。現在の実用的なシステムのデファクトスタンダードと言えます。
手法③:自律的に動く「Agentic RAG」
AIが自らプランを立て、検索し、不足があれば再検索する。まさに優秀な社員のように振る舞う最終形であり、複雑なタスク解決に必須の技術です。
まとめ
企業は労働力不足や業務効率化の課題を抱える中で、RAGをはじめとする生成AIの活用がDX推進や業務改善の切り札として注目されています。
しかし、実際には「RAGの種類が多すぎて選べない」「社内に高度なAIリテラシーを持つ人材がいない」といった理由で、導入のハードルが高いと感じる企業も少なくありません。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
たとえば、高度なRAG技術を裏側で活用した社内ドキュメント検索や、メール作成、議事録作成、レポート自動生成など、さまざまな業務を「アプリ」として選ぶだけで、誰でも直感的にAIを活用できます。
しかも、Azure OpenAI Serviceを基盤にしているため、データセキュリティが万全で、情報漏えいの心配もありません。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「技術的な違いがよくわからない」という初心者企業でも安心してスタートできます。
導入後すぐに効果を実感できる設計なので、複雑なプログラミングや高度なAI知識がなくても、すぐに業務効率化が図れる点が大きな魅力です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最速の生成AI活用”を体験し、御社のDXを一気に加速させましょう。







