

「生成AIを導入したけれど、社内の独自データについて質問しても答えてくれない」
「回答は流暢だけど、内容に嘘や間違い(ハルシネーション)が多くて業務に使えない」
生成AI活用が進む中で、このような課題に直面している担当者の方も多いのではないでしょうか?
実は、こうした課題を解決する鍵となる技術が「RAG(検索拡張生成)」です。
本記事では、RAGの基礎知識から具体的な仕組み、ファインチューニングとの決定的な違い、そしてビジネスでの実践的な活用事例について詳しく解説しました。
上場企業をはじめ、数多くの企業へ生成AI導入・コンサルティング支援を行っている弊社の知見をもとに、専門用語を噛み砕いて説明します。
自社のAI活用を次のステージへ進めるためのヒントが詰まっていますので、ぜひ最後までご覧ください。
社内データをAIに参照させる方法について、さらに詳しく知りたい方は、こちらの記事も合わせてご覧ください。
RAG(ラグ)の基本的な意味と定義
ここでは、AI活用の現場で頻繁に耳にするようになった「RAG」という言葉の意味や定義について解説します。
RAGは、一言で表すと「外部データの検索機能を組み合わせることで、生成AIの回答精度を飛躍的に高める技術」のことです。
RAG (検索拡張生成) とは何ですか?
検索拡張生成 (RAG) は、大規模な言語モデルの出力を最適化するプロセスです。そのため、応答を生成する前に、トレーニングデータソース以外の信頼できる知識ベースを参照します。大規模言語モデル (LLM) は、膨大な量のデータに基づいてトレーニングされ、何十億ものパラメーターを使用して、質問への回答、言語の翻訳、文章の完成などのタスクのためのオリジナルの出力を生成します。RAG は、LLM の既に強力な機能を、モデルを再トレーニングすることなく、特定の分野や組織の内部ナレッジベースに拡張します。LLM のアウトプットを改善するための費用対効果の高いアプローチであるため、さまざまな状況で関連性、正確性、有用性を維持できます。
引用元:https://aws.amazon.com/jp/what-is/retrieval-augmented-generation/
なぜこの技術が注目されているのか、その背景と基本的な概念を以下の3つのポイントで掘り下げていきます。
RAG(Retrieval-Augmented Generation)の読み方と略称
RAGは「ラグ」と読みます。これは「Retrieval-Augmented Generation」の頭文字を取った略称です。
それぞれの単語を日本語に訳すと、以下のようになります。
- Retrieval:検索(情報を探し出すこと)
- Augmented:拡張(機能を強化すること)
- Generation:生成(文章を作り出すこと)
つまり、直訳すると「検索によって拡張された文章生成」という意味になります。
通常、ChatGPTなどの大規模言語モデル(LLM)は、学習済みのデータのみに基づいて回答を生成します。
しかし、RAGの技術を使うことで、AIは学習していない外部のデータベースやインターネット上の最新情報へアクセスできるようになります。
これにより、単なる文章生成にとどまらず、事実に基づいた信頼性の高い回答が可能になるのです。
一言で言うと「カンニングペーパーを持った生成AI」
RAGの仕組みを最も直感的に理解するために、「試験」に例えてみましょう。
通常の生成AI(LLM)は、「学習期間に詰め込んだ知識だけで試験を受ける優秀な学生」のようなものです。
彼らは非常に賢いですが、教科書に載っていなかったことや、学習期間終了後に起きた出来事については答えることができません。
無理に答えようとして、それらしい嘘(ハルシネーション)をつくこともあります。
一方で、RAGを搭載した生成AIは、「教科書や辞書(カンニングペーパー)を持ち込んで試験を受ける学生」です。
質問されるたびに手元の資料をパラパラとめくり、該当するページを探し出し、その内容を読みながら回答を作成します。
自身の記憶だけに頼るのではなく、確かな参照元を確認しながら答えるため、回答の正確性が格段に向上するのです。
特に、世の中には出回っていない「社内マニュアル」や「独自の日報データ」などをカンニングペーパーとして渡すことで、その企業独自の質問にも答えられるようになります。
LLM(大規模言語モデル)とRAGの関係性
LLMとRAGは対立するものではなく、補完し合う関係にあります。
LLMは、文章を理解し、自然な言葉で組み立てる「脳」の役割を果たします。
一方、RAGは、その脳に対して必要な知識を都度提供する「外部記憶装置」や「検索エンジン」の役割を担います。
2025年にリリースされたGPT-5のような最新のLLMは、以前のモデルに比べて推論能力や知識量が大幅に向上しています。
しかし、どれほど優秀なモデルであっても、世界中の全ての最新情報や、特定の企業内に閉じた機密情報をあらかじめ知っているわけではありません。また、GPT-5などの最新モデルは一度に読める情報量が増えましたが、膨大な全データを毎回読み込ませるとコストと回答時間が肥大化するため、RAGによる効率的な抽出が不可欠です。
そのため、LLMが持っている「言葉を操る能力」と、RAGによる「正確な情報の検索能力」を組み合わせることが、ビジネス活用において最適解となるのです。
LLM単体では「汎用的な賢さ」を提供し、RAGと組み合わせることで「専門的かつ特化した賢さ」を実現できると言えるでしょう。
こちらはRAG(検索拡張生成)が提唱された原典となる論文です。知識集約型のタスクにおいて外部知識の検索がいかに有効であるかが示されています。 合わせてご覧ください。 https://arxiv.org/abs/2005.11401
RAGの仕組み・構成をわかりやすく解説
RAGがどのような手順で回答を生成しているのか、その裏側の仕組みについて詳しく見ていきましょう。
ユーザーが質問を投げかけてから回答が返ってくるまでの間、AI内部では複数のプロセスが高速で行われています。
このプロセスを理解することで、なぜRAGが正確な回答を出せるのか、その理由がより明確になります。
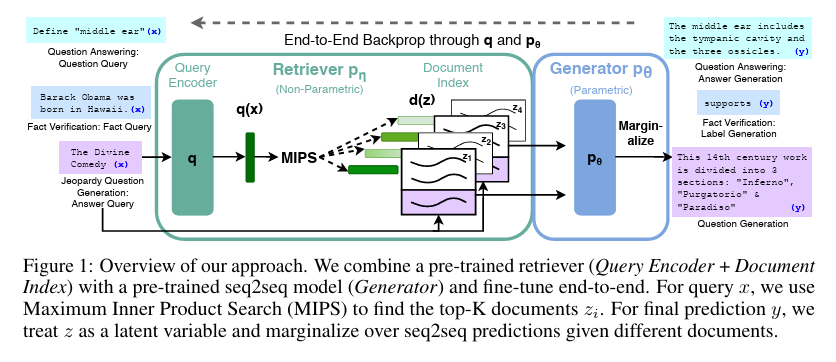
RAGの基本的な動作プロセス(検索・拡張・生成)
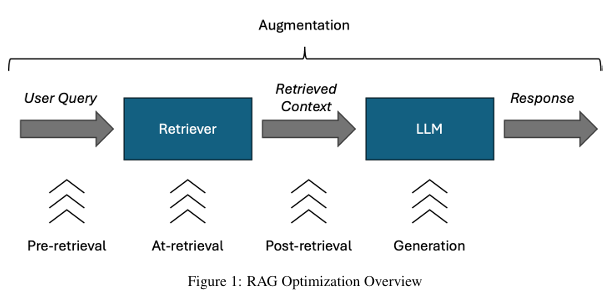
RAGの動作は、大きく分けて「Retrieval(検索)」「Augmentation(拡張)」「Generation(生成)」の3つのステップで構成されています。
ユーザーが質問を入力すると、システムはまずその質問に関連する情報をデータベースから探し出します。
次に、見つけ出した情報をユーザーの質問文に付け加えて、AIへの指示(プロンプト)を書き換えます。
最後に、その情報が補強された指示文をLLMに渡し、回答を生成させます。
この一連の流れは瞬時に行われるため、ユーザーから見ると、AIが即座に知識を呼び出して答えているように見えます。
しかし実際には、AIが回答を作成する前に「情報の調査」と「プロンプトの修正」という重要な工程が挟み込まれているのです。
それぞれのステップについて、さらに詳しく解説します。
検索(Retrieval):関連情報の抽出
最初のステップは「検索」です。
ユーザーからの質問文を受け取ると、システムはあらかじめ用意されたデータベース(社内ドキュメントなどを保存した場所)の中から、その質問に関連性が高い文章を抽出します。
この時、単にキーワードが一致するかどうかだけでなく、「意味合い」が近いかどうかを判断する「ベクトル検索」や、従来のキーワード検索を組み合わせた「ハイブリッド検索」という技術が多く用いられます。
例えば、「PCの調子が悪い」という質問に対し、「パソコン」「不具合」「故障」といったキーワードが含まれるマニュアルを、言葉の揺らぎを吸収して探し出すことができます。
この検索プロセスの精度が高ければ高いほど、後の工程でAIに渡される情報の質が良くなり、結果として回答の品質も向上します。
逆に、ここで的外れな情報を拾ってしまうと、AIは間違った情報を元に回答を作成してしまうことになります。
こちらはRAGの検索精度を支えるDPR技術について解説した論文です。従来の検索手法と比較して回答精度が向上することが実証されています。 合わせてご覧ください。 https://arxiv.org/abs/2004.04906

拡張(Augmentation):プロンプトの補強
次のステップは「拡張」です。
ここでは、ユーザーの質問文と、検索ステップで見つけ出した参考情報を合体させます。
具体的には、LLMに対して以下のような指示(プロンプト)を裏側で作成します。
「以下の【参考情報】に基づいて、ユーザーの【質問】に答えてください。
【質問】:PCの画面が青くなった
【参考情報】:PC画面が青くなる場合は、ブルースクリーンエラーの可能性があります。まずは再起動を試みてください。
回答:」
このように、AIに対して「何を知っているか」を問うのではなく、「与えられた情報をどうまとめるか」というタスクに変換するのです。
これによって、AIは自身の学習データにある古い記憶ではなく、今渡されたばかりの確実な情報を優先して処理するようになります。
生成(Generation):回答の出力
最後のステップが「生成」です。
拡張されたプロンプトを受け取ったLLMは、その内容をもとに自然な文章で回答を生成し、ユーザーに提示します。
この段階でのLLMの役割は、情報を新しく作り出すことではありません。
渡された参考情報を読みやすく要約したり、質問の意図に合わせて文体を整えたりすることが主な役割です。
例えば、参考情報が箇条書きのマニュアルであっても、LLMの文章作成能力によって「まずは再起動をお試しください。それでも改善しない場合は…」といった、人間味のある丁寧なサポート文章に変換されます。
このように、検索(事実の収集)と生成(文章の構成)の役割を分担することで、RAGは事実に基づいた流暢な回答を実現しているのです。
生成AIにRAGが必要とされる理由と解決できる課題
なぜ、ChatGPTなどの生成AI単体ではなく、わざわざRAGというシステムを構築する必要があるのでしょうか。
それは、標準的なLLMが抱えているいくつかの構造的な弱点を、RAGが効果的に補うことができるからです。
ここでは、RAGを導入することで解決できる具体的な課題と、その必要性について解説します。
情報の「古さ」と「学習していないデータ」への対応
LLMには必ず「学習データのカットオフ(情報の期限)」が存在します。
AIモデルの学習には膨大な時間とコストがかかるため、学習完了後に起きた最新のニュースや出来事については知識を持っていません。
例えば、昨日発表されたばかりの競合他社のプレスリリースや、今朝変更されたばかりの社内規定について質問しても、通常のLLMは答えることができません。
RAGを使用すれば、AIモデル自体を再学習させることなく、外部のデータベースを更新するだけで最新情報に対応できます。
ニュース記事や社内ドキュメントをデータベースに追加すれば、その瞬間からAIはその情報を参照して回答できるようになります。
ビジネスの現場では情報は常に変化するため、この即時性は非常に重要な要素となります。
ハルシネーション(もっともらしい嘘)の抑制
生成AIの最大のリスクの一つに「ハルシネーション」があります。
これは、AIが事実ではないことを、あたかも真実であるかのように自信満々に語ってしまう現象です。
AIは確率的に「次に来るもっともらしい単語」をつなげているだけなので、事実確認の機能を持っていません。
そのため、架空の人物の経歴をでっち上げたり、存在しない法律を解説したりすることがあります。
RAGを導入することで、回答の根拠となる情報をAIに強制的に与えることができます。
「この資料に書いてあることだけを使って答えて」という制約をかけることで、AIが勝手に情報を創作する余地を減らし、事実に基づいた回答を行わせることが可能になります。
特に正確性が求められる業務においては、このハルシネーション対策は必須と言えます。
こちらはRAGとファインチューニングの精度比較を行い、ハルシネーション抑制効果について分析した研究論文です。 合わせてご覧ください。 https://arxiv.org/abs/2403.01432
機密情報・社内データのセキュリティ確保
企業が生成AIを利用する際、最も懸念されるのが情報漏洩のリスクです。
一般的なクラウド型の生成AIサービスに社内の機密データを直接入力して学習させてしまうと、その情報が他のユーザーへの回答として出力されてしまうリスクがゼロではありません。
RAGの仕組みでは、社内データは自社の管理下にあるデータベースに保存され、検索時に必要な部分だけが一時的にAIへ送られます。
また、「ChatSense」のような法人向けサービスや、セキュアなAPI環境を通じて利用することで、入力データがAIモデルの学習(再学習)に使われない設定にすることができます。
これにより、AIモデル自体には機密情報を覚え込ませることなく、安全な環境で自社データに基づいた回答を得ることができるようになります。
こちらはRAGシステム特有のセキュリティリスクや、プロンプトインジェクション攻撃への対策について論じた研究論文です。 合わせてご覧ください。 https://arxiv.org/abs/2511.15759
【比較】RAGとファインチューニングの違い
RAGとよく比較される手法に「ファインチューニング」があります。
どちらもAIを自社向けにカスタマイズする技術ですが、そのアプローチと得意分野は全く異なります。
どちらを採用すべきか迷わないために、両者の違いを明確に理解しておきましょう。
生成AIを企業で導入する際の具体的な手順やロードマップについては、こちらの完全ガイドをご覧ください。
以下の3つの視点から比較解説します。
学習コストと即時性の違い
ファインチューニングは、AIモデル自体に追加の学習を行わせ、脳の構造そのものを微調整する手法です。
これには、質の高い大量の学習データの準備と、GPUなどの計算リソースが必要となり、多大なコストと時間がかかります。
また、一度学習させると、情報を更新するためには再度学習をやり直す必要があります。
一方、RAGはモデル自体には手を加えません。
外部のデータベースを参照するだけなので、新しいマニュアルができたらそのファイルを保存するだけで情報の更新が完了します。
コストも安価で済み、情報の鮮度を常に最新に保つことができる即時性が強みです。
「試験勉強(ファインチューニング)」と「カンニング(RAG)」の例で言えば、試験範囲が変わるたびに猛勉強し直すのがファインチューニング、新しい教科書を買ってくるだけで済むのがRAGです。
こちらはリソース制約環境下におけるRAGとファインチューニングのコスト対効果を分析した論文です。導入検討時の参考資料としてご活用ください。 https://arxiv.org/abs/2509.10469
回答の正確性と根拠の透明性
ファインチューニングを行ったとしても、ハルシネーションを完全に防ぐことは困難です。
学習した知識が記憶の中で混ざり合い、誤った結びつきで回答される可能性があるからです。
また、AIが「なぜその回答をしたのか」という参照元を示すことは苦手です。
対してRAGは、検索した具体的なドキュメントに基づいて回答を生成します。
そのため、「この回答は社内規定マニュアルの〇ページの記述に基づいています」というように、情報の出所(引用元)を明確に提示することが可能です。
ビジネス文書や顧客対応など、エビデンス(根拠)が重要視される場面では、参照元を確認できるRAGの方が信頼性を担保しやすいと言えます。
どちらを選ぶべきかの判断基準
では、具体的にどちらを選べばよいのでしょうか。以下の基準を参考にしてください。
RAGを選ぶべきケース:
- 「社内規定」「製品マニュアル」「日報」など、具体的な事実に即した回答が必要な場合
- 情報の更新頻度が高く、常に最新情報を反映させたい場合
- 回答の根拠を明示させたい場合
- 低コストで導入を始めたい場合
ファインチューニングを選ぶべきケース:
- 特定の業界用語や特殊な言い回し、自社ブランドの口調(トーン&マナー)を習得させたい場合
- プログラミングコードの生成や、特殊な形式のデータ出力など、新しい「スキル」を身につけさせたい場合
- 参照すべき外部データが存在せず、モデルの振る舞い自体を変えたい場合
多くの企業における「社内FAQ」や「ドキュメント検索」といった用途では、RAGの方が適しているケースがほとんどです。
RAGを導入するメリット・デメリット
RAGは非常に強力な技術ですが、万能ではありません。
導入を検討する際は、メリットだけでなくデメリットやリスクも把握しておくことが大切です。
ここでは、RAG導入におけるプラス面とマイナス面を整理して解説します。
メリット:最新情報に基づいた高精度な回答
最大のメリットは、やはり情報の鮮度と正確さです。
モデルの再学習を待つことなく、データベースにファイルをアップロードするだけで、AIは瞬時にその新しい知識を活用できるようになります。
日々の業務連絡、週次で変わる在庫情報、頻繁に改定される法規制など、情報の変化が激しいビジネス環境において、リアルタイムで情報が反映されるメリットは計り知れません。
これにより、従業員は常に最新の正しい情報に基づいて判断を下すことができるようになります。
メリット:根拠(参照元)が提示できる透明性
RAGシステムは、回答とともに「参照したドキュメントへのリンク」を表示するように設計できます。
ユーザーはAIの回答を鵜呑みにすることなく、気になった場合はワンクリックで元の資料を確認し、詳細をチェックすることができます。
これは「AIが勝手に言っていること」から「確かな資料に基づいた要約」へと、情報の信頼レベルを引き上げることにつながります。
特に責任の所在が問われる業務においては、この透明性が安心材料となります。
デメリット:構築・運用の手間とコスト
RAGを導入するには、単にChatGPTを契約するだけでは済みません。
社内ドキュメントを検索可能な形式(ベクトルデータ)に変換し、それを保存・管理する「ベクトルデータベース」を構築する必要があります。
また、システムを動かすためのサーバー費用や、検索システムの利用料などがランニングコストとして発生します。
導入初期には、社内のバラバラなデータを整理・整形する作業も発生するため、一定の人的リソースと技術的な知見が必要になります。
デメリット:検索精度が回答の品質に直結する
RAGの回答品質は、LLMの性能だけでなく「検索システムの性能」に大きく依存します。
もし検索システムが、ユーザーの質問とは無関係なドキュメントを抽出してしまった場合、いくらLLMが優秀でも、間違った参考情報を元に回答を作成してしまいます。
これを防ぐためには、ドキュメントの前処理(適切な長さに分割するなど)を工夫したり、検索アルゴリズムを調整したりするチューニング作業が必要です。
「ゴミを入れればゴミが出てくる(Garbage In, Garbage Out)」という原則は、RAGにおいてより顕著に現れます。
ビジネスにおけるRAGの活用事例
理論的な解説だけでなく、実際にビジネスの現場でRAGがどのように使われているのかを見ていきましょう。
多くの企業ですでに導入が進んでおり、業務効率化の成果が報告されています。
ここでは代表的な3つの活用シーンを紹介します。
社内ナレッジ検索・ヘルプデスクの自動化
最もポピュラーな活用事例が、社内問い合わせ対応の自動化です。
総務、人事、IT部門などには、毎日多くの社員から似たような質問が寄せられています。
「経費精算のやり方は?」「VPNがつながらない時は?」といった質問に対し、RAGチャットボットが社内マニュアルや過去のQ&A集から回答を検索し、即座に返信します。
これにより、管理部門の担当者は問い合わせ対応に追われる時間が減り、本来のコア業務に集中できるようになります。
また、質問する側の社員も、担当者の返信を待つことなく24時間365日いつでも疑問を解決できるため、業務スピードが向上します。
こちらはLINEヤフー社の社内RAG「SeekAI」における回答品質評価フローや独自指標について解説された技術ブログです。 合わせてご覧ください。 https://techblog.lycorp.co.jp/ja/20240819a
マニュアルや契約書に基づいた回答生成
製造業や建設業などの現場では、膨大な技術マニュアルや仕様書が存在します。
RAGを活用することで、現場の作業員がタブレット端末で「このエラーコードが出た時の対処法は?」と入力するだけで、該当するマニュアルのページを探し出し、対処手順を要約して提示することが可能になります。
また、法務部門においては、過去の膨大な契約書データから「秘密保持契約の損害賠償条項について、過去の事例ではどうなっていたか」を抽出・比較するといった使い方もされています。
大量の文書を読み込む時間を大幅に短縮し、ヒューマンエラーを防ぐ効果が期待できます。
カスタマーサポートの品質向上
顧客向けのカスタマーサポート(CS)においてもRAGは活躍します。
オペレーターが電話対応中に、顧客からの質問内容をシステムに入力すると、RAGが即座に製品仕様書やトラブルシューティングガイドから最適な回答候補を画面に表示します。
これにより、新人オペレーターでもベテランと同じレベルの正確な案内ができるようになり、対応品質の均一化が図れます。
また、顧客を保留にして資料を探す時間が短縮されるため、顧客満足度の向上にもつながります。
RAGの導入・構築手順の概要
最後に、自社でRAGシステムを導入しようと考えた際、どのような手順で進めることになるのか、その概要を解説します。
技術的な詳細は専門のエンジニアやベンダーに依頼することになりますが、全体の流れを把握しておくことは重要です。
ドキュメントの準備とベクトル化
まずは「AIに参照させたいデータ」を準備します。
PDF、Word、Excel、PowerPoint、テキストファイルなど、社内に散らばっている資料を集約します。
重要なのは、これらのデータをAIが理解しやすい形に加工することです。
具体的には、長い文章を適切な長さ(チャンク)に分割し、それぞれの文章を「ベクトル(数値の羅列)」に変換します。
このベクトル化によって、コンピュータは文章の意味を数学的な距離として計算できるようになり、「意味が近い文章」を探せるようになります。
ベクトルデータベースの構築
ベクトル化したデータを保存するための専用のデータベースを用意します。
Pinecone、Weaviate、Chromaなどが有名ですが、AzureやAWSなどのクラウドサービスが提供している検索機能を利用することも可能です。
このデータベースは、単にデータを保存するだけでなく、ユーザーからの質問(これもベクトル化されます)と最も近いベクトルを持つデータを高速に検索・抽出する機能を備えています。
LangChainなどのフレームワーク活用
LLM、ベクトルデータベース、そしてユーザーインターフェースをつなぎ合わせるために、「LangChain(ラングチェーン)」や「LlamaIndex(ラマインデックス)」といった開発フレームワークを利用するのが一般的です。
これらのツールを使うことで、基本的なRAGの処理フローや、AIが自律的に検索と判断を繰り返す「エージェント型RAG」の仕組みを効率的にプログラムすることができます。
最近では、これらの機能がパッケージ化されたノーコード/ローコードツールも増えており、専門知識がなくてもRAGを構築できる環境が整いつつあります。
RAGに関するよくある質問
RAGはどのような企業におすすめですか?
独自の業務マニュアルや社内規定、技術文書など、社内に蓄積されたドキュメント資産が多い企業に特におすすめです。また、情報の更新頻度が高く、常に最新の情報を参照して業務を行う必要がある業種(金融、医療、ITサポートなど)でも高い効果を発揮します。
情報漏洩のリスクはありませんか?
RAGの仕組み自体は、外部のパブリックなChatGPT等にデータを学習させるわけではないため、比較的安全です。しかし、社内データをクラウド上のベクトルデータベースに保存する際や、APIを通じてLLMにデータを送信する際のセキュリティ対策は必須です。エンタープライズ向けのセキュアなサービスを選定し、アクセス権限の管理を適切に行うことで、リスクを最小限に抑えることができます。
その生成AI、本当に「自社データ」を理解していますか?ハルシネーションを防ぐRAGの仕組み
生成AIを業務に導入したものの、「もっともらしい嘘をつく」「最新の社内規定を反映してくれない」といった課題に直面していませんか。実は、ChatGPTなどの大規模言語モデル(LLM)単体では、企業の固有データやリアルタイムの情報を正確に扱うことは困難です。そこで現在、ビジネス活用の標準となりつつある技術が「RAG(検索拡張生成)」です。この記事では、AIに「カンニングペーパー」を持たせ、回答精度を飛躍的に高めるRAGのメカニズムと、ファインチューニングとの決定的な違いについて、専門的な知見をもとに解説します。
なぜAIは嘘をつくのか?RAGが「カンニングペーパー」と呼ばれる理由
通常の生成AIは、過去に学習した膨大なデータのみを頼りに回答を作成します。これは、試験会場に「自分の頭の中にある知識だけ」で挑む受験生のようなものです。そのため、記憶していないこと(社内の未公開情報や最新ニュース)を聞かれると、無理やり答えを創作してしまい、結果として「ハルシネーション(幻覚)」と呼ばれる嘘の回答が生まれます。
一方、RAGを搭載したAIは、「教科書や参考書の持ち込みが許可された受験生」です。質問されるたびに、手元にある信頼できる外部データ(社内マニュアルやデータベース)をパラパラとめくり、該当するページを探し出して回答を生成します。記憶に頼らず、確かな資料を見ながら答えるため、事実に基づいた正確なアウトプットが可能になるのです。
ファインチューニングとの違い:コストと即時性での勝敗
「AIを賢くするなら、追加学習(ファインチューニング)が良いのでは?」と考える方も多いですが、ビジネスの現場ではRAGの方が適しているケースが大半です。
ファインチューニングは、AIの「脳」そのものを再教育する手法であり、膨大なコストと計算リソースが必要です。また、情報が更新されるたびに再学習が必要になるため、日次で変わる在庫情報や規定変更に対応するには不向きです。
対してRAGは、参照する「マニュアル(外部データ)」を差し替えるだけで情報の更新が完了します。
正確な根拠の提示が必要な場合:RAG(参照元を示せるため)
特定の口調や専門スキルを習得させたい場合:ファインチューニング
このように目的を切り分けることが、AI導入成功の鍵となります。
引用元:
Lewis, P., et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” (2020) において、外部知識の検索を生成プロセスに統合することで、知識集約型タスクにおける性能が大幅に向上することが示されています。また、最新のLLM活用事例に基づき、RAGがハルシネーション低減に寄与する点は広く実証されています。
まとめ
生成AIの活用において、RAGは回答の正確性と情報の鮮度を担保するために不可欠な技術です。しかし、自社でRAG環境を構築するには、ベクトルデータベースの整備やセキュリティ対策、検索精度のチューニングなど、技術的なハードルが決して低くありません。
「社内データと連携させたいが、開発リソースがない」「セキュリティ面で不安がある」という企業担当者様も多いのではないでしょうか。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
複雑なRAG構築を一から行う必要はなく、必要な機能を「アプリ」として選ぶだけで、直感的に業務へ導入できます。
メール作成や議事録作成はもちろん、社内固有のナレッジ活用もスムーズに行えるよう設計されています。
しかも、Azure OpenAI Serviceを基盤にしているため、金融機関レベルのデータセキュリティが確保されており、機密情報漏えいの心配もありません。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「どのデータから連携させればいいかわからない」という企業でも安心してスタートできます。
高度なエンジニアリングなしで、安全かつ最速で自社データをAIに活用させたいなら、これ以上の選択肢はありません。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“失敗しない生成AI導入”を実現し、御社のDXを確実なものにしましょう。







