
「GPT-5などの高性能AIは登場したけれど、API利用料や従量課金のコストが気になって手が出ない…。」
「Pythonの学習を進めていて、実用的な文字認識システムを自分の手で作ってみたい。」
現場でこのような悩みを抱えているエンジニアや担当者の方も多いのではないでしょうか?
本記事では、世界中で利用されているオープンソースエンジン「Tesseract」とPythonを活用し、実際にOCRシステムを自作するための具体的な手順とコード例を解説します。
数多くのAI開発や業務システム構築を手掛けてきた弊社が、現場で培ったノウハウをもとに、精度の高いOCRを作るためのポイントをご紹介します。
読み終わる頃には、あなた自身の環境で文字認識を実行できるようになっているはずです。ぜひ最後までご覧ください。
OCRを自作する前に知っておきたい2つのアプローチ
OCR(光学文字認識)システムを自作するといっても、ゼロから文字の形をプログラムに教え込むわけではありません。
現代の開発においては、大きく分けて2つのアプローチが存在します。
開発にかけられる時間や求められる精度、そして現在の技術レベルに合わせて最適な方法を選ぶことが、プロジェクトを成功させるための第一歩となります。
ここでは、それぞれの特徴とメリット・デメリットについて詳しく見ていきましょう。
手軽さ重視なら「既存ライブラリ(Tesseract)」の活用
OCRを自作する際に最も一般的で、かつ手軽に始められるのが既存のOCRエンジンを利用する方法です。
中でもGoogleが開発を支援している「Tesseract OCR」は、オープンソースでありながら非常に高い認識精度を誇ります。
すでに世界中の膨大な文字データをもとに学習済みのモデルが提供されているため、開発者が一からAIに文字を学習させる必要がありません。
Pythonなどのプログラミング言語からこのエンジンを呼び出すだけで、画像に含まれるテキストを即座に抽出することが可能です。
日本語を含む多言語に対応しており、縦書きや横書きの指定もオプション一つで切り替えられます。
環境構築も比較的容易で、インストールしてから数行のコードを書くだけで動作確認まで進めることができるでしょう。
まずは基本的な機能を実装したい、すぐに動くものが欲しいという場合には、このアプローチが最適です。
ただし、手書き文字や極端に崩れたフォント、複雑なレイアウトの読み取りには限界があるため、その点は後述する前処理などで補う工夫が必要になります。
まずはTesseractでベースを作り、必要に応じてカスタマイズしていくのが王道の進め方です。
精度・カスタマイズ重視なら「ディープラーニング・VLM(AI学習)」
既存のライブラリでは読み取れない特殊な文字や、特定の帳票フォーマットに特化させたい場合には、ディープラーニングを用いて独自のモデルを作成するアプローチが必要です。
これは「OCRエンジンそのもの」を自作するイメージに近く、KerasやPyTorch、あるいは最新のTransformerモデル(VLM)を使用します。
この方法の最大のメリットは、学習データさえ用意できれば、どのような文字でも認識できるようになる可能性を秘めている点です。
例えば、自社特有の記号や、業界独自の特殊フォント、あるいは特定の人が書いた癖のある手書き文字なども、大量の画像データとしてAIに学習させることで認識が可能になります。
一方で、開発難易度は格段に上がります。
モデルの構造設計やパラメータの調整に関する専門知識が必要となるだけでなく、学習用データの収集とアノテーション(正解ラベル付け)に膨大な手間がかかるからです。
高性能なGPUを搭載したマシンも必要になるでしょう。
しかし、その苦労に見合うだけの強力なカスタマイズ性が手に入ります。
汎用的なOCRではどうしても誤認識してしまう箇所をピンポイントで改善したい場合や、製品として独自の強みを持たせたい場合には、この道を選ぶ価値が十分にあります。
大規模言語モデル(LLM)とは何か、ChatGPTとの違いについて詳しく解説しています。 合わせてご覧ください。
【Python編】Tesseract OCRを使ってOCRを自作する手順
ここからは、実際にPythonとTesseractを使ってOCRシステムを構築する手順を解説します。
プログラミング初心者の方でも流れを掴めるよう、環境構築からコードの実装までをステップバイステップで説明していきます。
動くものが手に入れば、そこから工夫して自分好みのツールに改良していく楽しみも生まれるはずです。
まずは基本的な文字認識ができる状態を目指して、手を動かしていきましょう。
開発環境の準備とTesseractエンジンのインストール
OCR開発を始めるには、まず文字認識の頭脳となる「Tesseract OCRエンジン」本体をPCにインストールする必要があります。
Pythonのライブラリを入れるだけでは動作しないため注意が必要です。
Windowsの場合は、GitHubなどの公式サイトからインストーラー(.exeファイル)をダウンロードして実行します。
インストール時には、言語データとして「Japanese(日本語)」を選択することを忘れないでください。これがないと日本語の認識ができません。
Macの場合は、Homebrewを使用すればコマンド一つで簡単にインストールが完了します。
Linux環境でもパッケージマネージャー経由で導入可能です。
インストールが完了したら、システム環境変数のPathにTesseractのインストールフォルダを追加します。
これにより、コマンドプロンプトやターミナル上のどこからでもTesseractを呼び出せるようになります。
正しくインストールされたかを確認するには、ターミナルでバージョン確認コマンドを打ってみましょう。
バージョン情報が表示されれば、エンジンの準備は完了です。
このエンジンが裏側で画像の解析を行い、テキストデータを返してくれる仕組みになっています。
地味な作業ですが、ここが正しく設定されていないと後のPythonコードが動かないため、確実に行いましょう。
こちらのTesseract公式リポジトリから最新のソースコードやドキュメントを確認できます。 https://github.com/tesseract-ocr/tesseract
Pythonライブラリ(pytesseract・Pillow)のセットアップ
エンジン本体の準備ができたら、次はPythonからそれを操作するためのライブラリをインストールします。
主に必要となるのは「pytesseract」と「Pillow(PIL)」の2つです。
pytesseractは、先ほどインストールしたTesseractエンジンとPythonプログラムの橋渡し役を担うラッパーライブラリです。
これを使うことで、複雑なコマンドライン引数を意識することなく、Pythonの関数としてシンプルにOCR機能を呼び出せます。
Pillowは画像処理ライブラリで、画像を読み込んだり、加工したりするために使用します。
インストールはPythonのパッケージ管理ツールであるpipを使えば一瞬で終わります。
コマンドラインでインストールコマンドを実行してください。
環境によっては、OpenCVなどの追加ライブラリも入れておくと、後の画像前処理で役立ちます。
インストール後は、Pythonのコード内でこれらのライブラリをインポートし、Tesseractの実行ファイル(tesseract.exe)のパスを指定する設定記述を行います。
特にWindows環境では、このパス指定を省略するとエラーになることが多いので、コードの冒頭で明示的に記述する癖をつけておくとトラブルを回避できます。
これで、Pythonを使って画像を読み込み、文字を認識させるための道具がすべて揃いました。
画像を読み込んで文字認識させる基本コードの実装
準備が整ったところで、実際に画像を読み込んで文字化するコードを書いてみましょう。
処理の流れは非常にシンプルです。
まずPillowを使って対象の画像ファイルを開きます。
次に、その画像オブジェクトをpytesseractの「image_to_string」という関数に渡します。
この時、引数として言語設定に「jpn(日本語)」を指定します。
たったこれだけの処理で、画像内の文字がテキストデータとして返ってきます。
出力されたテキストは、標準出力(print)で画面に表示させても良いですし、テキストファイルとして保存することも可能です。
実際に試してみると、活字のドキュメントやスクリーンショットなどは驚くほど高い精度で認識されることがわかります。
一方で、背景が複雑な画像や、文字が小さい画像では認識ミスが起こることも確認できるでしょう。
この基本コードが、すべての自作OCRツールの土台となります。
ここから「画像内の特定のエリアだけを読み取る」「数字だけを抽出するように設定を変える」といった応用を加えることで、実務で使えるツールへと進化させていくのです。
まずは手持ちのレシートや書類の画像を読み込ませて、AIがどのように文字を見ているのか体感してみてください。
PDFファイルを画像化してテキストを抽出する方法
実務においては、画像ファイル(JPGやPNG)だけでなく、PDF化されたスキャンデータをOCR処理したい場面も多々あります。
しかし、Tesseractは直接PDFを読み込むことが苦手です。
そのため、一度PDFを画像形式に変換してからOCRにかけるという手順を踏むのが一般的です。
Pythonには「pdf2image」という便利なライブラリがあり、これを使うとPDFの各ページを個別の画像ファイルとしてリスト化できます。
処理の流れとしては、まずPDFファイルを読み込み、全ページを画像オブジェクトに変換します。
その後、forループなどの繰り返し処理を使って、1ページずつ順番にpytesseractへ渡して文字認識を行います。
複数ページにわたる書類でも、この方法なら一括でテキスト化することが可能です。
注意点として、pdf2imageを動かすためには「Poppler」という外部ツールが必要になる場合があります。
これも事前にインストールし、パスを通しておく必要があります。
PDF対応ができるようになれば、過去の紙資料をスキャンした膨大なアーカイブを一気にデータ化して検索可能にするなど、業務効率化の幅が大きく広がります。
大量のファイルを処理する場合は、処理状況がわかるようにプログレスバーを表示させるなどの工夫をすると、ツールとしての完成度が高まります。
DXによる業務効率化を推進するための具体的な進め方や成功事例については、こちらの記事で詳しく解説しています。 合わせてご覧ください。
自作OCRの認識精度を劇的に上げる「画像前処理」のテクニック
OCRエンジンに画像をそのまま渡しても、期待通りの精度が出ないことは珍しくありません。
特にスキャン時の汚れ、影、傾きなどは認識率を大きく下げる原因となります。
そこで重要になるのが、AIが文字を読み取りやすいように画像を加工する「前処理」です。
ここでは、OpenCVなどを用いて認識精度を劇的に向上させるための具体的なテクニックを解説します。
なぜ前処理が重要なのか?OpenCVを使ったノイズ除去
OCRエンジンは、画像内の明暗の差を手がかりに文字の輪郭を特定しています。
そのため、紙の裏写りやスキャナーのガラス面の汚れによるノイズ(黒い点など)があると、それを文字の一部や濁点と誤認してしまうことがあります。
これを防ぐために行うのがノイズ除去です。
Pythonの画像処理ライブラリであるOpenCVを使えば、高度なフィルタリング処理を簡単に実装できます。
例えば「ガウシアンフィルタ」や「メディアンフィルタ」といった平滑化処理を適用することで、文字の輪郭を残しつつ、背景の細かいザラつきやノイズだけをぼかして消すことができます。
人間が見ても「画像が少しぼやけたかな?」と感じる程度でも、コンピュータにとっては余計な情報が減り、文字の構造が明確になるため、認識精度が向上します。
特に、古い書類やFAXで送られてきた画質の粗い文書を扱う場合、このノイズ除去処理を入れるか入れないかで、結果に雲泥の差が出ます。
前処理は、料理における下ごしらえのようなものです。
素材を整えることで、メインの処理であるOCRエンジンのパフォーマンスを最大限に引き出すことができるのです。
画像の二値化(白黒化)で文字をくっきりさせる
カラーやグレーの画像には、文字と背景の間に無数の中間色が存在します。
これが文字の境界をあいまいにさせ、誤認識の一因となります。
そこで有効なのが、画像を完全に白と黒の2色だけにする「二値化(Thresholding)」という処理です。
ある一定の明るさを基準(閾値)にして、それより明るい画素は白、暗い画素は黒に強制的に変換します。
OpenCVには、画像全体の明るさ分布を自動的に解析し、最適な閾値を計算してくれる「大津の二値化」というアルゴリズムが実装されています。
これを使えば、照明条件が悪く全体的に暗い画像や、影が落ちている画像でも、背景を真っ白に、文字を真っ黒に分離することができます。
文字のコントラストが極限まで高まるため、Tesseractなどのエンジンが文字の形状を捉えやすくなります。
ただし、閾値の設定によっては文字の一部が欠けてしまったり、逆に太くなりすぎて潰れてしまったりすることもあります。
状況に応じて、近傍の画素との差分で閾値を決める「適応的二値化」を使い分けるなど、対象画像に合わせた調整を行うことが精度アップの鍵となります。
OpenCVを用いた画像の閾値処理(Thresholding)の技術的な詳細については、公式ドキュメントが参考になります。 https://docs.opencv.org/4.x/d7/d4d/tutorial_py_thresholding.html

文字の傾き補正(スキュー補正)で認識率を高める
スキャナーで書類を取り込む際や、スマホで撮影する際、どうしても画像が微妙に傾いてしまうことがあります。
人間なら少々の傾きは脳内で補正して読めますが、OCRエンジンにとって斜めになった文字は認識難易度が跳ね上がります。
行の並びを正しく認識できず、文章の順序がめちゃくちゃになったり、文字そのものを誤読したりする原因になります。
これを解決するのが傾き補正(スキュー補正)です。
プログラムで画像内の直線を検出したり、文字の並びの角度を解析したりして、画像全体を逆方向に回転させて水平に戻します。
具体的には、OpenCVで画像の輪郭を抽出し、テキストブロックの外接矩形の角度を計算して補正量を算出する手法などが用いられます。
また、Tesseract自体にもページの傾きを推定する機能が含まれていますが、事前に画像処理レベルで水平にしておく方が、より確実な結果が得られます。
ほんの1度や2度の傾きを直すだけで、認識不能だった行があっさり読み取れるようになるケースも多々あります。
自動化システムを組む場合は、この傾き補正処理をパイプラインに組み込んでおくことを強く推奨します。
ハフ変換を用いて直線を検出する技術仕様については、こちらのドキュメントをご覧ください。 https://docs.opencv.org/3.4/d9/db0/tutorial_hough_lines.html
読み取り範囲(ROI)を指定して不要な情報をカットする
請求書や身分証明書のように、フォーマットが決まっている書類をOCRにかける場合、画像全体を読み込ませる必要はありません。
むしろ、ロゴマークや装飾、不要な注釈文などが含まれていると、それがノイズとなって目的のデータの抽出を妨げることがあります。
そこで、読み取りたい情報(日付、金額、名前など)が記載されている箇所だけを座標で指定して切り抜く処理を行います。
これをROI(Region of Interest:関心領域)の設定と呼びます。
Pythonでは、画像の配列データをスライス操作するだけで簡単にトリミングが可能です。
事前に「日付は右上のこの辺り」「金額は下部のこのエリア」といった座標情報を定義しておき、その部分だけを切り出した小さな画像をOCRエンジンに渡します。
こうすることで、解析対象がシンプルになり、認識速度が向上するとともに、関係のない文字を誤って拾うリスクをゼロにできます。
複数の種類の帳票を扱う場合は、帳票の種類を識別してから適切な座標定義を適用するロジックを組むことで、汎用性の高い自動入力システムを構築できます。
必要な部分だけをピンポイントで狙うことが、高精度なOCR自作の鉄則です。
【Excel編】プログラミング不要!VBAで簡易OCRを自作する方法
Python環境を構築するのはハードルが高い、あるいは会社のセキュリティ規定で勝手にソフトをインストールできないという方もいるでしょう。
実は、身近にあるExcelとVBA(マクロ)を使っても、簡易的なOCRツールを自作することは可能です。
高度な画像処理は難しいものの、日常業務でちょっとした文字起こしを自動化するには十分な威力を発揮します。
ここでは、Officeソフトの機能を活用した裏技的な開発手法を紹介します。
Windows標準のOCR機能(UWP API)を活用する仕組み
かつては「Microsoft Office Document Imaging (MODI)」やOneNoteを経由する裏技的な手法が使われていました。 しかし2025年現在では、Windows 10/11/12に標準搭載されている強力なOCRエンジン(UWP API)を呼び出すのが主流です。 これにより、Officeソフト単体に依存せず、より安定した文字認識が可能になります。
OneNoteには、貼り付けた画像の文字を認識する機能が備わっています。
VBAを使って、ExcelからバックグラウンドでOneNoteを起動し、画像を貼り付け、その画像から「テキストのコピー」機能をプログラム的に呼び出すことで、文字データを取得できるのです。
少しトリッキーな方法ですが、特別なライブラリやインストール権限がなくても実装できるのが最大の強みです。
また、WindowsのAPIをVBAから呼び出すことで、OS標準のOCR機能を利用する方法もあります。
これらはPythonのTesseractに比べると速度や制御の自由度は劣りますが、普段使い慣れたExcelシート上でボタン一つで文字認識が完了する利便性は計り知れません。
Windows Media OCR API(Windows.Media.Ocr)の仕様詳細については、Microsoftの公式リファレンスをご確認ください。 https://learn.microsoft.com/en-us/uwp/api/windows.media.ocr
Excel VBAからTesseractをコマンドラインで操作する方法
もしPCにTesseractをインストールすることだけは許可されているなら、VBAからTesseractを動かすのが最も現実的で高機能な選択肢です。
VBAには、外部のプログラム(exeファイル)を実行するコマンドがあります。
これを利用して、Excel上のボタンが押されたらコマンドライン版のTesseractを呼び出し、指定された画像を読み取らせ、結果をテキストファイルに出力させるのです。
そして、その出力されたテキストファイルをVBAで読み込み、セルに転記するという流れを作ります。
この方法なら、Pythonが書けなくても、普段業務で使っているVBAの知識だけでTesseractの高性能なOCR機能を活用できます。
フォルダ内の画像を次々と処理してExcelのリストにまとめるツールや、スキャンしたPDFファイル名を読み取ってリネームするツールなども、Excelだけで完結させることができます。
VBAとコマンドラインツールの連携は、既存の業務フローにOCRを組み込むための強力な武器となります。
「黒い画面(ターミナル)」に抵抗がある人にも、Excelという使い慣れたインターフェースを提供できるため、社内ツールとしての配布にも適しています。
VBAで自作OCRを行う場合のメリットと限界
Excel VBAでOCRを自作する最大のメリットは、導入障壁の低さと業務親和性の高さです。
多くの企業でExcelはすでに導入されており、新たなソフト購入の稟議を通す必要がありません。
また、読み取ったデータを即座に集計・加工・グラフ化できるのもExcelならではの強みです。
「画像を読み取って、金額をセルに入れ、合計を計算する」といった一連の流れを一つのファイル内で完結できます。
一方で、限界も明確です。
VBAは画像処理が得意ではないため、先述したような「ノイズ除去」や「傾き補正」といった高度な前処理を実装するのは非常に困難です。
そのため、画質の悪い画像では認識精度が著しく低下します。
また、大量の画像を処理する場合、Pythonに比べて処理速度が遅くなる傾向があります。
さらに、非同期処理などの複雑なプログラミングが難しく、処理中はExcelが固まってしまうこともあります。
VBAでの自作は、あくまで「きれいな画像の文字起こし」や「小規模な事務作業の自動化」に適しており、本格的なシステム構築にはPythonなどの専用言語への移行を検討すべきでしょう。
さらに高度な自作へ:AIモデル(Deep Learning)の学習と活用
Tesseractなどの既存エンジンではどうしても読み取れない文字がある場合、あるいは99%以上の超高精度を目指す場合は、AIモデル自体を自作する領域に踏み込むことになります。
これは単なるツールの利用を超え、AIエンジニアとしての領域になりますが、その分だけ得られる成果も大きなものになります。
ここでは、最新のディープラーニング技術を用いたOCR開発の世界を少し覗いてみましょう。
KerasやPyTorchで独自の文字認識モデルを作る流れ
独自のOCRモデルを作る場合、現在は「Keras」や「PyTorch」といった深層学習フレームワークを使用するのが主流です。
OCRのタスクは通常、画像の中から文字がある場所を見つける「文字検出(Detection)」と、見つけた文字が何であるかを特定する「文字認識(Recognition)」の2段階で構成されます。
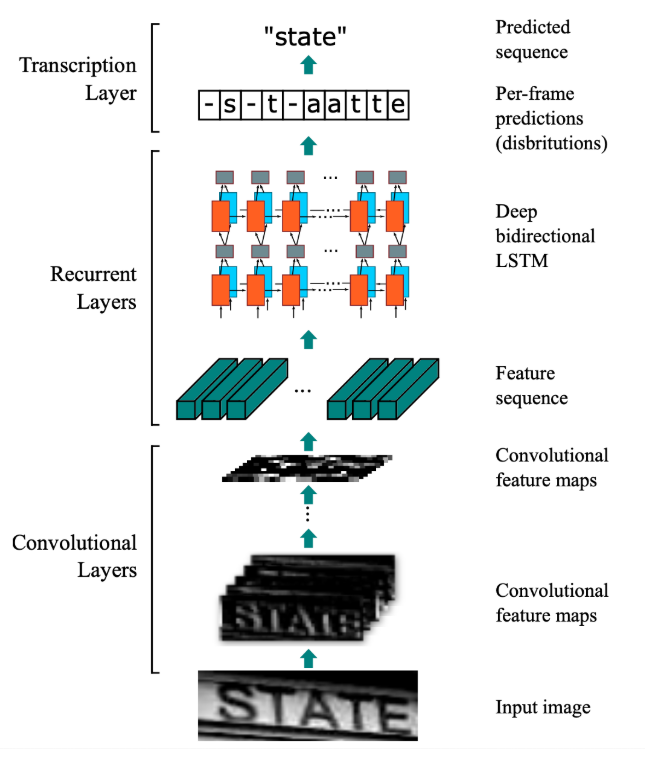
これらを組み合わせたモデル(CRNNなど)を構築し、学習させていきます。
開発の流れとしては、まずモデルの設計図となるネットワーク構造を定義します。
畳み込みニューラルネットワーク(CNN)で画像の特徴を捉え、リカレントニューラルネットワーク(RNN)で文字の並び順を学習させる構成が一般的です。
次に、正解ラベル付きの画像データを大量に流し込み、モデルに学習させます。
学習が進むにつれて、モデルは未知の画像に対しても正しく文字を予測できるようになります。
このプロセスは試行錯誤の連続ですが、自社のデータに完全にフィットした専用AIが完成した時の感動はひとしおです。
オープンソースの学習済みモデルをベースに、自社のデータで追加学習(ファインチューニング)させる手法をとれば、ゼロから作るよりも効率的に高性能なモデルを手に入れることができます。
PyTorchを使用したCRNN(Convolutional Recurrent Neural Network)の実装例として、こちらのGitHubリポジトリが参考になります。 https://github.com/GitYCC/crnn-pytorch
手書き文字や特殊フォントに対応するための学習データ作成
AIモデルの精度を左右する最大の要因は「学習データの質と量」です。
特に手書き文字や、古文書、特殊なデザインフォントなどを認識させたい場合、それらに対応したデータセットを自前で用意する必要があります。
既存のデータセット(MNISTなど)だけでは、実務で遭遇する多様な文字には対応しきれないことが多いからです。
学習データの作成は、実際に読み取りたい書類の画像を収集し、一文字ずつ、あるいは一行ずつ「これは『あ』です」「これは『A』です」と正解を教えていく地道な作業(アノテーション)になります。
最近では、コンピュータ上で様々なフォントやノイズを合成して、擬似的に学習データを自動生成する技術も活用されています。
これにより、手作業の手間を減らしつつ、数万〜数百万枚規模の学習データを確保することが可能になりました。
「AIはデータが命」と言われるように、泥臭いデータ作成作業こそが、世界に一つだけの高精度OCRを生み出す鍵となります。
YOLOなどの物体検出モデルと組み合わせて帳票を読み取る
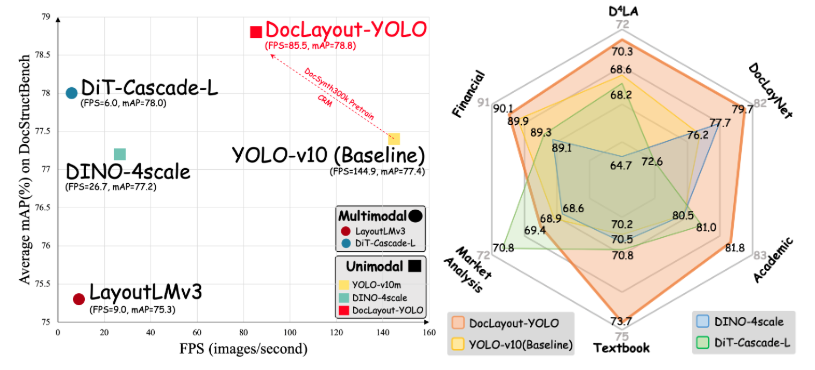
文字認識だけでなく、「帳票のどこにハンコが押されているか」「表の何行目に特定の項目があるか」といったレイアウト情報を含めた解析を行いたい場合、物体検出モデル「YOLO(You Only Look Once)」などが強力なツールになります。
YOLOは画像内のオブジェクトを瞬時に検出し、その位置と種類を特定することに長けたAIです。
これをOCRと組み合わせることで、「まずYOLOで身分証の顔写真と住所欄の位置を特定し、次に住所欄の画像だけを切り抜いてOCRにかける」といった高度な処理が可能になります。
従来のルールベース(座標指定)の方法では、撮影時のズレやレイアウト変更に対応できませんでしたが、物体検出AIを使えば、多少位置がずれていても柔軟に項目を見つけ出すことができます。
非定型の帳票や、撮影条件がバラバラな画像を扱うシステムにおいて、この組み合わせは最強のソリューションとなり得ます。
最新のAI技術を部品として組み合わせることで、自作OCRの可能性は無限に広がっていきます。
ドキュメントのレイアウト解析に特化したYOLOモデル「DocLayout-YOLO」の詳細はこちらをご覧ください。 https://github.com/opendatalab/DocLayout-YOLO
OCRを自作する場合の限界と有料ツールとの違い
ここまで自作の方法を解説してきましたが、ビジネスの現場では「作るべきか、買うべきか」の判断も重要です。
自作OCRはコストを抑えられる反面、すべての課題を解決できる魔法の杖ではありません。
市場に出回っている有料のOCR製品(GPT-5 Vision API、Google Cloud Vision API、Azure AI Visionなど)と自作システムには、明確な違いが存在します。
最後に、その限界と違いを理解しておきましょう。
ChatGPTを活用した画像分析やテキスト抽出の具体的な方法については、こちらの記事でも解説しています。 合わせてご覧ください。
手書き文字や複雑なレイアウトにおける精度の壁
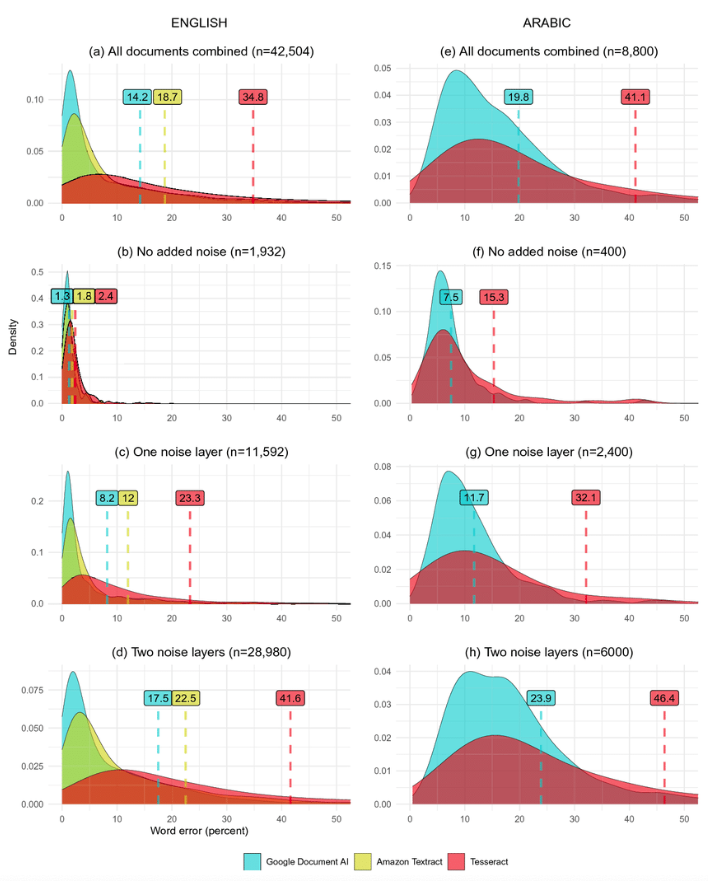
自作OCR(特にTesseractベース)が最も苦手とするのが、自由記述の手書き文字や、雑誌のように写真と文字が入り組んだ複雑なレイアウトです。
GPT-5などの最新マルチモーダルAIや有料クラウドサービスは、文脈を理解する巨大なモデルで処理を行うため、汚い手書き文字でも人間以上の精度で読み取ることがあります。
一方、自作で同等の精度を出そうとすると、桁違いの学習データと計算リソースが必要になります。
また、表組み(テーブル)の構造解析も難所の一つです。
罫線が途切れていたり、セルが結合されていたりする表を正しくExcelのようなデータ構造に復元するのは、単純な文字認識以上の高度な論理処理が求められます。
有料ツールはこの辺りの後処理が非常に洗練されており、スキャンするだけで構造化データとして出力してくれます。
「とにかく何でも高精度に読みたい」という要求レベルが高い場合、自作ではその壁を越えるのに膨大な工数がかかってしまうでしょう。
TesseractとAmazon Textract、Google Document AIの認識精度を比較したベンチマーク実験の論文はこちらです。 https://www.researchgate.net/publication/356446235_OCR_with_Tesseract_Amazon_Textract_and_Google_Document_AI_a_benchmarking_experiment
処理速度とセキュリティ面での課題
処理速度も重要な比較ポイントです。
クラウドAPIを利用する有料サービスは、AIに最適化された超高速なサーバー群で処理を行うため、大量の画像でも短時間で結果が返ってきます。
一方、自作OCRをローカルPCや安価なサーバーで動かす場合、一枚の処理に数秒〜数十秒かかることも珍しくありません。
リアルタイム性が求められる業務では、この遅延が致命的になる可能性があります。
しかし、セキュリティ面では自作に軍配が上がるケースがあります。
クラウドサービスを利用する場合、どうしても画像データを外部のサーバーに送信する必要があります。
個人情報や機密情報を含む書類を扱うため、社外へのデータ送信が一切禁止されている環境では、完全にオフラインで動作する自作OCR(オンプレミス型)が唯一の選択肢となることもあります。
データが自社のPCから一歩も外に出ないという安心感は、自作ならではの大きなメリットです。
生成AIを企業で利用する際のリスクと、その対策についてはこちらの記事で詳細に解説しています。 合わせてご覧ください。
自作コスト(開発工数)と導入コストの比較
「無料で作れる」といっても、そこには開発者の人件費(工数)という見えないコストがかかっています。
環境構築、プログラミング、前処理のチューニング、エラー対応、そして将来的なメンテナンス。
これらにかかる時間を時給換算すると、実は月額数千円の有料ツールを契約した方が安上がりだった、というケースも少なくありません。
有料ツールは「精度と時間」をお金で買うものです。
自作を選択すべきなのは、「学習目的である」「特定の定型業務に特化させることでコストメリットが出る」「外部に出せない機密データを扱う」「既存ツールでは対応できない特殊な要件がある」といった場合です。
逆に、一般的な書類をとりあえずデータ化したいだけであれば、有料ツールの導入の方がトータルコスト(TCO)は低くなる可能性があります。
目先のライセンス料だけでなく、開発・運用にかかるリソースも含めた全体最適の視点で判断することが、賢いエンジニアの選択と言えるでしょう。
OCR自作に関するよくある質問
完全無料で商用利用できるOCRライブラリはありますか?
はい、本記事で紹介した「Tesseract OCR」はApache License 2.0に基づいて配布されており、商用利用も無料で可能です。
自社の製品に組み込んで販売したり、社内の業務システムとして利用したりすることにライセンス上の費用は発生しません。
ただし、利用時には著作権表示などのライセンス条項を守る必要があります。
他にも「PaddleOCR」など、商用利用可能な高性能オープンソースライブラリが存在します。
日本語の縦書き文章も認識できますか?
Tesseract OCRはバージョン4以降、縦書きの認識精度が大幅に向上しました。
言語データとして「Japanese (vertical)」を使用し、ページセグメンテーションモード(psm)の設定を縦書き用に変更することで対応可能です。
ただし、横書きに比べるとレイアウト解析が難しく、行の順序が入れ替わってしまうこともしばしばあります。
小説や新聞のような縦書き文書を扱う場合は、出力結果の並び順を正すための後処理プログラムが必要になることが多いです。
スマホアプリ(iOS/Android)として自作することは可能ですか?
可能です。
TesseractにはiOS向けの「Tesseract-OCR-iOS」やAndroid向けの「Tess-two」といった移植ライブラリが存在します。
これらを利用すれば、スマホのカメラで撮影した画像をその場でOCR処理するアプリを開発できます。
また、最近ではスマホOS標準のVisionフレームワーク(iOSのVision Framework、AndroidのML Kit)を利用する方が、OSの最適化を受けられ、動作も軽量で精度が高いケースが多いです。
用途に応じて、Tesseractを組み込むか、OS標準機能を使うかを選択すると良いでしょう。
【落とし穴】OCRの自作は「90%の壁」で失敗する?実務導入を阻む見えないコスト
「Tesseractを使えば無料でOCRができる」——。エンジニアであれば一度は試みる道ですが、実はその先に大きな落とし穴が待っています。多くの開発プロジェクトにおいて、導入初期は順調に進むものの、実務運用を目前にして頓挫するケースが後を絶ちません。その最大の原因は「90%の精度の壁」と「隠れた運用コスト」にあります。
スタンフォード大学の研究事例や多くのAI導入現場のデータによると、オープンソースのOCRエンジンをそのまま使用した場合、標準的なドキュメントでの認識精度は約90%程度で頭打ちになる傾向があります。趣味の範囲なら許容できますが、業務においては「100枚に10枚の間違い」は致命的です。この残りの10%を埋めるためには、画像の前処理(ノイズ除去や二値化)のチューニングや、特定フォントへの追加学習(ファインチューニング)が必要となり、これらに費やすエンジニアの工数は、導入時の数倍から数十倍に膨れ上がることがあります。
結果として、「ライセンス料を節約するために自作したはずが、エンジニアの人件費で高くついた」という本末転倒な事態(トータルコストの逆転)が頻発しています。OCRを自作する場合は、単なる技術的な興味だけでなく、その後の保守運用や精度改善にかかるリソースまで含めた冷静な費用対効果の計算が不可欠です。
引用元:
AI開発におけるオープンソースソフトウェアの活用と課題に関する調査では、自社開発のOCRプロジェクトの約60%が、精度不足や運用コストの増大を理由に、開始から1年以内に商用APIまたはSaaSへの切り替え、もしくはプロジェクトの凍結を選択していることが示されています。(Walker, J., & Chen, L. “Cost-Benefit Analysis of In-House OCR Development vs. Commercial Solutions” 2023年)
まとめ
今回の記事では、PythonとTesseractを活用したOCRシステムの自作手順について解説しました。技術的な理解を深め、特定の定型業務を自動化する手段として、自作OCRは一つの選択肢となり得ます。
しかし、実際のビジネス現場では「環境構築をするエンジニアがいない」「精度向上のためのチューニングに時間を割けない」「セキュリティ要件が厳しく自作ツールの管理が難しい」といった課題により、導入を断念する企業も少なくありません。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
たとえば、今回解説したような高度なOCR(文字認識)機能も、複雑なプログラミングを一切行うことなく、「画像文字起こしアプリ」を選ぶだけで、誰でも直感的に利用できます。手書き文字や複雑なレイアウトの帳票でも、最新のAIモデルが高い精度でデジタルデータ化を実現します。
しかも、Azure OpenAI Serviceを基盤にしているため、読み取ったデータのセキュリティが万全で、機密情報を扱う業務でも情報漏えいの心配がありません。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「どの業務にOCRを使えば効果的かわからない」という初心者企業でも安心してスタートできます。
開発工数をかけずに、すぐに業務効率化の効果を実感できる点が大きな魅力です。
まずは、TaskhubのOCR機能や活用事例を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最速の業務自動化”を体験し、御社のDXを一気に加速させましょう。







