

「社内ドキュメントを検索させても、見当違いな回答ばかり返ってくる」
「RAGを導入したけれど、結局ハルシネーション(嘘の回答)がなくならない」
このような課題に直面し、実用化の壁を感じている開発者やプロジェクトマネージャーの方は多いのではないでしょうか。
RAG(Retrieval-Augmented Generation)は、LLMに外部知識を与える強力な手法ですが、単にデータをベクトル化して検索するだけでは、実務で使える精度には到達しません。
精度を高めるには、データの質、検索アルゴリズム、生成プロンプト、そして評価という一連のパイプラインすべてにおいて、適切なチューニングが必要です。
本記事では、RAGの精度が上がらない根本原因を特定し、データ前処理から最新のAdvanced RAG手法まで、具体的な改善策を網羅的に解説します。
AI導入支援を行っている弊社の知見をもとに、現場ですぐに試せるテクニックを厳選しました。
ぜひ、自社のRAGシステムの改善にお役立てください。
ChatGPTを使った社内文書検索の具体的な導入メリットや事例については、こちらの記事でも詳しく解説しています。 合わせてご覧ください。
そもそもRAGの精度が上がらない原因はどこにある?
RAGの精度課題は、大きく分けて「検索(Retrieval)」と「生成(Generation)」の2つのフェーズに潜んでいます。
問題の所在を明確にせずに闇雲にプロンプトを修正しても、根本的な解決にはなりません。まずはボトルネックがどこにあるのかを特定することが、改善への第一歩です。
ここでは、精度低下の主な原因と、その切り分け方について解説します。
こちらはRAG技術の包括的な調査と課題についてまとめられた論文です。 合わせてご覧ください。 https://arxiv.org/abs/2401.05856
検索システムの限界?LLMの回答ミス?ボトルネックの特定方法
RAGの精度改善を進める際、最初にすべきことは「検索が悪いのか」「生成が悪いのか」を切り分けることです。ここを間違えると、効果のない施策に時間を費やすことになります。
確認方法はシンプルです。ユーザーの質問に対して、システムが検索してきた「参照ドキュメント」の中身を目視で確認してください。もし、そのドキュメントの中に正解となる情報が含まれていなければ、それは「検索(Retrieval)」の問題です。どんなに高性能なGPT-5のようなLLMを使っても、情報がなければ正しい回答は作れません。
一方で、参照ドキュメントの中に正しい情報が書かれているにもかかわらず、回答がおかしい場合は「生成(Generation)」の問題です。LLMが情報を読み間違えているか、指示に従っていない可能性があります。
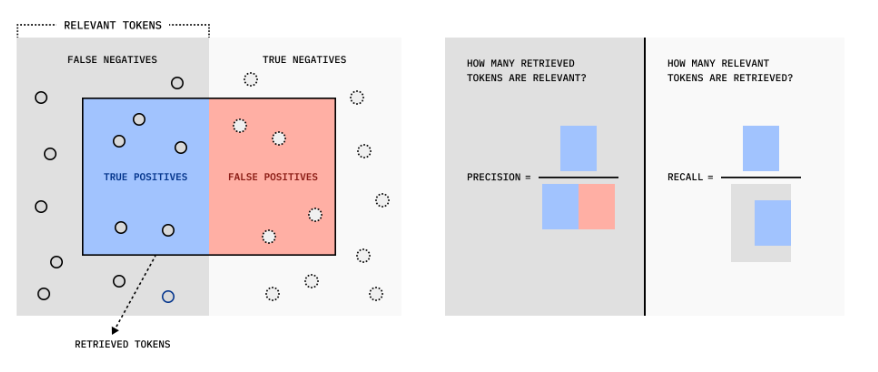
このように、まずはログを確認し、検索結果に正解が含まれている割合(Recall)と、その情報を使って正しく回答できた割合を分けて評価することで、優先すべき対策が見えてきます。
GPT-5に関する最新の情報やGPT-4との違いについては、こちらの記事で詳しく解説しています。 合わせてご覧ください。
ユーザーの質問意図と検索結果のズレ(Retrievalの課題)
検索フェーズにおける最大の問題は、ユーザーが入力する検索クエリと、データベース内のドキュメントとの間に「言葉の壁」や「意味のズレ」が生じることです。
従来のベクトル検索(Semantic Search)は意味の近さを計算しますが、ユーザーの質問が曖昧だったり、専門用語の使い方がドキュメントと異なっていたりすると、適切なチャンク(文章の塊)を拾えません。たとえば、社内用語で「A票」と呼ばれる書類について、ユーザーが「経費精算書」と検索した場合、ベクトル空間上での距離が遠くなり、検索漏れが発生することがあります。
また、質問文が短すぎる場合も、文脈を捉えきれずに精度が下がります。ユーザーは人間相手のように「あれについて教えて」といった簡易な聞き方をすることが多いため、そのまま検索にかけても意図したドキュメントがヒットしないのです。
参照データはあるのに正しい回答が作れない(Generationの課題)
検索システムが完璧なドキュメントを持ってきたとしても、LLMが正しい回答を生成できるとは限りません。これがGenerationの課題です。
主な原因として、参照すべき情報量が多すぎてLLMが混乱するケースがあります。検索結果として関連度の高いドキュメントを10個渡したとしても、その中に相反する情報が含まれていたり、ノイズ情報が多かったりすると、LLMはどれを信じていいか判断できず、ハルシネーションを起こすことがあります。
また、プロンプトの指示が不十分な場合も精度が下がります。「提供された情報のみを使って回答して」という制約条件を強くかけないと、LLMは自身の学習データ(インターネット上の一般的な知識)を優先して回答してしまい、社内ルールとは異なる一般的な回答をしてしまうことがあります。特にGPT-5のような最新モデルは知識量が膨大であるため、外部知識を遮断する強い指示が必要です。
【データ前処理】精度向上の8割を決めるデータのクレンジングと構造化
RAGの精度において、最も重要かつ工数がかかるのがデータの前処理です。
「Garbage In, Garbage Out(ゴミを入れればゴミが出てくる)」の原則通り、質の低いデータを検索対象にしている限り、どれだけ高度なモデルを使っても精度は上がりません。
ここでは、LLMが理解しやすい形にデータを整形するための具体的な手法を紹介します。
社内データをLLMに学習させる具体的な方法やメリットについては、こちらの記事でも詳しく解説しています。 合わせてご覧ください。
ノイズ除去:ヘッダー・フッターや無意味な文字列の削除
社内ドキュメント、特にPDFやPowerPoint資料には、本文とは関係のない情報が大量に含まれています。これらをそのままテキスト化してベクトルDBに登録することは、検索精度を下げる大きな要因になります。
具体的には、全ページに共通して入っている「社外秘」という透かし文字、ヘッダーの日付、フッターのページ番号、そして装飾のための無意味な記号の羅列などです。これらがチャンク(分割された文章)の中に混入すると、ベクトル検索をする際に意味のある情報としての重み付けを阻害してしまいます。
たとえば、すべてのチャンクに「2024年度版」という文字が入っていると、そのキーワードでの検索差別化ができなくなります。PythonのスクリプトやETLツールを使用して、正規表現などでこれらのノイズを徹底的に削除することが、精度の高いインデックスを作る第一歩です。地味な作業ですが、このクリーニングを行うだけで検索精度が劇的に向上するケースも少なくありません。
構造化データ化:LLMが理解しやすいMarkdown形式への変換
PDFやWordファイルを単なるプレーンテキストとして抽出するだけでは不十分です。LLMは文章の構造を理解することで、内容の重要度や文脈をより正確に把握できるからです。
推奨されるのは、すべてのドキュメントをMarkdown形式に変換することです。見出しを「#」や「##」でタグ付けし、リストを箇条書き記号で表現することで、文書の階層構造が明確になります。これにより、LLMは「ここは見出しであり、トピックが変わった」と認識でき、情報の区切りを正しく理解できます。
また、表形式のデータをMarkdownのテーブル記法に変換することも重要です。複雑なレイアウトの表をただのテキストの羅列にしてしまうと、行と列の関係性が崩れ、LLMは数値を正しく読み取れません。構造化されたデータとして保持することで、検索時にも生成時にも、情報の正確性が担保されやすくなります。
図表・画像のテキスト化:OCRとキャプション付与で検索対象にする
多くの企業ドキュメントにおいて、重要な情報はテキストだけでなく、図表やスライドの画像の中に含まれています。これらを無視してしまうと、情報の欠損が起きます。
画像を検索対象にするためには、OCR(光学文字認識)技術を使って画像内の文字をテキスト化する必要があります。さらに有効なのが、マルチモーダルモデルを使って画像そのものの説明(キャプション)を生成し、メタデータとして付与する方法です。たとえば、システム構成図の画像に対して「サーバーAとサーバーBがロードバランサーを介して接続されている図」というテキスト説明を付与します。
これにより、ユーザーが「サーバー構成について教えて」と質問した際に、テキスト情報だけでなく、画像の意味内容も含めて検索が可能になります。GPT-5のような最新モデルは画像理解能力が高いため、画像データそのものをコンテキストとして渡す手法も有効ですが、検索段階ではテキスト化された情報が依然として重要です。
メタデータの付与:検索の絞り込みを可能にする属性情報の追加
ベクトル検索は「意味の近さ」で検索しますが、実務では「特定の条件」で絞り込みたい場面が多々あります。これを可能にするのがメタデータの付与です。
ドキュメントをデータベースに保存する際、単に本文を保存するだけでなく、「作成日」「作成者」「カテゴリ(技術仕様書、議事録など)」「対象製品」といった属性情報をセットで保存します。これにより、検索時に「2024年以降のデータのみ」「A製品に関するドキュメントのみ」といったフィルタリングが可能になります。
メタデータがないと、古いマニュアルと新しいマニュアルが混在して検索され、LLMが古い情報を元に回答してしまうリスクがあります。特に更新頻度の高いドキュメントを扱う場合、日付によるフィルタリングやバージョン管理のメタデータは必須です。これにより、ベクトル検索の曖昧さを補完し、確実に必要なドキュメント群にアクセスできるようになります。
【チャンク・インデックス】検索精度を高める分割と保存の戦略
ドキュメントをどのように分割(チャンク化)して保存するかは、検索精度に直結する重要な設計要素です。
細かすぎれば文脈が失われ、大きすぎれば余計な情報が混ざり込みます。
ここでは、検索漏れを防ぎつつ、LLMにとって読みやすい最適な情報の切り出し方について解説します。
チャンクサイズの最適化:文脈を途切れさせない分割ルール
チャンクサイズとは、ドキュメントを分割する際の文字数のことです。これを適切に設定しないと、検索精度は大きく低下します。
サイズが小さすぎると、主語や目的語が欠落し、その文章単体では意味が通じなくなります。逆にサイズが大きすぎると、一つのチャンクに複数のトピックが混在してしまい、ベクトル化した際の特徴がぼやけてしまいます。一般的には500文字から1000文字程度が目安とされますが、ドキュメントの性質によって最適値は異なります。
重要なのは、単に文字数で機械的に切るのではなく、意味のまとまりで切ることです。句読点や改行コード、段落の変わり目を基準に分割する「Recursive Character Text Splitter」などの手法を用いるのが一般的です。文脈が途切れないように、意味の区切りを意識してサイズを調整することで、検索ヒット率と回答精度のバランスを保つことができます。
こちらはチャンキング戦略の違いが検索精度に与える影響を評価した記事です。 合わせてご覧ください。 https://research.trychroma.com/evaluating-chunking
オーバーラップの設定:情報の欠落を防ぐつなぎ目の工夫
チャンク分割を行う際、どうしても文章のつなぎ目で重要な情報が分断されてしまうリスクがあります。これを防ぐために設定するのが「オーバーラップ(重複部分)」です。
たとえば、チャンクAの末尾100文字と、続くチャンクBの冒頭100文字を重複させて保存します。こうすることで、文脈のつなぎ目にあるキーワードや因果関係が、どちらかのチャンクには完全な形で含まれることになります。特に、「AならばBである」といった論理構造がチャンクの境界で切れてしまうと、LLMは論理を正しく解釈できません。
オーバーラップを10%〜20%程度設けることは、RAG構築のベストプラクティスの一つです。わずかなストレージ容量の増加と引き換えに、検索漏れや文脈理解の失敗を大幅に減らすことができるため、必ず設定すべきパラメータと言えます。
親ドキュメント検索(Parent Document Retriever)の活用
チャンクサイズの問題に対する一つの解決策として、「Parent Document Retriever」という手法があります。これは「検索用」と「回答生成用」で、扱うテキストのサイズを変えるというアプローチです。
具体的には、検索用には意味が凝縮された「小さなチャンク」を使用し、LLMに渡す回答生成用には、その小チャンクが含まれる「大きな親ドキュメント(あるいは広範囲のチャンク)」を取得します。
これにより、ピンポイントな検索精度(Small Chunkの利点)と、豊富な文脈情報(Large Chunkの利点)の両方を享受できます。たとえば、特定の専門用語で検索をヒットさせつつ、LLMにはその用語が使われている段落全体や前後の文脈を渡すことができるため、回答の整合性が格段に向上します。実装難易度は少し上がりますが、精度向上には非常に効果的な手法です。
【検索・リトリーバル】意図したドキュメントを正しく取得する手法
データが綺麗に整ったら、次はいかにしてユーザーの質問意図に合った情報を引き出すかです。
単純なベクトル検索だけでは対応できないケースも増えており、複数の検索手法を組み合わせるアプローチが標準になりつつあります。
ここでは、検索のヒット率(Recall)と適合率(Precision)を高めるための具体的な技術を紹介します。
ハイブリッド検索:キーワード検索とベクトル検索のいいとこ取り
ベクトル検索は意味の類似性を捉えるのが得意ですが、固有名詞や型番、完全一致が必要なキーワードの検索には弱いという側面があります。これを補うのが、従来の全文検索(キーワード検索)とベクトル検索を組み合わせた「ハイブリッド検索」です。
たとえば、社内の製品型番「X-2000」について検索したい場合、ベクトル検索だけでは「Xシリーズのようなもの」という曖昧な結果になる可能性がありますが、キーワード検索(BM25など)を併用すれば、その型番が含まれるドキュメントを確実にピンポイントで拾えます。
ハイブリッド検索では、両方の検索結果をスコアリングし、統合してランキング付けを行います。ユーザーの質問には「概念的な質問」と「具体的な事実確認」の両方が含まれるため、この2つの検索手法を組み合わせることで、あらゆるタイプの質問に対して安定した検索結果を返すことができるようになります。
こちらは密な検索、疎な検索、およびハイブリッド検索の実用的な技術比較について解説した記事です。 合わせてご覧ください。 https://medium.com/@robertdennyson/dense-vs-sparse-vs-hybrid-rrf-which-rag-technique-actually-works-1228c0ae3f69
クエリ拡張(Query Expansion):ユーザーの曖昧な質問を補完する
ユーザーの質問は常に完璧ではありません。「あの件どうなってる?」といった主語のない質問や、専門用語を知らずに一般的な言葉で検索してくることが多々あります。こうした曖昧なクエリを、検索システムが理解しやすい形に変換・拡張する技術が「クエリ拡張」です。
具体的には、ユーザーの入力した質問を一度LLMに通し、「この質問に関連する検索キーワードを5つ挙げてください」と指示して、類義語や関連語を生成させます。たとえば「PCが動かない」という質問から、「PC 起動しない」「画面 真っ暗」「電源 入らない トラブルシューティング」といったキーワードを生成し、これらを使って検索を行います。
これにより、ユーザーが思いつかなかった表現も含めて網羅的に検索できるようになり、検索漏れ(Recallの低下)を劇的に防ぐことができます。検索の裏側でLLMを一回噛ませることで、ユーザーの意図を汲み取った検索が可能になります。
クエリ変換(Query Transformation):検索しやすい言葉に書き換える
クエリ拡張と似ていますが、「クエリ変換」は複雑な質問を、検索エンジンが処理可能な単純な質問に分解・翻訳する手法です。
例えば、「2023年のA製品の売上と、2024年のB製品の売上を比較して」という質問が来た場合、そのままベクトル検索にかけても、両方の情報が都合よく入っているチャンクは見つかりにくいでしょう。そこで、LLMを使ってこの質問を「2023年 A製品 売上」「2024年 B製品 売上」という2つの独立したクエリに分解します。
それぞれで検索を実行し、得られた結果を統合して最終的な回答を生成します。このように、一度の検索では解決できない複合的なタスクを、実行可能なサブタスクに変換することで、RAGシステムはより複雑な質問にも正確に答えられるようになります。
リランキング(Reranking):検索結果を重要度順に並び替えて精度UP
ベクトル検索やハイブリッド検索で抽出された上位のドキュメントが、必ずしも質問に対する「正解」を含んでいるとは限りません。そこで、検索された候補(例えば上位50件)に対して、より高精度なモデルを使って再度ランク付けを行う処理が「リランキング」です。
リランカー(Reranker)と呼ばれる専用のモデルは、質問文とドキュメントのペアを読み込み、「このドキュメントは質問の回答として適切か」を厳密にスコアリングします。ベクトル検索は高速ですが精度はそこそこ、リランカーは計算コストがかかりますが精度は非常に高いという特徴があります。
この2段階構えにすることで、まずは高速に候補を絞り込み、最後にリランカーで本当に重要なドキュメントだけをLLMに渡すコンテキストとして選定できます。これにより、LLMに渡すノイズ情報が減り、回答精度が向上すると同時に、トークン数の節約にもつながります。
【プロンプト・生成】ハルシネーションを防ぎ回答品質を上げる指示出し
検索結果が正しくても、最後の生成フェーズでLLMが誤った解釈をしてしまっては意味がありません。
特に、LLMがもっともらしい嘘をつく「ハルシネーション」は、企業利用において最大のリスクです。
ここでは、取得した情報を忠実に反映させ、論理的な回答を生成させるためのプロンプトエンジニアリングについて解説します。
RAGシステムにおけるプロンプト作成の具体的な方法や活用事例については、こちらの記事で詳しく解説しています。 合わせてご覧ください。
役割と制約条件の定義:回答範囲を「提供された情報のみ」に限定する
プロンプトの冒頭で最も重要なのは、LLMに対して「外部知識を使わず、与えられたコンテキスト(検索結果)のみに基づいて回答すること」を強く制約することです。
具体的な指示としては、「あなたは社内ドキュメント検索アシスタントです」と役割を定義した上で、「以下の【参考情報】に記載されている内容のみを根拠として回答してください。もし情報がない場合は、『情報が見つかりません』と正直に答えてください」と明記します。
この「分からないときは分からないと言う」指示が非常に重要です。これがないと、LLMは親切心から自身の学習知識を使って適当な回答を捏造してしまいます。制約条件を厳格に設定し、事実に基づかない回答をブロックすることで、信頼性の高いシステムを構築できます。
引用元の明記指示:回答の根拠を提示させて信頼性を担保する
回答の信頼性を高めるためには、回答の中に参照元のドキュメント名やページ数を明記させるよう指示することが効果的です。
プロンプトにて「回答する際は、参考にした情報のソース(ファイル名やセクション)を必ず明記してください」と指示します。これにより、ユーザーは回答がどの資料に基づいているかを確認できるため、安心して情報を利用できます。また、LLM自身にとっても、根拠と回答を紐付けるプロセスが発生するため、ハルシネーションの抑制につながる効果があります。
実際の出力例として、「〜という手順が必要です(出典:社内規定マニュアル.pdf p.12)」のように出力されれば、ユーザーは必要に応じて原文を確認しに行くことも可能になります。
思考の連鎖(CoT):回答プロセスを言語化させて論理破綻を防ぐ
複雑な質問に対して正確に回答させるためには、「Chain of Thought(思考の連鎖)」と呼ばれるプロンプトテクニックが有効です。これは、いきなり結論を出させるのではなく、回答に至るまでの論理プロセスをステップ・バイ・ステップで記述させる手法です。
プロンプトに「回答を生成する前に、まずは与えられた情報を分析し、段階的に考えてください」という指示を加えます。GPT-5などの最新モデルは、この推論能力が大幅に強化されており、質問の難易度に応じて思考時間を自動で調整する機能も備わっています。
思考プロセスを出力させる(または内部で行わせる)ことで、情報の取り違えや論理の飛躍を防ぎ、整合性の取れた回答が得られるようになります。特に、複数のドキュメントにまたがる情報を統合して回答する場合に効果を発揮します。
【Advanced RAG】最新技術で限界を突破する高度なアプローチ
基本的なRAGの改善策をやり尽くしてもなお、精度に満足できない場合に検討すべき最新の手法があります。
AI技術の進化は早く、検索と生成の概念自体を拡張するような新しいアプローチが登場しています。
ここでは、より高度な課題解決を可能にするAdvanced RAGの代表的な手法を紹介します。
HyDE:仮想の回答を生成してから類似文書を検索する手法
HyDE(Hypothetical Document Embeddings)は、ユーザーの質問に対して、LLMがいったん「仮想的な回答(嘘でもいいので理想的な回答の形式)」を生成し、その仮想回答を使ってベクトル検索を行う手法です。
通常、質問文と回答文は使われる単語や文体が異なるため、ベクトル空間での距離が離れてしまうことがあります。しかし、HyDEを使えば「回答と回答(仮想)」の比較になるため、ベクトルの類似度が高まり、検索精度が向上します。
例えば「就業規則について」という短い質問に対し、LLMが「就業規則とは、労働時間や賃金などのルールを定めたものであり…」という仮想文章を生成します。これを検索クエリとして使うことで、実際の就業規則ドキュメントがヒットしやすくなります。ゼロショットでの検索性能を上げたい場合に有効な手法です。
こちらはHyDE(Hypothetical Document Embeddings)の手法について詳述された論文です。 合わせてご覧ください。 https://aclanthology.org/2023.acl-long.99/

GraphRAG:ナレッジグラフを活用して情報の関係性を理解させる
GraphRAGは、テキスト情報を「ナレッジグラフ(知識グラフ)」という構造に変換してRAGに活用する、Microsoftなどが提唱する最新手法です。従来のRAGがテキストの断片を検索するのに対し、GraphRAGは情報と情報の「関係性」を検索します。
ドキュメント内の登場人物、場所、概念などを「ノード」とし、それらの関係を「エッジ」として結びつけます。これにより、「AプロジェクトとBプロジェクトの共通点は何か?」といった、ドキュメント全体を俯瞰しなければ答えられないような全体的な質問(Global Question)に対して、圧倒的な強さを発揮します。
単純なキーワード検索では見落としてしまうような、隠れたつながりや因果関係をLLMに理解させることができるため、複雑なデータ分析や調査業務の自動化において、次世代のスタンダードになると期待されています。
こちらはGraphRAGの概念と従来手法に対する利点について解説したMicrosoftの公式ブログです。 合わせてご覧ください。 https://techcommunity.microsoft.com/blog/azure-ai-foundry-blog/the-future-of-ai-graphrag-%E2%80%93-a-better-way-to-query-interlinked-documents/4287182
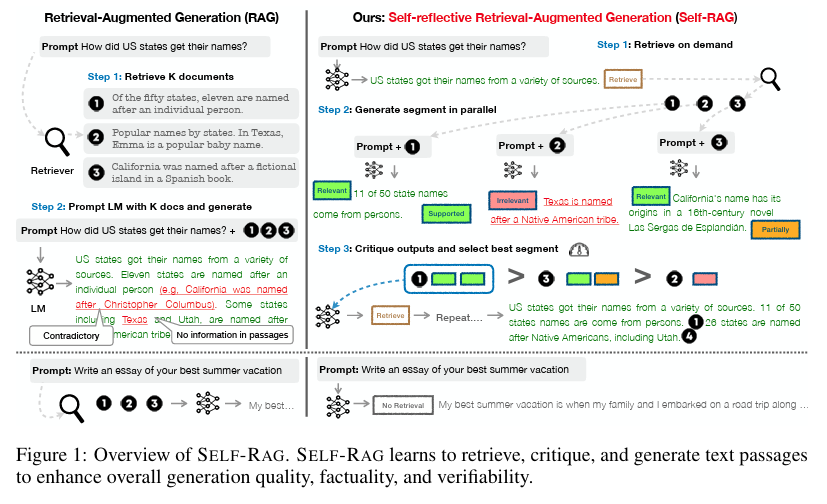
Self-RAG:LLM自身に回答の適切さを自己評価させる
Self-RAGは、LLMが回答を生成するプロセスの中で、自分自身で「検索が必要か?」「検索結果は適切か?」「回答は役に立つか?」を評価(Reflection)しながら進める手法です。
従来のRAGは一度検索したらそのまま回答していましたが、Self-RAGでは、生成された回答の品質が低いと判断すれば、再度検索を行ったり、回答を修正したりします。LLMの中に「監督者」がいるようなイメージです。
これにより、不要な検索を減らして回答速度を上げたり、逆に情報の不足を検知して補完したりと、動的な制御が可能になります。精度の高い回答のみをユーザーに届けるための、自律的な品質管理メカニズムと言えます。
こちらはSelf-RAGのフレームワークと学習プロセスについて解説した論文です。 合わせてご覧ください。 https://arxiv.org/abs/2310.11511
施策の効果を正しく測定するRAGの評価方法(Evaluation)
最後に、これまで紹介した施策が本当に効果を上げているのかを測定する方法について解説します。
感覚的な「良くなった気がする」ではなく、定量的な指標で評価することで、継続的な改善(PDCA)が可能になります。
RAGの評価指標「Ragas」でRetrieverとGeneratorをスコアリングする
RAGの評価を自動化するフレームワークとして「Ragas」が広く使われています。Ragasは、LLMを使ってRAGシステムの各コンポーネントをスコアリングするツールです。
主な指標には以下のようなものがあります。
- Context Precision: 検索された情報の中に、正解が含まれている割合。
- Faithfulness: 生成された回答が、検索された情報に基づいているか(ハルシネーションがないか)。
- Answer Relevance: 生成された回答が、ユーザーの質問に対して適切か。
これらの指標を数値化することで、「今回のプロンプト修正でFaithfulnessが10ポイント上がった」といった客観的な評価が可能になります。手動での確認には限界があるため、開発サイクルを回すためには必須のツールです。
こちらはRAGの自動評価フレームワーク「Ragas」について解説した論文です。 合わせてご覧ください。 https://arxiv.org/abs/2309.15217
「正解データセット」を作成して回答精度を定量的にテストする
自動評価ツールも便利ですが、最終的な品質保証には、人間が作成した「ゴールデンデータセット(正解データセット)」が不可欠です。
これは、「質問」と「理想的な回答」、そして「参照すべきドキュメント」の3つをセットにしたテストデータの集まりです。実際に運用で想定される質問を50〜100件程度用意し、システム改修のたびにこのテストセットを実行します。
正解データセットとの一致率を計測することで、新しい施策が以前の修正を壊していないか(回帰テスト)を確認できます。地道な作業ですが、自社特有のドメイン知識やニュアンスを正しく評価するためには、現場の専門家が作った正解データに基づく評価が最も信頼できます。
RAGの精度が上がらない本当の理由:検索と生成のボトルネックを特定せよ
社内ドキュメントを活用した生成AIシステム(RAG)を導入しても、「見当違いな回答が返ってくる」「ハルシネーションが頻発する」という課題に直面するケースは後を絶ちません。多くのプロジェクトでは、闇雲にプロンプトを修正しようとしますが、実は精度の低さは「検索(Retrieval)」と「生成(Generation)」のどちらかに明確な原因があります。
まず行うべきは、ユーザーの質問に対してシステムが取得した「参照ドキュメント」の確認です。もし参照データの中に正解が含まれていなければ、どれほど優秀なLLMを使っても正しい回答は導き出せません。これは検索エンジンの敗北を意味します。一方で、正解データが含まれているにもかかわらず回答が誤っている場合は、LLMへの指示出しや情報量の過多が原因となる生成フェーズの問題です。この切り分けを行わずに改善を進めることは、地図を持たずに航海に出るようなものです。
「ゴミを入れてもゴミしか出ない」データ前処理と構造化の重要性
RAGの精度を決定づける要因の約8割は、実はデータの前処理にあります。「Garbage In, Garbage Out(ゴミを入れればゴミが出てくる)」という原則は、AIの世界でも絶対的な真理です。PDFやPowerPointから抽出したテキストに含まれるヘッダー、フッター、無意味な記号などのノイズは、ベクトル検索の精度を著しく低下させます。
さらに、単なるテキスト抽出ではなく、Markdown形式への変換が推奨されます。見出しや箇条書き、表組みなどの構造情報を維持することで、LLMは文書の文脈を正しく理解できるようになります。また、図表や画像に含まれる重要情報をOCRでテキスト化し、キャプションを付与することも不可欠です。泥臭い作業ですが、データを綺麗に「クレンジング」し、AIが読みやすい形に「整形」することこそが、高精度なRAG構築への最短ルートです。
単純なベクトル検索はもう古い?ハイブリッド検索とリランキングの導入
ユーザーの質問は常に曖昧です。「PCが動かない」といった抽象的な質問や、正確な製品型番を含まない問い合わせに対して、従来のベクトル検索(意味検索)だけでは限界があります。そこで注目されているのが、キーワード完全一致検索とベクトル検索を組み合わせた「ハイブリッド検索」です。
さらに、検索精度を飛躍的に高める技術として「クエリ拡張」と「リランキング」が挙げられます。クエリ拡張では、ユーザーの質問をAIが解釈し、「画面が真っ暗」「電源が入らない」といった関連語句を自動生成して検索漏れを防ぎます。リランキングは、一次検索でヒットした多数のドキュメントを、専用のAIモデルを使って「回答としての適切さ」で並び替え、最も重要な情報だけをLLMに渡す技術です。これにより、ノイズ情報を排除し、回答の質を劇的に向上させることが可能になります。
生成AIの潜在能力を解き放つAdvanced RAGと評価システム
基本的な改善策で限界を感じた場合、Microsoftなどが提唱する「GraphRAG」や「HyDE」といったAdvanced RAGの手法が突破口となります。GraphRAGは、ドキュメント内の情報の関係性をナレッジグラフ化することで、全体を俯瞰した高度な質問に回答できるようになります。一方、HyDEはAIに仮想の回答を作成させてから検索を行うことで、質問とドキュメントの語彙のズレを解消します。
そして、これらの施策が奏功しているかを判断するためには、感覚ではなく定量的な評価が必要です。「Ragas」などの評価フレームワークを用い、検索精度(Recall)や回答の忠実性(Faithfulness)をスコアリングします。最終的には人間が作成した正解データセットとの一致率を計測し、継続的な改善サイクル(PDCA)を回すことが、実用的なRAGシステム完成への唯一の道です。
引用元:
検索拡張生成(RAG)システムにおける検索と生成の課題については、多くの実務家や研究者が指摘しています。Microsoft Researchは、ナレッジグラフを用いたGraphRAGの有効性を提唱しており(Edge, D., et al. “From Local to Global: A Graph RAG Approach to Query-Focused Summarization” 2024年)、RAG評価フレームワークとしてのRagasの活用も標準化しつつあります(Es, S., et al. “Ragas: Automated Evaluation of Retrieval Augmented Generation” 2023年)。
まとめ
多くの企業がDX推進や業務効率化の鍵として生成AIやRAGの構築に注目していますが、実用レベルの精度を出すには高度なチューニングや専門知識が必要不可欠です。
しかし、「社内にエンジニアがいない」「開発コストや時間をかけられない」といった理由で、導入を躊躇している企業も少なくありません。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
たとえば、高度な検索技術を駆使しなくても、議事録作成、ドキュメント要約、メール作成、さらにはデータ分析など、業務に必要な機能を「アプリ」として選ぶだけで、誰でも直感的にAIの恩恵を受けられます。
しかも、Azure OpenAI Serviceを基盤にしているため、エンタープライズレベルのセキュリティが担保されており、機密情報の取り扱いも安心です。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「RAGの精度が出ない」と悩むことなく、完成されたAIソリューションを即座に業務に組み込むことができます。
導入後すぐに効果を実感できる設計なので、複雑な開発プロセスを経ることなく、最短距離で業務効率化が図れる点が大きな魅力です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最速の生成AI活用”を体験し、御社のDXを一気に加速させましょう。







