

「プロンプトエンジニアリングの論文を読みたいけど、どれから手をつければいいかわからない…。」
「論文を読んでみたけど、専門用語が多くて内容が全く理解できない…。」
こういった悩みを持っている方もいるのではないでしょうか?
本記事では、プロンプトエンジニアリングを学ぶ上で必読の論文35選を厳選し、基礎から応用まで網羅的に解説します。
生成AIの専門家が、各論文の概要や重要性、そして論文から生まれた主要な技術について、初心者にも分かりやすく説明します。
この記事を最後まで読めば、プロンプトエンジニアリングの最先端の知識を効率的にインプットし、あなたのスキルを一段階引き上げることができるでしょう。
なぜ今、プロンプトエンジニアリングの論文を読むべきなのか?
プロンプトエンジニアリングのスキルを実践的に向上させる上で、なぜ論文を読むことが重要なのでしょうか。
その理由は、単にテクニックを学ぶ以上に、技術の根源的な理解を深め、自身の市場価値を高めることに繋がるからです。
ここでは、論文を読むべき3つの具体的な理由を解説します。
AI研究の最前線にある一次情報に触れられる
論文を読むことで、AI研究の本質的な知識を直接得ることができます。
論文は、AI研究の最前線で生まれた最新の知見が凝縮された一次情報です。
ブログ記事やニュースなどで解説される技術の多くは、元をたどれば一本の論文から始まっています。
一次情報に直接触れることで、技術が生まれた背景や理論的な根拠、そしてどのような実験によってその有効性が証明されたのかを、深く正確に理解することができます。
LLMの進化の系譜を体系的に理解できる
論文を読むことで、技術の進化の系譜を体系的に学ぶことができ、新しい技術が登場した際にも、その位置付けや重要性を迅速に理解できるようになります。
プロンプトエンジニアリングの技術は、日々新しいものが登場していますが、それらは独立して存在するわけではありません。
過去の論文で提案された技術をベースに、改良を重ねて発展しています。
例えば、「Few-shot」という概念が生まれ、それを発展させて「Chain-of-Thought」という推論技術が登場し、さらに複雑な問題に対応するために「Tree of Thoughts」が生み出される、といった進化の繋がりがあります。
自身のスキルを客観的に差別化し、市場価値を高める
論文を読み解く能力は、専門性を客観的に証明し、市場価値を大きく高める鍵です。
多くの人が二次情報や三次情報で知識を得る中で、一次情報である論文を読み解く能力は、あなたの専門性を客観的に証明する強力な武器となります。
技術の原理原則を理解している人材は、単にテクニックを知っているだけの人材よりも、遥かに高く評価されます。
なぜなら、原理を理解していれば、未知の問題に直面した際に、既存の技術を応用したり、新たな解決策を考案したりすることができるからです。
論文読解を通じて得られる深い知見は、あなたのキャリアにおける大きなアドバンテージとなり、市場価値を飛躍的に高めることに繋がるでしょう。
そもそもプロンプトエンジニアリングとは?基本をおさらい
こちらは、プロンプトエンジニアリングの基礎から最新技術までを網羅した実践的なガイドです。あわせてご覧ください。 https://www.promptingguide.ai/jp
論文を読む前に、プロンプトエンジニアリングの基本的な概念を再確認しておきましょう。
大規模言語モデル(LLM)との関係性や、その重要性を理解することが、論文の読解をスムーズに進めるための土台となります。
大規模言語モデル(LLM)とプロンプトの関係性
大規模言語モデル(LLM)とは、膨大なテキストデータを学習することで、人間のように自然な文章を生成したり、質問に答えたりする能力を持つAIのことです。
LLMは、入力されたテキスト(プロンプト)に続く、最も確率の高い言葉を予測することで機能します。
つまり、プロンプトはLLMに対する「指示書」や「命令書」のような役割を果たします。
どのようなプロンプトを与えるかによって、LLMから引き出されるアウトプットの質は劇的に変化します。
質の高いプロンプトはLLMの潜在能力を最大限に引き出し、一方で質の低いプロンプトは意図しない、あるいは不正確な回答を生成させてしまうのです。
プロンプトエンジニアリングの目的と重要性
プロンプトエンジニアリングとは、LLMから望ましい出力を得るために、最適なプロンプトを設計、構築、最適化する一連の技術や学問分野を指します。
その目的は、LLMの性能を最大限に引き出し、特定のタスクを効率的かつ高精度に実行させることにあります。
LLMの性能は固定的ではなく、プロンプトという「鍵」によってその能力が引き出されます。
そのため、プロンプトエンジニアリングは、AI活用の成否を分ける極めて重要なスキルとなっています。
例えば、同じLLMを使っても、プロンプトの工夫次第で、ありきたりな文章しか書けない状態から、プロのライターのような説得力のある文章を生成できる状態へと変化させることが可能なのです。
【厳選35選】プロンプトエンジニアリングの必読論文リスト
ここでは、プロンプトエンジニアリングを学ぶ上で必読と言える論文を35本、厳選して紹介します。
まずは基本として絶対に押さえておきたい10本、次に、より深い知識を得るための応用・発展的な25本に分けてリストアップしました。
【まず読むべき】基本となる重要論文10選
- Language Models are Few-Shot Learners
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods
- Emergent Abilities of Large Language Models
- A Survey of Large Language Models
- Reasoning with Language Model Prompting: A Survey
- Augmented Language Models: a Survey
【技術を深める】応用・発展論文25選
- FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS
- Deep Reinforcement Learning from Human Preferences
- LLaMA: Open and Efficient Foundation Language Models
- Scaling Laws for Neural Language Models
- Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
- Large Language Models are Zero-Shot Reasoners
- AUTOMATIC CHAIN OF THOUGHT PROMPTING IN LARGE LANGUAGE MODELS
- Generated Knowledge Prompting for Commonsense Reasoning
- Large Language Model Guided Tree-of-Thought
- ART: Automatic multi-step reasoning and tool-use for large language models
- LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS
- Active Prompting with Chain-of-Thought for Large Language Models
- Guiding Large Language Models via Directional Stimulus Prompting
- REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
- Multimodal Chain-of-Thought Reasoning in Language Models
- A Taxonomy of Prompt Modifiers for Text-To-Image Generation
- Towards Reasoning in Large Language Models: A Survey
- A Survey for In-context Learning
- Nature Language Reasoning, A Survey
- A Bibliometric Review of Large Language Models Research from 2017 to 2023
- One Small Step for Generative AI, One Giant Leap for AGI: A Complete Survey on ChatGPT in AIGC Era
- Tool Learning with Foundation Models
- Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
- Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study
- Few-shot Fine-tuning vs. In-context Learning: A Fair Comparison and Evaluation
論文から学ぶ!プロンプトエンジニアリングの主要技術
数多くの論文で提案されてきたプロンプトエンジニアリングの技術の中でも、特に重要で基礎となるものを5つ紹介します。
これらの技術のコンセプトを理解することで、多くの応用論文の読解がスムーズになり、実践でも役立てることができます。
【基本】Zero-shot / Few-shot プロンプティング
Zero-shotプロンプティングは、タスクの例を一切示さずに、指示だけでLLMにタスクを解かせる手法です。
例えば、「次の文章を要約してください:…」のように、直接的な命令を与えます。
一方、Few-shotプロンプティングは、プロンプト内にいくつかの例(入力と出力のペア)を提示することで、LLMがタスクの意図をより正確に理解できるように促す手法です。
GPT-3の性能を飛躍的に知らしめた論文「Language Models are Few-Shot Learners」でその有効性が示され、プロンプトエンジニアリングの基本中の基本として位置づけられています。
Few-shotプロンプティングは、モデルに追加の学習(ファインチューニング)を施すことなく、文脈内でタスクを学習させる「インコンテキスト学習」の基礎となる考え方です。
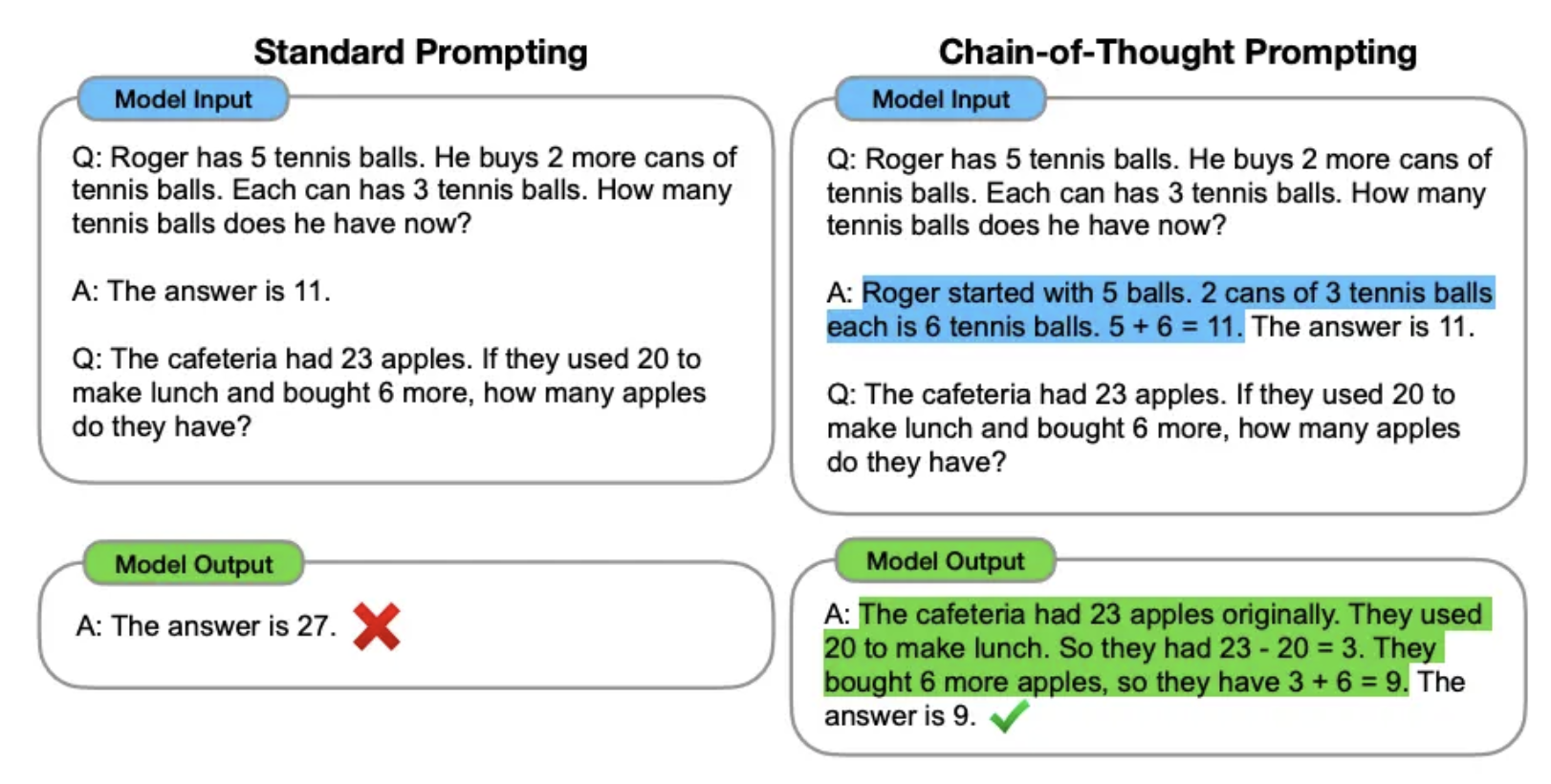
【推論能力向上】CoT (Chain-of-Thought)
CoT (Chain-of-Thought)は、LLMに最終的な答えだけでなく、そこに至るまでの中間的な思考の連鎖(Chain of Thought)を生成させる手法です。
特に、算術問題や常識的推論など、複数のステップを経て結論に至るような複雑なタスクにおいて、LLMの推論能力を大幅に向上させることが知られています。
プロンプトに「ステップバイステップで考えてください」といった一文を加えるだけで、LLMは思考プロセスを文章化しながら回答を導き出すようになります。
これにより、単に答えを出すだけでなく、そのプロセスが正しいかどうかを人間が検証しやすくなるというメリットもあります。
この技術は、「Chain-of-Thought Prompting Elicits Reasoning in Large Language Models」という論文で提案されました。
こちらは、Chain-of-Thoughtプロンプティングの具体的な使い方やコツを、豊富な例と共に解説した記事です。あわせてご覧ください。 https://www.promptingguide.ai/jp/techniques/cot
【回答精度向上】Self-Consistency
Self-Consistencyは、CoTをさらに発展させた手法で、回答の精度と信頼性を高めることを目的とします。
このアプローチでは、まず同じ問題に対してCoTを用いて、複数の異なる思考プロセスと回答を生成させます。
LLMは思考の経路が多様であるため、同じ指示でも毎回少しずつ違うアウトプットを出します。
そして、生成された複数の回答の中から、多数決の原理で最も一貫性のある(最も多く出現した)答えを最終的な回答として採用します。
これにより、単一の思考プロセスで偶然生じた誤りを排除し、より頑健で信頼性の高い結果を得ることが可能になります。
「SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS」でその詳細が述べられています。
【複雑な問題解決】Tree of Thoughts (ToT)
Tree of Thoughts (ToT)は、CoTが一本道の直線的な思考プロセスであるのに対し、思考を木構造(ツリー状)に分岐させながら進める、より高度な問題解決手法です。
人間の思考プロセスが、ある時点で複数の選択肢を考え、それぞれを評価し、有望な方向に進むことに着想を得ています。
ToTでは、LLMは思考の各ステップで複数の可能性を生成し、それらの有効性を自己評価し、有望な思考の「枝」を伸ばしていきます。
この探索的なプロセスにより、CoTでは解くことが難しい、計画立案や戦略的思考を要する複雑な問題にも対応できるようになります。
「Tree of Thoughts: Deliberate Problem Solving with Large Language Models」で提案され、LLMの自律的な問題解決能力を新たなレベルに引き上げました。
【外部知識の活用】Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG)は、LLMが元々持っている内部知識の限界を克服するための技術です。
LLMの知識は学習データに含まれる情報に限定されるため、最新の情報や、特定の企業内ドキュメントのような非公開情報にはアクセスできません。
RAGは、ユーザーからの質問に関連する情報を、まず外部のデータベースや文書群から検索(Retrieval)し、得られた情報をプロンプトに埋め込んでLLMに渡します。
LLMはその情報をもとに回答を生成(Generation)します。
これにより、LLMは最新かつ正確な情報に基づいた回答を生成できるようになり、誤った情報を生成する「ハルシネーション」を大幅に抑制することができます。
こちらは、RAGで活用できる具体的なプロンプトの作成方法を解説した記事です。あわせてご覧ください。
論文を読む上で知っておきたい知識
プロンプトエンジニアリングの論文を読み解くには、いくつかの専門的な知識が必要です。
特に、LLMの性能をどのように測るかという「評価指標」と、その評価をAI自身が行う「LLM-as-a-Judge」という概念は頻繁に登場するため、押さえておきましょう。
論文で使われる評価指標とベンチマーク
論文を読む際には、どのようなベンチマークで、どの指標が向上したのかを確認することが、その手法の価値を理解する上で重要になります。
論文では、提案された新しい手法が既存の手法と比べてどれだけ優れているかを客観的に示すために、標準化されたデータセット(ベンチマーク)と評価指標が用いられます。
例えば、高校レベルの数学、物理、歴史など57のタスクをカバーする「MMLU (Massive Multitask Language Understanding)」や、小学校レベルの算数文章問題を解く能力を測る「GSM8K」などが有名です。
こちらは、様々なLLMのMMLUスコアを比較できるリーダーボードです。あわせてご覧ください。 https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
これらのベンチマークにおける正答率(Accuracy)を比較することで、モデルの汎用的な知識や推論能力を評価します。
LLM-as-a-Judge:LLM自身が評価を行う手法
「LLM-as-a-Judge」は、高性能なLLMを審査員として用いることで、創造的な文章など正解のないタスクの評価を自動化・効率化する手法です。
従来、AIの生成した文章の品質評価は、人間が採点するか、特定の正解と比較することで行われてきました。
しかし、創造的な文章や要約など、唯一の正解が存在しないタスクの評価は困難でした。
そこで登場したのが「LLM-as-a-Judge」という考え方です。
評価基準をプロンプトで与えることで、LLMは人間のように多角的な観点から採点を行うことができます。
この手法により、大規模な評価を自動化し、迅速かつ低コストで実験を繰り返すことが可能になり、研究のスピードを加速させています。
プロンプトエンジニアリングが抱える課題と今後の展望
プロンプトエンジニアリングは急速に発展していますが、同時に解決すべき課題も多く残されています。
これらの課題を理解することは、技術の限界を知り、今後の発展の方向性を予測する上で非常に重要です。
ハルシネーション(情報の捏造)をどう乗り越えるか
ハルシネーションとは、LLMが事実に基づかない、もっともらしい嘘の情報を生成してしまう現象です。
これは、LLMが単語の確率的な繋がりから文章を生成しているだけで、情報の真偽を判断する能力を持たないために起こります。
プロンプトエンジニアリングの分野では、この課題を克服するために様々なアプローチが研究されています。
前述したRAG(Retrieval-Augmented Generation)は、外部の信頼できる情報源を参照させることでハルシネーションを抑制する代表的な手法です。
また、生成された情報に対する根拠を明示させるようなプロンプトの工夫も、有効な対策の一つとして研究が進められています。
こちらは、AIのハルシネーションを防ぐ具体的な方法について解説した記事です。あわせてご覧ください。
プロンプトインジェクションなどのセキュリティリスク
プロンプトインジェクションは、悪意のあるユーザーが巧妙なプロンプトを入力することで、開発者が意図しない動作をLLMに引き起こさせる攻撃手法です。
例えば、本来は公開してはならない情報を漏洩させたり、不適切なコンテンツを生成させたりすることが可能になります。
これは、LLMを利用したアプリケーションにおける重大なセキュリティリスクとなります。
対策として、入力されるプロンプトを検査して悪意のある指示を検出するフィルタリング技術や、LLMが守るべきルールをより強固に設定する手法などが研究されていますが、完全な防御策はまだ確立されておらず、今後の重要な研究課題となっています。
こちらは、セキュリティの専門機関であるOWASPが解説する、LLMにおけるプロンプトインジェクションのリスクと対策です。あわせてご覧ください。 https://owasp.org/www-project-top-10-for-large-language-model-applications/Archive/0_1_vulns/Prompt_Injection.html
AIのバイアスと公平性の問題
LLMは学習データに含まれる人間の偏見により差別的な出力を生む可能性があるため、公平性を担保するプロンプト設計やチェック手法が不可欠です。
LLMの学習データには、インターネット上に存在する膨大なテキストが使われていますが、そこには人間の持つ偏見(バイアス)も含まれています。
そのため、LLMは特定の性別、人種、職業などに対して、意図せず差別的・偏見に満ちた文章を生成してしまう可能性があります。
このAIのバイアス問題は、社会的な公平性を損なう深刻な課題です。
プロンプトエンジニアリングの観点からは、バイアスを助長しないような中立的なプロンプトを設計する研究や、生成されたアウトプットにバイアスが含まれていないかをチェックし、修正を促すようなプロンプト手法が検討されています。
AIを社会に実装していく上で、公平性をいかに担保するかは避けては通れないテーマです。
こちらは、総務省が公開しているAI開発における公平性の確保などについて言及したガイドラインです。あわせてご覧ください。 https://www.soumu.go.jp/main_content/000624438.pdf
プロンプト作成は自動化の時代へ
手動で最適なプロンプトを探求するのには限界があります。
そのため、近年ではプロンプトの設計プロセス自体を自動化・最適化する研究が活発に進められています。
これにより、人間が思いつかないような、より高性能なプロンプトを発見できる可能性が期待されています。
こちらは、ChatGPTを使ってプロンプトを自動生成する具体的な手法を解説した記事です。あわせてご覧ください。
Automatic Prompt Engineer (APE) とは
Automatic Prompt Engineer (APE) は、その名の通り、プロンプトを自動で生成・最適化する技術です。
この手法では、まず人間がいくつかの入出力例(デモンストレーション)を用意します。
すると、APEは大規模言語モデル(LLM)自身に「これらの例を解決できるような、良い指示文(プロンプト)を考えてください」と依頼します。
LLMは複数のプロンプト候補を生成し、それらの候補を実際にタスクで評価します。
そして、最も性能が良かったプロンプトを最終的な成果物として選択します。
このように、LLMを使ってLLMのためのプロンプトを生成するというメタ的なアプローチにより、プロンプト設計の効率と質を大幅に向上させることができます。
強化学習を用いたプロンプトチューニング
強化学習は、AIエージェントが試行錯誤を通じて、報酬が最大化されるような行動を学習する手法です。
この枠組みをプロンプトの最適化に応用する研究も進んでいます。
具体的には、プロンプトを少しずつ変化させ、その結果としてLLMのアウトプットが改善されたか(報酬が得られたか)を評価します。
このプロセスを繰り返すことで、タスクの性能を最大化するようなプロンプトへと自動的にチューニングしていくのです。
特に、人間からのフィードバックを報酬として利用するRLHF (Reinforcement Learning from Human Feedback) は、ChatGPTなどの対話型AIの性能向上に大きく貢献した技術として知られており、プロンプトの最適化にも応用が期待されています。
こちらは、ChatGPTの性能を飛躍させた強化学習の手法「RLHF」の仕組みについて、図解で分かりやすく解説した記事です。あわせてご覧ください。 https://huggingface.co/blog/ja/rlhf
忙しい人向け!サーベイ論文(レビュー論文)で効率的に最新動向を掴む
日々発表される膨大な数の論文を一つ一つ追いかけるのは、時間的に非常に困難です。
そこでおすすめなのが、特定のテーマに関する研究動向をまとめた「サーベイ論文(レビュー論文)」を活用することです。
サーベイ論文を読むメリット
サーベイ論文を一読するだけで、その分野の全体像を短時間で効率的に把握することができます。
サーベイ論文は、ある研究分野の第一人者が、その分野の歴史、主要な技術、最新の動向、そして今後の課題などを体系的に整理して解説してくれる論文です。
個別の技術論文を読む前に、まず関連するサーベイ論文に目を通すことで、前提知識が整理され、個々の論文の位置付けや重要性を理解しやすくなるという大きなメリットがあります。
特に、プロンプトエンジニアリングのような発展の速い分野では、定期的に発行されるサーベイ論文が知識をアップデートするための羅針盤となります。
代表的なサーベイ論文と読み解くポイント
サーベイ論文は効率的に読み進め、技術の分類や今後の課題に注目することで、研究の全体像やトレンドを把握できることが重要です。
本記事の論文リストにもいくつか含まれていますが、「A Survey of Large Language Models」や「Reasoning with Language Model Prompting: A Survey」などは、プロンプトエンジニアリングの分野で特に評価の高いサーベイ論文です。
サーベイ論文を読む際には、まずアブストラクト(要旨)とイントロダクション(序論)で論文全体の構成と目的を掴みます。
次に、目次を見て、自分が特に関心のある章から読み進めるのも効率的な方法です。
論文の中でどのような技術がどのように分類されているか、そして「Future Work(今後の課題)」として何が挙げられているかに注目すると、研究のトレンドや将来性を理解する上で非常に役立ちます。
論文は難しい?その他の学習方法
論文を読むことは非常に有益ですが、専門性が高く、誰もがすぐに読みこなせるわけではありません。
論文と並行して、あるいはその前段階として、よりアクセスしやすい方法で学習を進めることも重要です。
体系的な学習方法として、プロンプト研修の受講も有効です。こちらは、おすすめの生成AIプロンプト研修をまとめた記事です。あわせてご覧ください。
書籍や技術ブログで知識を補完する
論文の内容を噛み砕いて分かりやすく解説している書籍や技術ブログは、非常に優れた学習リソースです。
特に、第一線で活躍する研究者やエンジニアが執筆したブログは、論文の背景知識や行間を埋める貴重な情報を提供してくれます。
日本語で読める質の高いコンテンツも増えてきており、まずはこうした媒体で基礎知識を固め、興味を持った分野の元論文に挑戦するという学習フローが効果的です。
書籍は、体系的に知識を整理する上で役立ち、手元に置いて何度も参照することができます。
オンラインコースやチュートリアルで実践力を養う
知識をインプットするだけでなく、実際に手を動かしてプロンプトを作成し、その効果を試すこともスキル習得には不可欠です。
CourseraやUdemyなどのプラットフォームでは、プロンプトエンジニアリングに特化した質の高いオンラインコースが提供されています。
動画教材や演習課題を通じて、理論と実践を結びつけながら学ぶことができます。
また、OpenAIやGoogleなどが提供する公式のドキュメントやチュートリアルも、最新かつ正確な情報を基に実践的なスキルを身につけるための最良の教材の一つです。
コミュニティや勉強会で情報交換する
一人での学習は疑問やモチベーションの維持が難しいため、仲間と繋がれる技術コミュニティや勉強会への参加が有効です。
SNSやイベントプラットフォームで検索すれば、プロンプトエンジニアリングに関するコミュニティが数多く見つかります。
他者の知見に触れたり、自分の疑問をぶつけたりすることで、新たな発見や深い理解に繋がります。
また、最新の論文情報やトレンドについても、こうした場を通じて効率的にキャッチアップすることが可能です。
あなたのプロンプト、実は時代遅れ?論文を読まずに損している人の3つの特徴
プロンプトエンジニアリングのテクニックをブログやSNSで学んでいるあなた、その知識だけで本当に十分でしょうか。実は、その情報の多くは、数ヶ月前、あるいは一年以上前の論文から生まれた二次情報に過ぎません。最先端の現場では、次々と新しい技術が生まれており、気づかぬうちにあなたのスキルは時代遅れになっているかもしれません。ここでは、AI研究の一次情報である論文を読まないことで生じる、3つの見過ごせないリスクについて解説します。
一つ目は、技術の「なぜ」を理解できないことです。ブログ記事などで紹介されるテクニックは、いわば料理のレシピのようなものです。しかし、なぜその手順で美味しくなるのか、という原理を知らなければ、応用は効きません。論文には、その技術が生まれた背景や理論的な根拠が詳細に記されています。この本質的な理解を欠いたままでは、表面的なテクニックをなぞることしかできず、未知の問題に直面した際に行き詰まってしまうでしょう。
二つ目は、技術の進化の全体像を見失うことです。プロンプトエンジニアリングの技術は、過去の研究の積み重ねの上に成り立っています。例えば、基本的なFew-shotプロンプティングから、思考プロセスを言語化させるChain-of-Thoughtが生まれ、さらに複雑な問題に対応するためにTree of Thoughtsへと発展してきました。論文を体系的に追うことで、こうした技術の繋がりが見え、次にどのような技術が登場するかを予測することさえ可能になります。一次情報に触れずにいると、点と点の知識が繋がらず、技術の大きな流れから取り残されてしまいます。
三つ目は、市場価値のある専門性を証明できないことです。多くの人が手軽な二次情報で学ぶ中、難解な論文を読み解き、その知見を実践に活かせる人材は極めて希少です。技術の原理原則を理解していることは、単なるオペレーターではなく、新たな価値を創造できるエンジニアであることの証となります。論文読解能力は、あなたのスキルを客観的に差別化し、キャリアにおける強力な武器となるのです。
引用元:
大規模言語モデルの能力を最大限に引き出すためには、プロンプトの設計が重要であることは、初期の段階から指摘されている。例を提示することでモデルの性能を向上させるインコンテキスト学習の有効性は、多くの研究の基礎となっている。(Brown, T. B., Mann, B., et al. “Language Models are Few-Shot Learners.” 2020年)
まとめ
企業はプロンプトエンジニアリングに代表される高度なAI技術を活用し、DX推進や業務改善を目指しています。
しかし、実際には「論文を読み解けるような専門人材が社内にいない」「AIの性能を最大限に引き出すプロンプトが作成できない」といった理由で、生成AIの導入や活用に踏み切れない企業も少なくありません。
そこでおすすめしたいのが、Taskhub です。
Taskhubは日本初のアプリ型インターフェースを採用し、200種類以上の実用的なAIタスクをパッケージ化した生成AI活用プラットフォームです。
たとえば、高度なプロンプト知識がなくても、メール作成や議事録作成、画像からの文字起こし、さらにレポート自動生成など、さまざまな業務を「アプリ」として選ぶだけで、誰でも直感的にAIを活用できます。
しかも、Azure OpenAI Serviceを基盤にしているため、データセキュリティが万全で、情報漏えいの心配もありません。
さらに、AIコンサルタントによる手厚い導入サポートがあるため、「何をどう使えばいいのかわからない」という初心者企業でも安心してスタートできます。
導入後すぐに効果を実感できる設計なので、複雑なプログラミングや高度なAI知識がなくても、すぐに業務効率化が図れる点が大きな魅力です。
まずは、Taskhubの活用事例や機能を詳しくまとめた【サービス概要資料】を無料でダウンロードしてください。
Taskhubで“最速の生成AI活用”を体験し、御社のDXを一気に加速させましょう。







